Convierte la retroalimentación de usuarios en una lista de correcciones que el equipo pueda enviar
Aprende a convertir la retroalimentación de usuarios en una lista de correcciones reproducibles: extrae pasos, etiqueta impacto y decide qué arreglar primero sin suposiciones.
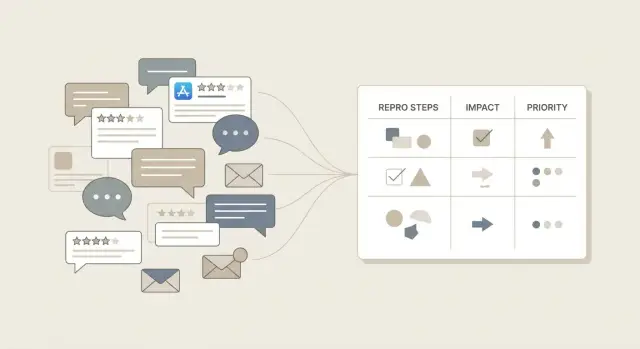
Por qué las quejas vagas frenan las correcciones
"No funciona" señala un dolor, pero no es un informe de error. Un equipo no puede arreglar algo que no puede reproducir, y no puede confirmar una solución sin un claro antes y después.
La retroalimentación vaga suele eliminar los detalles que importan: qué intentó la persona, qué esperaba, qué ocurrió realmente y qué cambió recientemente. También difumina los límites. ¿Es un botón, un tipo de cuenta, un dispositivo o todo el producto?
Los reportes poco claros ralentizan todo y hacen que las correcciones sean riesgosas. Los ingenieros adivinan, parchean la cosa equivocada y envían cambios que rompen otra parte. Los equipos de producto no pueden comparar issues consistentemente, así que gana la queja más ruidosa en lugar de la más importante.
Una buena lista de correcciones es lo opuesto a lo vago. Está compuesta por ítems pequeños y comprobables que cualquiera del equipo puede seguir y confirmar. Cada elemento debe leerse como un pequeño experimento con pase/fallo claro.
"Enviable" suele significar:
- Un problema por ítem (nada de paquetes como "el checkout está roto")
- Un título corto que nombre la pantalla y la acción
- Pasos de reproducción que un compañero pueda seguir en menos de 2 minutos
- Resultado esperado vs resultado real
- Una comprobación simple de éxito que pruebe que está arreglado
Si trabajas con una app generada por IA, las quejas vagas cuestan aún más. Lógicas frágiles, secretos expuestos y flujos enredados pueden esconderse tras los síntomas. Ser específico desde el principio mantiene la corrección pequeña, más segura de enviar y más rápida de verificar.
Captura la retroalimentación en un solo lugar (sin perder contexto)
Si la retroalimentación vive en cinco sitios, las correcciones se vuelven lentas y desordenadas. Elige un hogar para cada reporte (una hoja de cálculo, un doc compartido o un tracker) y trátalo como la fuente de la verdad. El objetivo es preservar lo que el usuario quiso decir mientras lo haces útil para el equipo.
Empieza recogiendo el mensaje original de donde llegue: correos de soporte, DMs (fundador, ventas, comunidad), reseñas en tiendas de apps, transcripciones de chat en la app y notas de llamadas de demos o onboarding.
No reescribas la queja como primer paso. Copia el texto original en el registro, incluyendo capturas, marcas temporales y cualquier detalle que compartieron (plan, dispositivo, tipo de cuenta). Luego añade estructura en campos separados (como área, severidad y causa sospechada). Esa separación te mantiene honesto: las palabras del usuario quedan intactas, pero tu equipo obtiene datos organizados.
Asigna a cada reporte un ID único (aunque sea FDBK-00123). El ID sigue al issue a través de duplicados, comentarios y correcciones, así podrás fusionar reportes en lugar de crear cinco tareas por el mismo bug.
Antes de escribir tareas, agrupa quejas similares. "El login se queda en bucle", "no puedo mantener la sesión" y "auth falla aleatoriamente" pueden ser un cluster con múltiples ejemplos. Cuando un prototipo falla en producción, los equipos suelen empezar aquí: junta los reportes crudos primero y luego diagnostica patrones. (Así es como FixMyMess normalmente comienza con apps generadas por IA: recopilar todo y luego investigar los puntos de fallo comunes.)
