Cuándo agregar una réplica de lectura: señales, enrutamiento y riesgos
Cuándo añadir una réplica de lectura: señales claras, enrutamiento seguro y cómo evitar sorpresas por lag de replicación y suposiciones rotas.
Qué problema resuelve realmente una réplica de lectura
Una réplica de lectura ayuda cuando tu base de datos dedica tanto tiempo a responder lecturas que las escrituras empiezan a sufrir. No se trata solo de hacer que las páginas se sientan más rápidas. Se trata de proteger la base primaria para que pueda seguir aceptando actualizaciones en lugar de quedarse bloqueada por consultas SELECT pesadas.
Esto suele aparecer en un patrón familiar: una o dos pantallas populares (o endpoints de API) generan la mayor parte del trabajo en la base de datos. Un panel que se refresca con frecuencia, una página de búsqueda o una vista administrativa de “listar todo” pueden consumir CPU y E/S. Entonces las partes de la app que crean pedidos, actualizan perfiles o escriben logs empiezan a tener timeouts o comportamientos impredecibles.
Una réplica hace una cosa principal: te da otra copia de los datos desde la que leer. Tu app puede enviar algunos SELECT a la réplica para que la primaria tenga más espacio para INSERT/UPDATE/DELETE.
Lo que no arregla:
- Consultas lentas porque están mal escritas o faltan índices
- Problemas de locking causados por transacciones largas en la primaria
- Demasiadas escrituras (una réplica no aumenta la capacidad de escritura)
- Lógica de la app que asume que toda lectura está inmediatamente actualizada
Ese último punto es por qué la decisión trata de corrección, no solo velocidad. Una réplica suele ir un poco por detrás de la primaria. Si lees en ella en el momento equivocado, un usuario puede no ver sus ajustes recién actualizados, una página de “pago confirmado” puede seguir mostrando pendiente, o un agente de soporte puede pensar que una acción no ocurrió.
Una regla práctica: agrega una réplica de lectura cuando tengas tráfico claramente orientado a lecturas que esté dañando la capacidad de respuesta de las escrituras, y puedas nombrar qué endpoints son seguros para servir con datos ligeramente obsoletos.
Conceptos básicos de réplicas de lectura (sin jerga)
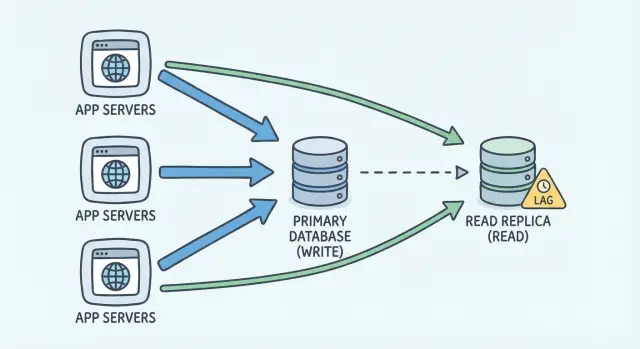
Una réplica de lectura es un segundo servidor de base de datos que contiene una copia de tu base principal. Mantienes una base “primaria” como fuente de verdad. Todas las escrituras van allí, porque es el único sitio garantizado con los datos más recientes.
La réplica es principalmente para lecturas. En lugar de que cada carga de página, informe o gráfico golpee la primaria, algunas consultas de solo lectura pueden ir a la réplica para que la primaria siga respondiendo a escrituras y peticiones críticas.
Cómo se actualiza la copia
La mayoría de las configuraciones usan replicación asíncrona. En términos sencillos: la primaria registra los cambios primero y luego la réplica recibe y aplica esos cambios un poco después. Ese retraso es el lag de replicación. A veces es mínimo (milisegundos). Bajo carga, o durante picos, puede crecer a segundos o más.
Ese hecho explica la mayoría de las sorpresas que encuentran las personas.
El intercambio que estás eligiendo
Una réplica puede hacer que tu app se sienta más rápida, pero pagas con frescura. Las lecturas desde la réplica pueden ir un poco por detrás de la primaria.
Un modelo mental simple:
- Primaria: correcta ahora mismo, maneja escrituras
- Réplica: escala lecturas, puede ir por detrás
- Lag: la brecha entre lo que acabas de escribir y lo que la réplica puede ver
Ejemplo: un usuario actualiza su correo y recarga la página de perfil inmediatamente. Si esa página lee desde la réplica, puede seguir mostrando el correo antiguo por un momento. No es un error permanente, pero confunde a menos que enrutes esas lecturas con cuidado.
