Contadores fiables en entornos concurrentes: evita la deriva de las métricas
Aprende a mantener contadores fiables bajo concurrencia usando actualizaciones atómicas, claves de idempotencia y escrituras por lotes para que las métricas sean precisas en producción.
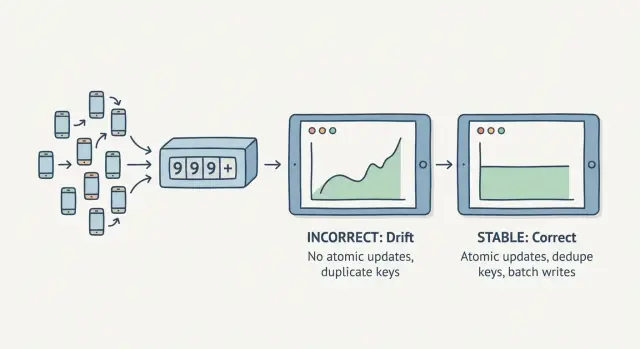
Por qué los contadores derivan cuando el tráfico llega al mismo tiempo
Un contador deriva cuando no puedes confiar en que se mantenga consistente. Actualizas un panel y el total cambia aunque no haya pasado nada nuevo. O el número salta tras un pico breve. Esto es difícil de detectar en pruebas porque normalmente requiere concurrencia real.
La deriva suele verse así:
- El mismo informe muestra totales distintos en cada actualización.
- Los recuentos saltan tras una ráfaga de tráfico o un deploy.
- Los totales en un lugar (base de datos) no coinciden con otro (analíticas).
La causa habitual es una condición de carrera: muchas peticiones intentan actualizar el mismo número al mismo tiempo. Si tu código hace “lee el valor actual, suma 1, escribe de nuevo”, dos peticiones pueden leer ambas 10, sumar 1 y escribir 11. Un incremento desaparece.
Por eso suele aparecer solo después del lanzamiento. En un portátil o en staging tranquilo, las peticiones llegan de una en una. Tras una campaña, una función popular o jobs en paralelo, esas actualizaciones colisionan.
También hay un compromiso entre exactitud y frescura. Actualizar un contador en cada petición puede ser preciso, pero solo si la actualización es realmente segura bajo concurrencia. Muchos equipos optan por casi tiempo real: recopilar eventos rápido y luego actualizar totales en pequeños lotes cada pocos segundos. El número llega con algo de retraso, pero suele ser más estable y más fácil de hacer correcto.
Un ejemplo simple: dos usuarios pulsan “Comprar” en el mismo segundo. Si ambas peticiones calculan y escriben el nuevo total por separado, tu contador de compras puede subcontar aunque ambos pedidos se hayan completado.
Elige el tipo de métrica correcto antes de programar
Muchos “problemas de contadores” son en realidad “problemas de definición”. Si eliges el tipo de métrica equivocado, arreglar el incremento no hará que tus analíticas sean estables.
Cuando alguien dice que quiere “un contador”, normalmente se refiere a uno de estos:
- Contador: cuántas veces ocurrió algo (vistas de página, clics en botones)
- Suma: cantidad total a través de eventos (ingresos, minutos vistos)
- Recuento único: cuántos usuarios/ítems distintos hicieron algo (registros únicos, compradores únicos)
- Tasa: una proporción en el tiempo (registros por hora, tasa de conversión)
Un +1 simple suele estar bien para eventos de bajo riesgo y alto volumen como vistas de página. Un poco de ruido por duplicados normalmente no importa.
Pero en cuanto hay dinero, estado de usuario o mensajería involucrada, necesitas una definición más estricta de “verdad”. Registros, compras, emails de restablecimiento, invitaciones y eventos de “trial iniciado” se reintentran más de lo que se espera (clientes, jobs en segundo plano, proveedores de pagos). Contar reintentos como eventos nuevos es como los dashboards se inflan.
Una forma práctica de decidir es elegir tu fuente de la verdad:
- Eventos append-only: almacena cada evento una vez y luego calcula totales a partir de esos eventos.