Mantén también un pequeño cubo de "desconocido". Cuando un mensaje es demasiado vago, regístralo igual y anota lo que falta (dispositivo, pasos, tipo de cuenta). No se perderá y podrás hacer seguimiento cuando tengas tiempo.
Traduce las quejas en hechos útiles
Una queja como "está roto" normalmente apunta a un problema real, pero aun así no te dice qué arreglar. Tu trabajo es convertir la emoción en un conjunto corto de hechos que un compañero pueda ejecutar.
Empieza por quién es el usuario. Un usuario nuevo puede quedarse atascado en el onboarding; uno recurrente puede estar bloqueado por un cambio reciente. Rol y plan también importan: un admin puede ver pantallas que un usuario básico nunca verá. El dispositivo suele ser la pista oculta, especialmente cuando un flujo funciona en desktop pero falla en móvil.
A continuación, define la meta. ¿Qué intentaba hacer justo antes de que fallara? Luego reescribe el problema central como esperado vs actual en una frase. Ejemplo: "Esperaba que el checkout confirmara el pago, pero se queda girando para siempre después de pulsar Pagar." Esa línea se convierte en el ancla del ticket.
Los patrones temporales son un atajo al root cause. "Siempre" sugiere un bug determinista. "A veces" apunta a temporización, red, condiciones de carrera o casos borde. "Solo la primera vez" suele implicar caché, permisos o estado de cuenta.
Captura detalles del entorno, pero solo los que ayudan a reproducir:
- Tipo y rol de usuario (nuevo o recurrente, admin o miembro, plan)
- Objetivo del usuario (el resultado que quería)
- Esperado vs actual (una frase)
- Frecuencia (siempre, a veces, solo en el primer intento)
- Entorno (navegador, SO, versión de la app y estado de cuenta como prueba, invitado o 2FA activado)
Si trabajas con una app construida con IA que cambia rápido, añade un dato más: en qué build o despliegue estaban. La misma queja puede referirse a bugs distintos con dos días de diferencia.
Paso a paso: convierte un mensaje en pasos reproducibles
Cuando alguien dice "Tu app está rota", trátalo como materia prima. Tu trabajo es convertirlo en algo que un compañero pueda seguir sin adivinar.
1) Titúlalo con el resultado
Escribe un título de una línea que nombre lo que falló para el usuario, no tu teoría sobre por qué.
Bueno: "El botón de checkout no hace nada tras introducir un código promocional."
No: "Bug del código promocional."
2) Captura la ruta más corta (3-7 pasos)
Los pasos de reproducción deben ser la ruta mínima desde un inicio limpio hasta el problema. Si un detalle de setup importa (por ejemplo, estar desconectado), indícalo al principio.
Estructura simple:
- Estado inicial: dispositivo/navegador, tipo de cuenta, conectado o no
- Pasos 1-7: los clics mínimos para llegar al issue
- Detente en el momento en que aparece el bug
3) Añade entradas exactas
Sustituye "Llené el formulario" por campos, botones y valores exactos.
Ejemplo: "Correo electrónico: [email protected]", "Contraseña: 8+ chars", "Pulsado: Create account".
Aquí es donde la mayoría de quejas vagas se vuelven accionables.
4) Escribe esperado vs actual
Dos líneas cortas:
Esperado: lo que debería suceder.
Real: lo que pasó en su lugar (incluye el texto exacto del mensaje de error si lo hay).
5) Define "hecho" como pase/fallo
Haz que la finalización sea incontrovertible. "Hecho cuando un usuario nuevo puede enviar el formulario 5 veces seguidas sin error en Chrome y Safari." Si no puede probarse, no puede cerrarse.
6) Añade evidencia si la tienes
Capturas, grabaciones de pantalla, logs de consola y marcas temporales ayudan. Si la app es generada por IA y está desordenada, la evidencia importa aún más. Equipos como FixMyMess suelen usar este material durante una auditoría de código gratuita para diagnosticar flujos rotos rápidamente.
Preguntas simples que aclaran rápido
Cuando un usuario dice "está roto", normalmente describe un momento, no un reporte completo. Pregunta solo lo necesario para reproducirlo una vez.
