Despliegue blue-green para apps pequeñas: cortes y rollbacks más seguros
Aprende despliegue blue-green para apps pequeñas con dos entornos, cortes seguros, rollbacks rápidos y guía práctica para bases de datos y sesiones.
Por qué las apps pequeñas siguen sufriendo por despliegues riesgosos
Las apps pequeñas suelen caer por razones aburridas. Se despliega un cambio minúsculo y de repente el login falla para todos. O un job en background se ejecuta dos veces y escribe filas duplicadas. O un valor de configuración apunta a la base de datos equivocada y los usuarios reciben errores durante una hora.
Esas caídas se sienten injustas porque la app no es "grande." Pero el riesgo suele ser mayor en equipos pequeños: menos ojos revisando cambios, menos tiempo para pruebas y nadie de guardia que pueda dejarlo todo para arreglar producción.
Los peores despliegues rompen cosas que son difíciles de ver localmente. La autenticación y las sesiones pueden fallar porque las cookies se invalidan, los callbacks están mal configurados o los tokens son rechazados. Los datos pueden quedar en riesgo cuando las migraciones bloquean tablas o cuando el código escribe campos nuevos antes de que existan. Los ajustes en tiempo de ejecución muerden cuando faltan secretos, las variables de entorno están mal o las reglas de red difieren del entorno de desarrollo. Y aunque todo funcione en una prueba tranquila, el tráfico real puede tumbar un endpoint que parecía bien en desarrollo.
El despliegue blue-green reduce ese riesgo sin convertir los lanzamientos en una ceremonia pesada.
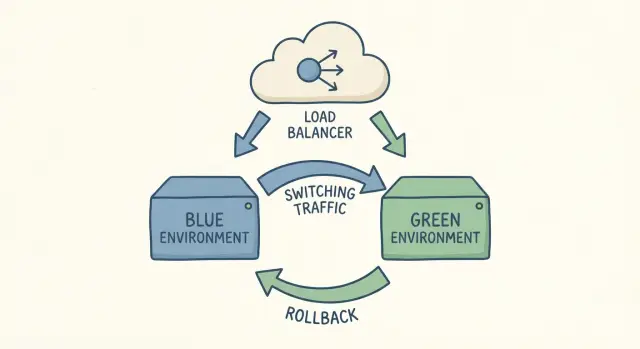
Cuando la gente dice "dos entornos", se refieren a dos copias completas de tu configuración de app ejecutándose al mismo tiempo: una está en vivo (blue) y la otra es la nueva versión que vas a lanzar (green). Ambas deberían usar el mismo tipo de servidor, las mismas dependencias y ajustes parecidos a producción. La clave es que solo una de ellas recibe tráfico real de usuarios.
Un corte es simplemente cambiar el tráfico de blue a green. Si algo sale mal, lo cambias de vuelta. Esa es la idea completa.
No se trata de procesos pesados. Se trata de darte un lugar seguro para responder preguntas prácticas antes de que los usuarios paguen el precio: ¿sigue funcionando el login?, ¿cargan las páginas clave?, ¿se comportan bien los jobs en background?, ¿puedes hacer rollback rápido si te olvidaste de algo?
Un escenario común en apps pequeñas es un cambio "rápido" hecho con prisa. Funciona para ti y luego rompe para los usuarios porque producción tiene cookies, dominios o secretos distintos. Con green esperando, puedes probar esos detalles que solo aparecen en producción y luego hacer el cambio cuando estés confiado.
Si tu base de código fue generada por IA y ya es inestable, el riesgo aumenta. Los equipos suelen heredar autenticación rota, secretos expuestos y lógica enmarañada que se comporta distinto bajo tráfico real. Blue-green no arregla código malo por sí solo, pero puede evitar que un despliegue malo se convierta en una caída larga.
Blue-green en lenguaje sencillo
El despliegue blue-green es la idea simple de mantener dos copias listas para ejecutarse de tu app.