- Totales almacenados: guarda un número acumulado y actualízalo según suceden eventos.
Los logs de eventos son más fáciles de auditar y recalcular. Los totales almacenados son más rápidos de leer, pero solo funcionan si las actualizaciones son correctas y se bloquean los duplicados.
Ejemplo: un checkout recibe payment_succeeded dos veces porque la primera respuesta al webhook se quedó sin respuesta. Si tu métrica de “compras” es un contador simple, salta en 2. Si tu verdad es “una compra por payment_id”, mides payment IDs únicos, no entregas de webhook en bruto.
Actualizaciones atómicas: la forma más segura de incrementar
Cuando necesitas contadores fiables bajo concurrencia, usa actualizaciones atómicas. “Atómico” significa que el cambio ocurre como una sola operación: se aplica una vez, o no se aplica. Sin estados parciales ni dos peticiones sobrescribiéndose.
El bug clásico es leer-modificar-escribir: leer 100, sumar 1 en el código de la app, escribir 101. Dos peticiones pueden leer 100 y las dos escribir 101.
Las actualizaciones atómicas hacen el incremento dentro de la base de datos o del store, donde puede aplicarse de forma segura incluso cuando llegan muchas peticiones a la vez:
UPDATE counters
SET value = value + 1
WHERE name = 'signups';
INCR signups
Una comprobación rápida: si tu app lee el valor del contador solo para incrementarlo, probablemente estás de nuevo en territorio de leer-modificar-escribir.
Los incrementos atómicos no son gratuitos. Si una sola fila/clave se actualiza constantemente (una “hot key” como un contador global de pageviews), puedes encontrarte con:
- Contención de locks o actualizaciones más lentas
- Mayor latencia durante picos
- Retraso de replicación si lees de réplicas
- Timeouts que disparan reintentos
Claves de deduplicación: evita el doble conteo por reintentos y replays
Idempotencia significa que enviar la misma acción dos veces tiene el mismo efecto que enviarla una vez. Para contadores, es la diferencia entre “más o menos correcto” y confiable.
Los duplicados son comunes:
- Un usuario hace doble clic en “Pagar ahora”.
- Un cliente móvil pierde conexión y reintenta.
- Un proveedor de webhooks reenvía tras un 500.
- Una cola vuelve a entregar un job.
Una clave de dedupe suele ser un event_id que identifica de forma única el evento del mundo real que contabilizas. Puede venir de un ID del proveedor, un UUID generado por el cliente, un ID generado por el servidor o una clave determinista realmente única como order_id + event_type.
Una vez que tienes event_id, guárdalo y rehúsa contabilizar el mismo dos veces. La regla básica es: inserta el event_id primero, luego incrementa, o haz ambas cosas en una sola transacción.
Opciones comunes de almacenamiento:
- Una tabla en la base de datos de eventos procesados con una restricción UNIQUE en
event_id - Un índice UNIQUE en tu tabla de analytics/eventos
- Una caché (como Redis) con TTL para ventanas de dedupe de corta duración
Ejemplo: llega un webhook de compra y tu handler hace timeout; el proveedor lo reenvía. Sin dedupe, registras dos compras e incrementas ingresos dos veces. Con un event_id único, el segundo intento se convierte en no-op.
Escrituras por lotes: menos llamadas a la base y analíticas más estables
Bajo carga, las escrituras de una sola fila pueden acumularse. Eso aumenta el tiempo de lock, ralentiza respuestas y eleva la probabilidad de timeouts o fallos parciales. El batching reduce viajes a la base de datos y puede hacer que las analíticas sean más estables.
Un modelo mental simple: captura eventos rápido y escribe resúmenes en menos actualizaciones más grandes. Enfoques comunes incluyen acumular y volcar cada N segundos, encolar eventos y agregarlos en workers, rollups programados (horarios/diarios) o un híbrido (contadores pequeños en tiempo real más backfills periódicos).
La contrapartida es la frescura. Tu panel puede retrasarse segundos o minutos, pero por lo general verás menos escrituras fallidas y menos picos causados por tormentas de reintentos.