Señales de que estás listo para considerar una réplica
Una réplica ayuda cuando tu base de datos dedica la mayor parte del tiempo a lecturas (SELECT), no a escrituras. Si la CPU de la base de datos está alta y tus consultas principales son principalmente SELECT, esa es una señal fuerte.
Otro indicador común es “el tráfico de lecturas perjudica las escrituras”. Ves la latencia de escrituras subir justo cuando el tráfico de lecturas alcanza picos, aunque el volumen de escrituras no haya cambiado. Lecturas y escrituras compiten por la misma CPU, memoria y disco, así que páginas de reporting pesadas pueden ralentizar el checkout, los registros o cualquier actualización.
Observa detenidamente qué está lento. Páginas de listado, dashboards, tablas administrativas, resultados de búsqueda y exportaciones suelen ser buenos candidatos. Estos endpoints tienden a escanear muchas filas y son llamados muchas veces por usuarios reales (o jobs en background).
La presión en el pool de conexiones es otro disparador práctico. Si alcanzas el máximo de conexiones principalmente debido a endpoints con muchas lecturas, una réplica puede reducir la contención. No arreglará consultas ineficientes, pero puede ganar espacio.
El cache puede retrasar la necesidad de una réplica, pero no siempre es suficiente. A menudo estás listo para una réplica cuando:
- La tasa de hits del cache se mantiene baja porque los datos cambian con frecuencia o las claves son difíciles de diseñar
- El caching causa problemas de “números incorrectos” visibles por el usuario
- Necesitas datos relativamente frescos, pero no perfectamente instantáneos
- Exportaciones y filtros ad-hoc no se pueden cachear de forma segura
- Tu capa de cache ya es una fuente importante de bugs
Un proceso de decisión que puedes seguir
Trata añadir una réplica como un pequeño experimento con una métrica clara de éxito. El objetivo no es “añadir más bases de datos”. Es “reducir el dolor sin romper la corrección”.
Empieza por ser específico. “La app se siente lenta” no es suficiente. Quieres una lista corta de endpoints y consultas que puedas medir antes y después.
Un proceso que funciona para la mayoría de equipos:
- Identifica tus endpoints de lectura principales por conteo de consultas y tiempo total (dashboard, búsqueda, feed, reports).
- Confirma que la base de datos es el cuello de botella (no el CPU de app server, código lento, cache faltante o llamadas API ruidosas).
- Divide las lecturas en dos cubetas: deben ser frescas (saldos, permisos, checkout) vs pueden estar ligeramente obsoletas (analítica, listas de actividad, páginas públicas).
- Establece un objetivo verificable, como “reducir la carga de lecturas en la primaria en 40%” o “bajar p95 de carga del dashboard de 3s a 1s”.
- Define un plan de reversión: cómo volverás a servir lecturas desde la primaria rápido si algo va mal.
Luego decide dónde enrutarás las lecturas. Un buen primer paso es enrutar solo endpoints “pueden estar ligeramente obsoletos” a la réplica y mantener todas las escrituras en la primaria. Evita mezclar lecturas y escrituras dentro de la misma petición al principio. Ahí es donde el lag duele.
Antes de activar nada en producción, haz una comprobación rápida de seguridad:
- ¿Puedes saber qué BD sirvió una petición (logs, tags o tracing)?
- ¿Puedes detectar lag y volver temporalmente a la primaria?
- ¿Tienes un plan de pruebas corto para la corrección visible al usuario (login, pagos, permisos)?
Si no puedes medir la mejora y no puedes revertir rápido, espera. Una réplica añade complejidad, así que quieres que el beneficio sea obvio.
Qué endpoints se benefician (y cuáles deben quedarse en la primaria)
Una réplica ayuda más cuando tienes muchas lecturas que no necesitan estar perfectamente actualizadas. La meta no es moverlo todo. Es quitar presión de la primaria mientras mantienes la app correcta.