Llévalos de vuelta al punto exacto de fallo. Un pequeño detalle (el último clic, un valor pegado, el texto del error) puede ahorrar horas de adivinanza, especialmente en apps generadas por IA donde pequeños huecos lógicos se esconden detrás de "ayer funcionaba".
Cinco preguntas que aclaran la mayoría de los reportes en menos de dos minutos:
- ¿Cuál fue la última cosa que hiciste justo antes de que fallara?
- ¿Qué exactamente clicaste y qué escribiste? Si puedes, copia/pega lo que ingresaste.
- ¿Qué esperabas que pasara y qué pasó en su lugar?
- ¿Viste algún mensaje de error? Comparte el texto exacto.
- ¿Funciona en otro navegador o dispositivo (una comprobación rápida)?
Tras lo básico, pregunta una cuestión de negocio para triage: "¿Qué tan urgente es esto y qué intentabas lograr?" Alguien intentando enviar un pago es distinto a quien cambia una foto de perfil.
Ejemplo:
"El login está roto" se convierte en: "En iPhone Safari, después de introducir email y contraseña y pulsar Iniciar sesión, vuelve a la pantalla de login. Sin texto de error. Funciona en Chrome desktop. Urgente porque no puedo acceder a mi cuenta."
Eso es suficiente para pasar de frustración a una lista de correcciones que el equipo pueda enviar.
Etiqueta cada issue para poder comparar manzanas con manzanas
Cuando la retroalimentación se acumula, todo suena urgente. Las etiquetas convierten mensajes desordenados en datos consistentes para que puedas ordenar, agrupar y decidir qué reparar primero sin discutir.
Dale a cada ítem algunas etiquetas simples. Mantén las opciones limitadas para que la gente realmente las use:
- Tipo (bug, funcionalidad faltante, UX confusa, rendimiento, datos)
- Severidad (bloquea la tarea, necesita workaround, molesto pero posible)
- Frecuencia (un usuario, algunos usuarios, la mayoría de usuarios)
- Área afectada (una pantalla, un flujo, muchos flujos)
- Responsable (web, backend, móvil, infra, contenido)
Una semana de etiquetas muestra patrones rápido. Diez items "UX confusa + mayoría de usuarios + muchos flujos" suelen importar más que una queja dramática.
Añade "banderas de riesgo" como un conjunto de etiquetas separado. Manténlo corto pero que destaque:
- Problemas de auth o sesiones
- Pagos o checkout
- Pérdida o corrupción de datos
- Exposición de seguridad (secretos, inyección, permisos)
- Riesgo de cumplimiento o privacidad
Ejemplo: "El login falla continuamente" podría etiquetarse como bug + bloquea tarea + algunos usuarios + muchos flujos + riesgo de auth. Esa línea sola indica que no es solo una molestia de UI. Si manejas un prototipo generado por IA, las banderas de riesgo te ayudan a identificar lo peligroso pronto (autenticación rota, secretos expuestos) antes de gastar tiempo en temas de menor impacto.
Prioriza por impacto en el negocio, no por el más ruidoso
El usuario más ruidoso no siempre señala el problema más importante. Una lista de correcciones útil comienza con impacto: ¿qué le pasa al negocio si esto sigue roto una semana?
Elige 2-3 métricas de impacto que encajen con tu producto y úsalas consistentemente. Opciones comunes: ingresos (checkout bloqueado, upgrades fallidos), retención (usuarios que se van tras toparse con el bug), confianza (seguridad, pérdida de datos, login roto) y carga de soporte (cuántos tickets genera esto).
Ahora puntúa cada issue en lenguaje claro: Alto, Medio o Bajo. Añade una frase explicando por qué: "Alto: impide que nuevos usuarios se registren, afecta ~30% de intentos."
Haz lo mismo con el esfuerzo, pero sé aproximado si aún no lo sabes. Pequeño, Medio, Grande, o un rango como S-M es suficiente. Esto importa aún más para bases de código generadas por IA, donde dimensionar es difícil hasta inspeccionar el código.