Elige la ventana de lote según el uso de la métrica:
- Segundos: feeds en vivo, limitación de tasa, widgets de “activo ahora”
- Decenas de segundos: dashboards de marketing y embudos de registro
- Minutos: ingresos y la mayoría de reportes de administración
- Horas/días: reportes financieros y auditorías
Un patrón seguro para contadores y analíticas
Trata cada incremento como resultado de un evento específico. El contador es solo un resumen.
Un patrón que resiste la carga:
-
Nombra el evento y elige un id único estable. Usa algo que permanezca igual a través de reintentos (por ejemplo:
order_id,payment_intent_ido unevent_idgenerado que se propaga por el flujo). -
Registra el evento (o una fila ligera de dedupe) primero. Almacena el id en una tabla
eventsodedupecon restricción única. -
Incrementa con una actualización atómica. Usa una sentencia de incremento única, no “leer, sumar, escribir”. Si puedes, mantén la escritura del evento y la actualización del contador en una transacción.
-
Haz que los reintentos sean seguros. Si la inserción de dedupe falla porque la clave ya existe, trátalo como éxito y salta el incremento.
-
Haz batching cuando tenga sentido, sin romper las reglas. Bufferiza incrementos y vacía periódicamente, pero solo después de que el registro del evento/dedupe esté almacenado de forma segura.
Ejemplo: un usuario pulsa “Comprar”, tu servidor crea un evento purchase_completed con clave de dedupe order_123. Si el proveedor de pagos reintenta el webhook, la segunda inserción choca con la restricción única y no sumas una segunda compra.
Reintentos, timeouts y colas de mensajes sin inflar los contadores
Muchos sistemas entregan eventos con garantía “at-least-once”. En claro: el mismo mensaje puede aparecer dos veces.
Los timeouts son la versión más sigilosa. Un cliente llama a tu API, espera, hace timeout y reintenta. Pero el servidor puede haber terminado y haber hecho commit de la actualización del contador. Ahora tienes dos intentos “exitosos” para una acción real.
La regla: solo reintenta trabajo que sea idempotente.
Un patrón práctico de cola:
- La API crea un evento con un
event_idúnico (por ejemplo,purchase-\u003corder_id\u003e) y lo encola. - Un worker procesa el evento y escribe dos cosas en una transacción: (1) marca
event_idcomo procesado, (2) incrementa el contador. - Si el mensaje se redelivra, el worker ve que
event_idya está procesado y se salta el incremento.
Para depurar incidentes, mantén logs simples y consistentes:
event_id- timestamps (recibido y committed)
- origen (API, cola, cron)
- resultado (procesado, saltado como duplicado, fallido)
- contador de reintentos
Errores comunes que causan deriva en métricas
Estos problemas se repiten entre productos.
Error 1: Leer y luego escribir incrementos
Dos peticiones pueden leer el mismo valor y escribir el mismo nuevo valor. Usa un incremento atómico en la base de datos para que la actualización ocurra en una operación.
Error 2: Contar antes de que la acción realmente tenga éxito
Si incrementas cuando empieza la petición, sobrará conteo cuando la acción falle después (pago rechazado, envío de email fallido, transacción revertida). Cuenta después de tener una señal de éxito real.
Error 3: Claves de dedupe sin enforcement
Una clave de dedupe solo funciona si aplicas unicidad a nivel de base de datos (constraint/index UNIQUE). Sin eso, los duplicados siguen filtrándose bajo reintentos y workers paralelos.
Error 4: Escrituras por lotes que pierden datos
El batching reduce carga, pero los buffers en memoria pueden desaparecer en reinicios. Haz explícito el comportamiento de flush: flush por tiempo, por tamaño y un flush en shutdown.
Error 5: Límites de día rotos en rollups
Las métricas diarias derivan cuando servicios no coinciden en zonas horarias o límites de día. Elige un estándar (a menudo UTC), almacena timestamps de forma consistente y conserva eventos crudos el tiempo suficiente para recomputar rollups.