Grandes candidatos para una réplica
Suelen ser seguros porque son muy orientados a lectura y no están ligados al dinero o acceso:
- Páginas públicas (marketing, blog, páginas públicas de producto)
- Búsqueda y navegación (filtros, listings de categoría)
- Analítica e informes (gráficos, tendencias, exportaciones)
- Listados administrativos (tablas de usuarios, pedidos, logs) donde los clics llevan a detalles en la primaria
- APIs de solo lectura usadas por partners o herramientas internas
Vistas de perfil de usuario y catálogos de producto suelen estar bien con cuidado. La mayoría de usuarios no notará si un avatar o biografía tarda un momento en sincronizar.
Endpoints que deben quedarse en la primaria
Si afecta dinero o acceso, mantenlo en la primaria. Eso incluye checkout, pagos, estado de suscripción y cualquier cosa que decida qué puede ver o hacer un usuario.
También vigila endpoints que parecen de solo lectura pero escriben en realidad. Los equipos suelen añadir escrituras pequeñas como actualizar last_seen, incrementar contadores de vistas, refrescar sesiones o registrar “visto recientemente”. Si enrutas ese endpoint a una réplica, puede fallar (las réplicas suelen ser de solo lectura) o comportarse de forma inconsistente.
Una regla simple: envía a réplicas solo consultas idempotentes y de solo lectura. Mantén en la primaria todo lo que cambie estado o decida accesos. Si no estás 100% seguro, trátalo como primaria hasta verificar las consultas.
Cómo enrutar lecturas sin volver frágil la app
Enrutar lecturas suena simple: manda SELECTs a la réplica y mantén escrituras en la primaria. En la práctica, lo frágil es todo lo que lo rodea: manejo de conexiones, momentos de “leer tu propia escritura” y qué pasa cuando la réplica se queda atrás.
Dos enfoques prácticos de enrutamiento
Normalmente enrutas en uno de dos lugares.
Si enrutas en el código de la aplicación, eliges la base por endpoint (o por consulta). Es directo porque es explícito: “navegar productos” puede usar la réplica mientras “actualizar perfil” sigue en la primaria. La desventaja es que las reglas de enrutamiento pueden dispersarse por el código y volverse difíciles de razonar.
Si enrutas vía un proxy o router de base de datos, las políticas viven en un solo lugar, lo que puede hacer los rollbacks más rápidos. El riesgo es que esconda sorpresas: una consulta que asumías segura puede terminar en la réplica y mostrar resultados obsoletos.
Hazlo resistente (y fácil de deshacer)
Trata a primaria y réplica como recursos diferentes, no hosts intercambiables. Usa conexiones separadas y pools separados para que una réplica lenta no atasque el pool usado para escrituras.
Un pequeño conjunto de reglas de seguridad evita la mayoría de incidentes:
- Después de que un usuario escriba, mantenlo “pegado” a la primaria por una ventana corta (a menudo segundos).
- Por defecto usa la primaria para cualquier cosa que involucre dinero, auth, permisos o contenido generado por el usuario justo después de crear.
- Añade un kill switch que envíe todas las lecturas de vuelta a la primaria al instante (flag de configuración, var de entorno, feature flag) y pruébalo.
- Timeoutea lecturas de réplica de forma agresiva y cae a la primaria en lugar de fallar la petición.
Ejemplo: un dashboard carga 12 widgets. Enruta widgets lentos y no críticos (gráficos semanales, páginas principales) a la réplica, pero mantén “plan actual” y “última factura” en la primaria. Si la réplica se queda atrás, la página sigue funcionando; solo los gráficos van con retraso.
Cómo manejar el lag de replicación con seguridad
El lag de replicación es el tiempo que tarda un nuevo dato escrito en la primaria en aparecer en la réplica. Si tu app lee desde la réplica demasiado pronto, los usuarios pueden ver información antigua y asumir que algo falló.
Empieza por definir qué significa “seguro obsoleto” para tu producto. Para un dashboard, estar 5 a 30 segundos detrás puede estar bien. Para facturación, contraseñas o permisos, incluso 1 segundo puede ser demasiado.
Reglas prácticas que previenen sorpresas
Unas pocas reglas cubren la mayoría de casos reales:
- Usa read-after-write: después de que un usuario actualice algo, enruta las siguientes peticiones a la primaria para ese usuario (o registro).
- Mantén pantallas críticas en la primaria: pagos, login, control de acceso y cualquier cosa que pueda bloquear a alguien.
- Si debes mostrar datos de réplica en una pantalla crítica, muestra un estado de “actualizando” y evita decir que algo es definitivo.
- Detecta lag y deja de usar la réplica cuando suba demasiado.