Una regla simple te mantiene honesto:
- Alto impacto + Bajo esfuerzo: hacerlo primero
- Alto impacto + Alto esfuerzo: planificar y dividir en pasos
- Bajo impacto + Bajo esfuerzo: hacerlo cuando necesites victorias rápidas
- Bajo impacto + Alto esfuerzo: aparcar o descartar
Separa los items de riesgo "debe arreglarse" de las solicitudes "sería bueno tener". Todo lo relacionado con seguridad, secretos expuestos, auth roto o corrupción de datos es un "debe arreglarse" incluso si pocos usuarios lo notaron. Si necesitas una segunda opinión rápida sobre una app generada por IA, FixMyMess puede auditar y señalar los verdaderos riesgos antes de que dediques una semana a adivinar.
Convierte la lista de correcciones en trabajo enviable
Una lista de fixes solo ayuda si alguien puede cogerla, construirla y decir con confianza "hecho". Aquí las notas se vuelven trabajo real.
Mantén el lote pequeño. Un buen punto de partida son 6-10 items para la semana (o sprint). Con 30 harás cambio de contexto y no enviarás nada. Con 2, probablemente evitas lo difícil.
Para cada ítem, añade los detalles que lo hagan construible:
- Criterios de aceptación: qué podrá hacer el usuario después del fix, en palabras simples ("El usuario puede restablecer la contraseña y recibir el correo en 2 minutos.")
- Responsable y ventana: una persona responsable y un plazo aproximado ("para el mié", "esta semana")
- Dependencias: qué toca (auth, base de datos, proveedor de pagos, servicio de email)
- Cómo confirmarás: volver a ejecutar pasos de reproducción, observar una métrica o recibir respuesta del usuario que reportó
- Nota de alcance: qué no harás en esta pasada, para que la corrección no se infle
Ejemplo: "El login falla" se convierte en: "Arreglar loop de redirect de auth en mobile Safari. Hecho cuando un usuario nuevo puede registrarse, verificar email y llegar al dashboard en iPhone. Responsable: Sam. Fecha: vie. Depende de la configuración del proveedor de auth y de cookies de sesión. Confirmar: ejecutar los pasos de repro y vigilar la tasa de error de login durante 24 h."
Si la base de código es generada por IA y frágil (auth enredada, secretos expuestos, acceso a BD raro), los equipos suelen pasar más tiempo adivinando que arreglando. Un diagnóstico externo rápido como la auditoría gratuita de FixMyMess puede convertir un backlog borroso en tareas que realmente puedas enviar en 48-72 horas.
Ejemplo: de un mensaje enfadado a un plan de corrección claro
Mensaje del usuario: "El login está roto y me cobraron. Arregladlo." Suena urgente, pero sigue sin ser accionable. Extrae los hechos sin discutir y escribe una prueba que cualquiera del equipo pueda ejecutar.
Extrae lo que ya tienes:
- Quién: cliente existente vs nuevo, qué plan, qué dispositivo/navegador
- Meta: iniciar sesión para gestionar la cuenta (y evitar cargos duplicados)
- Esperado: login exitoso, facturación acorde al plan, un cargo por periodo
- Real: login falla, se realizó un cobro (o cobro duplicado)
Convierte eso en pasos reproducibles con una prueba de pase/fallo:
- Usa una cuenta de prueba en el mismo plan (o crea una).
- Abre la app en el navegador/dispositivo reportado.
- Intenta iniciar sesión con credenciales correctas.
- Observa el resultado: mensaje de error, loop de redirección, página en blanco.
- Revisa el estado de facturación: ¿se creó un cargo? ¿hay factura duplicada?
Pase: el usuario llega al dashboard y no existe un cargo inesperado.
Fallo: el login bloquea el acceso o la facturación muestra un cargo incorrecto.
Etiquétalo para comparar con otros reportes: riesgo en pagos (alto), golpe a la confianza (alto), riesgo de churn (alto). La lista de correcciones debe reflejar impacto de negocio, no solo el tono del mensaje.
Una lista priorizada del mismo hilo podría ser:
- Detener cargos incorrectos inmediatamente (desactivar la ruta de facturación problemática o añadir una salvaguarda)
- Arreglar la falla de login (root cause más una prueba para el estado de error exacto)
- Añadir alertas para creación de cargos sin signup/login exitoso
- Mejorar el mensaje de error y la vía de soporte para que los usuarios se recuperen
Si esto viene de una base de código generada por IA con auth enredada o lógica de facturación expuesta, los equipos suelen traer a FixMyMess para una auditoría rápida antes de lanzar cambios.