Comprobaciones rápidas para verificar que tus contadores son confiables
Si no puedes explicar un incremento, no puedes probar que sea correcto. Incluso una tabla simple de eventos crudos basta para hacer comprobaciones puntuales.
Un escaneo de sanidad rápido:
- ¿Puedes rastrear cada incremento hasta un
event_idalmacenado con el evento crudo? - ¿Haces cumplir unicidad para claves de dedupe (índice/constraint UNIQUE)?
- ¿Se actualizan los contadores con actualizaciones atómicas (una sola sentencia), no con leer-modificar-escribir en código de la app?
- ¿Reconcilias totales contra eventos crudos (aunque sea una comprobación diaria)?
- ¿Alertas ante reseteos súbitos o saltos inusualmente grandes?
Una prueba práctica: elige una métrica como “nuevos registros”, extrae 50 event_id recientes y verifica que cada uno mapea exactamente a un incremento. Luego reenvía la misma petición/mensaje varias veces y confirma que el contador no cambia.
Ejemplo: arreglando contadores de registro y compra en una app real
Una pequeña app de suscripciones rastrea registros, compras y “email de bienvenida enviado”. Durante semanas el panel parece bien. Luego crece el tráfico y soporte empieza a oír “Me cobraron dos veces” o “Pulsé una vez”. Los totales se alejan de los reportes de pagos.
Qué ocurre: doble clics, reintentos de cliente tras timeouts y webhooks de pago reemitidos. Si tu código incrementa primero y pregunta después, las métricas derivan.
Una corrección estable combina tres movimientos:
- Dedupe por acción:
signup:\u003cuser_id\u003e,purchase:\u003cpayment_event_id\u003e,email:\u003cmessage_id\u003e, almacenadas con constraint UNIQUE. - Incrementos atómicos: reemplaza leer-modificar-escribir por un incremento único en base de datos.
- Batch para actualizaciones de alto volumen: deja en tiempo real lo que necesites y agrupa lo demás.
Un plan de rollout simple:
- Reproduce la misma carga útil de webhook 5–10 veces en staging y confirma que los contadores no cambian después del primero.
- Lanza detrás de un feature flag y actívalo para un pequeño porcentaje de tráfico.
- Ejecuta un job de reconciliación para comparar eventos crudos vs contadores y rellenar diferencias.
- Monitoriza “golpes de dedupe” para confirmar que los reintentos se están capturando.
Siguientes pasos: estabiliza métricas sin reescribir todo
Normalmente no necesitas una reconstrucción completa. Necesitas un mapa claro de dónde se crean los conteos, dónde pueden ocurrir reintentos y dónde se cuelan duplicados.
Empieza con un inventario básico:
- Dónde vive cada contador (base de datos, caché, herramienta de analytics)
- Dónde se originan los eventos (endpoints, jobs en background, webhooks)
- Cada ruta de reintento (reintentos del cliente, reintentos de cola, redelivery de webhooks)
- Cómo identificas un evento (
event_id,request_id,order_id) - Dónde se escriben los datos (un solo lugar vs muchos)
Luego arregla en este orden:
- Evita el doble conteo (claves de dedupe e idempotencia en los caminos más calientes)
- Haz los incrementos atómicos
- Mejora el rendimiento (batching, procesamiento asíncrono)
- Añade comprobaciones continuas (reconciliar eventos crudos vs contadores, alertas por saltos extraños)
Si heredaste una base de código generada por IA, asume que la lógica de contadores fue copiada y aplicada ligeramente distinta en varios sitios. Unificar esas rutas en una función o servicio compartido suele ser la forma más rápida de que las correcciones se mantengan.
Si quieres una segunda opinión, FixMyMess (fixmymess.ai) se centra en diagnosticar y reparar problemas como actualizaciones no atómicas, falta de idempotencia y webhooks sensibles a replays en apps generadas por IA. Una auditoría de código gratuita puede resaltar rápidamente los pocos puntos que causan la mayor deriva bajo tráfico real.