- Evita mezclar resultados de primaria y réplica en la misma respuesta (crea combinaciones imposibles).
Ejemplo concreto: un usuario cambia su correo y aterriza en su perfil. Si esa página lee desde la réplica, puede seguir mostrando el correo antiguo. Con read-after-write, enrutas ese perfil a la primaria durante 30–60 segundos tras la actualización. Tras esa ventana, las lecturas normales a la réplica vuelven a estar bien.
El enrutamiento consciente del lag también importa durante picos y despliegues. Las réplicas suelen quedarse atrás cuando la primaria está ocupada o aparece una consulta larga. Si tu app puede medir el lag de réplica (o usa una comprobación por umbral), puedes volver a la primaria hasta que la réplica alcance.
Qué se rompe primero cuando añades una réplica
Las primeras roturas suelen ser las que los usuarios notan de inmediato: “Lo guardé, pero no cambió.” Un pequeño retraso puede convertirse en un gran problema de confianza.
Los tickets de soporte suelen aumentar cuando la gente edita un perfil, cambia ajustes o publica un comentario y al refrescar ve el dato antiguo. Planifica momentos de “leer tu propia escritura”, no solo más capacidad.
Auth y comprobaciones de permisos también fallan pronto. Si un usuario acaba de mejorar un plan, fue añadido a un equipo o perdió acceso, una lectura en réplica puede devolver el estado anterior. Eso lleva a “¿por qué sigo bloqueado?” o peor, “¿por qué aún puedo ver esto?”.
Los jobs en background también pueden comportarse mal. Muchos sistemas de colas leen una fila para decidir si hay trabajo pendiente. Con lecturas obsoletas, dos workers pueden pensar que el trabajo está pendiente y ejecutarlo dos veces, o pueden pasarlo por alto porque la réplica no se ha puesto al día.
Aunque nada esté realmente roto, la UI puede verse inconsistente. Paginación y ordenación pueden saltar si una petición golpea la primaria y la siguiente la réplica que va detrás. Verás duplicados, ítems faltantes o recuentos de páginas que cambian entre clics.
Los contadores se desvían más rápido de lo esperado: límites de tasa, contadores de vistas, badges de no leídos, totales de notificaciones. Si una petición incrementa en la primaria pero la siguiente lectura viene de una réplica con lag, los números pueden retroceder.
Si quieres un valor por defecto simple, mantiene estos exclusivamente en la primaria a menos que los hayas probado cuidadosamente:
- Pantallas justo después de una escritura (guardar, checkout, ajustes)
- Login, comprobaciones de permisos y lecturas relacionadas con sesión
- Tablas estilo work-queue usadas por jobs en background
- Cualquier cosa que dependa de orden exacto o recuentos
- Límites de tasa, cuotas y contadores de badges
Errores comunes y trampas
La mayor trampa es enviar cada SELECT a la réplica porque “son solo lecturas”. Muchas lecturas forman parte de un flujo que espera la última escritura: “crear cuenta” luego “cargar perfil”, o “añadir al carrito” luego “mostrar carrito”.
Otro problema común son dependencias de read-after-write ocultas. Una página de ajustes puede guardar preferencias y luego volver a consultarlas inmediatamente. Un endpoint de login puede leer un registro de sesión justo después de escribirlo. Si esas lecturas golpean la réplica durante lag, la app parecerá rota aunque la escritura haya tenido éxito.
El manejo de conexiones es una fuente silenciosa de dolor. Si compartes un pool de conexiones para primaria y réplica, la app puede enviar accidentalmente escrituras a la réplica (o aplicar configuraciones de solo réplica en la primaria). Incluso cuando “funciona”, depurar se vuelve más difícil porque logs y métricas no muestran claramente qué base atendió la consulta.
La monitorización suele añadirse demasiado tarde. Mide lag, errores de consulta en réplica y consultas lentas por separado, y alerta ante cambios bruscos tras despliegues.
Algunas trampas a destacar:
- Enrutar por nombre de endpoint en vez de por necesidad de frescura
- Olvidar que herramientas admin y jobs en background también ejecutan consultas
- No probar comportamiento ante fallos (réplica caída, picos de lag)
- Cachear lecturas con lag y hacerlas obsoletas por más tiempo del deseado
- No tener un toggle rápido para enviar todo el tráfico a la primaria
Planifica una reversión antes de desplegar. Un feature flag que fuerce todas las lecturas a la primaria puede ahorrarte horas.