Errores comunes que hacen perder días
La forma más rápida de perder tiempo es convertir feedback en trabajo que nadie puede verificar. "Arregas" algo, los usuarios siguen insatisfechos y el equipo discute qué cambió.
Una trampa es escribir tickets que describen sentimientos en vez de comportamiento. "La app es inutilizable" es feedback real, pero no es una tarea. Captura el momento que se rompe: qué hizo el usuario, qué vio y qué pasó después.
Otro sumidero de tiempo es el mega-ticket: un reporte que mezcla login, facturación y una pantalla lenta en un solo bulto. Parece eficiente, pero bloquea el progreso porque cada parte necesita distintos responsables, pruebas y prioridad. Divide issues cuando tengan causas distintas o criterios de "hecho" diferentes.
Saltar el resultado esperado es cómo los equipos envían el arreglo equivocado. Si solo escribes lo que falló, alguien puede "arreglarlo" enmascarando un error, cambiando texto o alterando comportamiento que los usuarios no querían. Un buen ticket deja claro el objetivo: cómo debe comportarse.
Los duplicados no son pérdida, son señal. Trátalos como datos de frecuencia. Cierra la copia, vincúlala al original y anota cuántos usuarios lo reportaron. Ese conteo suele ser más útil que otra descripción larga.
Priorizar por quien grita más también hace perder días. Volumen, impacto en ingresos y workflows bloqueados importan más que el tono.
No ignores reportes "raros" que insinúan seguridad o pérdida de datos. Un secreto expuesto, riesgo de inyección SQL o una vía de takeover de cuentas puede valer más que diez quejas menores de UI. Si heredaste código generado por IA, estos problemas son comunes y fáciles de pasar por alto hasta que es demasiado tarde. FixMyMess suele empezar con una auditoría rápida para sacar a la luz problemas de alto riesgo antes de invertir tiempo en bugs de menor impacto.
Lista rápida antes de comprometerte a arreglar
Antes de que alguien empiece a codear, haz una comprobación rápida sobre el propio reporte. Un reporte desordenado genera un arreglo desordenado. Uno limpio es fácil de estimar, asignar y verificar.
Usa esto para decidir si el issue está listo para trabajar o necesita una ronda más de preguntas:
- ¿Puede otra persona reproducirlo usando solo los pasos que escribiste (en una cuenta nueva, en un navegador normal)?
- ¿Está el esperado vs actual en palabras claras, con la pantalla o acción exacta donde falla?
- ¿Sabes a quién afecta y con qué frecuencia (un cliente, un segmento o la mayoría; siempre o solo a veces)?
- ¿Está el impacto de negocio capturado en una línea ("nuevos usuarios no pueden registrarse" o "checkout falla en móvil")?
- ¿La comprobación de éxito es clara: qué prueba exactamente que está arreglado?
Finalmente, busca issues que deberían saltar la fila. Si hay posibilidad de que involucre seguridad, autenticación o pagos, escálalo. Ejemplos: secretos expuestos, bypass de login, takeover de cuentas, cargos duplicados, recibos faltantes.
Si heredaste un prototipo generado por IA y los reportes siguen fallando esta lista (flujos poco claros, comportamiento inconsistente, bugs raros de auth), puede ser más rápido hacer una auditoría de código primero. Equipos como FixMyMess lo hacen de forma focalizada para que sepas qué está realmente roto antes de comprometer tiempo en arreglos.
Siguientes pasos (y cuándo traer ayuda)
Una vez que puedas convertir la retroalimentación de usuarios en una lista clara de correcciones, protege ese progreso manteniendo el alcance pequeño. Empieza con los cinco problemas principales por impacto de negocio (registros perdidos, pagos fallidos, login bloqueado, pérdida de datos, flujos centrales rotos). Para cada uno, escribe pasos de repro limpios para que cualquiera del equipo pueda verificar el bug de la misma manera.