Preguntas Frecuentes
What problem does a read replica actually solve?
Una réplica de lectura ayuda cuando el tráfico de lecturas es tan intenso que ralentiza las escrituras en tu base de datos primaria. El objetivo es mantener la primaria receptiva para las actualizaciones al descargar consultas de solo lectura seguras a otra copia de los datos.
Si tu app se siente lenta pero la base de datos no es realmente el cuello de botella, una réplica no arreglará el problema real.
When should I add a read replica instead of just optimizing queries?
Usa una réplica cuando tus consultas más pesadas son principalmente SELECT y ves que la latencia de escrituras empeora durante picos de lecturas. Un signo común es que unas pocas pantallas (dashboards, búsquedas, listados de administración) consumen la mayor parte del tiempo de la base de datos.
Si el dolor viene de consultas mal diseñadas o índices faltantes, arregla eso primero antes de añadir más componentes móviles.
Which endpoints are usually safe to send to a replica?
Empieza por enrutar endpoints que toleren datos ligeramente obsoletos, como widgets de analítica, feeds de actividad, resultados de búsqueda y grandes tablas de administración. Suelen generar mucha carga de lectura sin necesitar frescura perfecta.
Mantén el primer despliegue limitado para que puedas medir el impacto y deshacerlo rápido si los usuarios reportan resultados confusos.
What should always stay on the primary database?
Mantén en la primaria todo lo relacionado con dinero, acceso o confirmaciones inmediatas del usuario. Eso incluye checkout, pagos, estado de suscripción, login, comprobaciones de permisos y pantallas que se visitan justo después de guardar cambios.
Estos flujos suelen requerir "leer lo que acabas de escribir", y el lag de réplica puede hacer que la app parezca rota o inconsistente.
What is replication lag, and why does it matter?
El lag de replicación es el retraso entre escribir en la primaria y ver ese cambio en la réplica. Con replicación asíncrona, la réplica suele ir un poco por detrás y, bajo carga, puede quedarse segundos atrás.
Por eso la decisión sobre réplicas es sobre corrección, no solo velocidad.
How do I prevent “I just updated it, but I still see the old data”?
Una regla simple es: después de que un usuario escribe, enruta sus lecturas a la primaria por una ventana corta (a menudo segundos). Esto evita la experiencia de “lo guardé pero no cambió”.
Puedes implementar esto con stickiness de sesión o reglas de enrutamiento por petición para endpoints que siguen escrituras.
What tends to break first after adding a replica?
La falla más común es la inconsistencia visible al usuario: alguien actualiza ajustes, refresca y ve el valor antiguo porque la lectura golpeó la réplica. Otro fallo frecuente es en control de acceso, donde un cambio de rol reciente aún no llegó a la réplica.
Los jobs en background también pueden comportarse mal si toman decisiones basadas en lecturas obsoletas y ejecutan trabajo dos veces o se lo pierden.
What are the biggest mistakes teams make with read replicas?
Evita mezclar lecturas de primaria y réplica dentro de la misma respuesta al principio, porque puedes crear resultados contradictorios. También evita enviar “todo lo que sea SELECT” a la réplica, ya que muchas lecturas forman parte de un flujo de escritura.
Mantén las reglas de enrutamiento fáciles de razonar y facilita el rollback para no quedarte atascado durante un incidente.
How do I make replica routing safe to roll back?
Ten un kill switch que envíe todas las lecturas de vuelta a la primaria al instante, y pruébalo antes de necesitarlo. Además, fija timeouts agresivos para lecturas de réplica y cae a la primaria en lugar de fallar la petición.
Monitorea el lag de réplica y deja de usar la réplica cuando el lag supere el umbral que consideres seguro para tu producto.
What if my codebase is messy (or AI-generated) and routing reads sounds risky?
Si la base de código tiene acceso a BD disperso, escrituras ocultas dentro de endpoints “de lectura” o no hay forma clara de aplicar reglas de read-after-write, añadir una réplica puede crear bugs confusos. En ese caso suele merecer la pena arreglar enrutamiento, pooling de conexiones y comportamiento ante lag primero.
FixMyMess ayuda a equipos a reparar código heredado o generado por IA donde la separación lectura/escritura es frágil, para que las réplicas mejoren el rendimiento sin romper la corrección.