Un ritmo simple evita que el backlog se pudra: un triage corto semanal. Que dure 20-30 minutos, decide qué avanza y cierra o aparca lo demás.
Un plan práctico para los próximos 7 días:
- Elige los 5 principales por impacto y reescribe cada uno en pasos de repro claros y esperado vs actual.
- Confirma cada issue una vez y deja de re-litigarlo en chat.
- Asigna un responsable y una fecha, aunque sea aproximada.
- Envía correcciones en pequeños lotes para detectar regresiones rápido.
- Tras cada lote, vuelve a ejecutar los pasos de repro originales y marca como hecho solo cuando pasen.
Trae ayuda cuando las mismas correcciones siguen rompiéndose o cuando sigues encontrando problemas sorpresa bajo la superficie. Esto es común en apps generadas por herramientas como Lovable, Bolt, v0, Cursor y Replit, donde lógica oculta, secretos expuestos y agujeros de seguridad pueden estar detrás de lo que parecía un simple bug de UI.
Si estás parcheando síntomas cada semana, párate y haz un diagnóstico y refactor más profundo antes de añadir más features. FixMyMess (fixmymess.ai) puede empezar con una auditoría de código gratuita y ayudar a convertir un prototipo generado por IA en software listo para producción con reparaciones verificadas por expertos.
Preguntas Frecuentes
What should I include so a report is actually fixable?
Escribe un título de una frase que nombre la pantalla y lo que falló, y luego añade la ruta de reproducción más corta que un compañero pueda seguir. Incluye estado inicial, entradas exactas, esperado vs actual y una comprobación clara de éxito/fracaso para que el equipo pueda confirmar la corrección.
What’s the fastest way to clarify “it doesn’t work”?
Pregunta cuál fue la última acción que hicieron, qué esperaban, qué pasó en su lugar y si vieron algún texto de error exacto. Luego confirma el dispositivo/navegador y si ocurre siempre o solo a veces.
Should I rewrite user complaints into my own words?
Mantén el mensaje original del usuario tal cual en el registro y añade campos estructurados por separado. Así conservas el contexto y evitas cambiar el significado mientras lo «resumes».
How do I keep feedback from getting scattered across chats and emails?
Elige una fuente de la verdad, como un tracker, un doc compartido o una hoja de cálculo, y registra allí cada informe. Dale a cada reporte un ID simple para que duplicados, comentarios y correcciones queden vinculados.
How do I handle duplicate bug reports without wasting time?
Agrupa quejas similares en un solo problema con múltiples ejemplos en lugar de crear tareas separadas por cada mensaje. Lleva la cuenta de cuántas personas lo reportaron para que la frecuencia sea visible.
What tags help most when the backlog is messy?
Usa un conjunto pequeño de etiquetas coherentes como tipo, severidad, frecuencia y área para poder ordenar issues rápidamente. Añade banderas de riesgo explícitas para autenticación, pagos, pérdida de datos y exposición de seguridad para que salten al frente.
How do I prioritize fixes without chasing the loudest complaint?
Prioriza por impacto en el negocio: ¿bloquea pagos, registros, inicios de sesión o confianza? Añade una estimación de esfuerzo aproximada y haz primero los items de alto impacto y bajo esfuerzo; divide los de alto impacto y gran esfuerzo en pasos pequeños y entregables.
What evidence is worth attaching to a bug report?
Adjunta la mínima evidencia que acelere la reproducción: captura de pantalla, grabación de pantalla, marca temporal y cualquier error de consola o de red que puedas capturar. La evidencia es más útil cuando está ligada a un intento de reproducción específico.
How do I write acceptance criteria that prevent “fixed but not really”?
Define “hecho” como una prueba que otra persona pueda ejecutar y obtener el mismo resultado, por ejemplo completar el flujo varias veces en los dispositivos afectados. Si no puede probarse claramente, es fácil que se parezca a un arreglo pero siga fallando para usuarios reales.
Why are AI-generated apps harder to debug from vague feedback?
Sé más estricto con los detalles de entorno y la versión, porque pequeños cambios pueden crear bugs distintos con el mismo síntoma. Si la base de código parece frágil o arriesgada, una auditoría externa focalizada como la de FixMyMess puede convertir reportes vagos en correcciones seguras y comprobables.