Blue es lo que usan los usuarios ahora mismo. Es la versión actual en vivo que atiende tráfico real. Green es la nueva versión que quieres lanzar. La construyes, la configuras y la pruebas mientras blue sigue sirviendo a los usuarios.
Cuando estás satisfecho con green, haces un cambio de tráfico controlado para que los usuarios empiecen a ir a green en lugar de blue. Ese cambio suele ocurrir en un solo lugar: una regla de load balancer o reverse proxy, un swap de entorno si tu hosting lo soporta, una configuración del enrutador en tu gateway de contenedores o (menos ideal) DNS. DNS funciona, pero el caching hace que el tiempo sea menos predecible.
La gran ventaja es rapidez y confianza. Si algo falla después del corte, el rollback suele ser solo cambiar el tráfico de vuelta a blue. No estás reconstruyendo la versión antigua bajo presión. Ya está ahí y funcionando.
Imagínate un SaaS sencillo con login, facturación y un dashboard. Despliegas green con un nuevo diseño del panel, haces pruebas de humo en la infraestructura real y luego conmutas. Si los clientes reportan gráficas rotas, puedes volver a blue en minutos mientras arreglas green.
Blue-green no lo resuelve todo mágicamente. Dos áreas en las que los equipos suelen tropezar son:
Cambios en la base de datos: si green necesita una tabla nueva o columnas cambiadas, tienes que planear para que tanto blue como green funcionen de forma segura durante la transición.
Sesiones e inicios de sesión: si las sesiones se guardan en memoria en cada instancia, los usuarios pueden quedar desconectados cuando el tráfico cambia. Un almacenamiento de sesiones compartido (o auth stateless) lo evita.
Cuándo blue-green encaja bien (y cuándo no)
Blue-green funciona mejor cuando quieres lanzamientos más seguros sin herramientas de lanzamiento complicadas. Mantienes dos entornos parecidos a producción, pruebas el nuevo con settings reales y luego cambias el tráfico.
Encaja bien cuando tu app es mayoritariamente stateless y tus cambios son fáciles de probar end-to-end. Eso suele incluir apps web simples, APIs con peticiones cortas e independientes, herramientas internas con usuarios conocidos y productos SaaS tempranos que envían cambios pequeños con frecuencia. También ayuda cuando puedes permitirte ejecutar dos copias durante una ventana de lanzamiento.
Un ejemplo simple: un pequeño SaaS con Next.js y una API. Despliegas la nueva versión en green, haces una prueba rápida (login, crear un ítem, exportar) y luego cambias el tráfico. Si algo se siente raro, vuelves en minutos.
No es una buena opción cuando la parte más difícil del lanzamiento es la base de datos, o cuando el trabajo no puede duplicarse de forma segura entre entornos. Señales de advertencia incluyen reescrituras frecuentes de esquema que bloquean tablas, jobs de larga duración que no se pueden pausar o duplicar, mucho estado en memoria como WebSockets o almacenamiento de sesión personalizado, y efectos secundarios con terceros (pagos, emails) que no puedes reproducir sin cuidado. Tampoco funciona bien si el equipo no tiene una checklist de corte y rollback por escrito.
Hay un costo: pagas por dos copias durante los lanzamientos. Para apps pequeñas esto puede seguir siendo barato, pero planifica cómputo duplicado y servicios replicados (colas, caches) si los necesitas.
La herramienta importa menos que los hábitos del equipo. Una checklist corta (quién cambia el tráfico, qué verificar, qué provoca rollback) evita el pánico.
Qué necesitas antes de intentarlo
Blue-green funciona mejor cuando tratas a blue y green como dos copias separadas y completas de producción. Si lo básico no está sólido, puedes cambiar el tráfico, pero no sabrás cuál lado está sano y el rollback puede volverse desordenado.
Empieza por la configuración. Blue y green deben ejecutar el mismo código, pero no deben compartir secretos equivocados por accidente. Separa claramente las variables de entorno y facilita confirmar qué entorno está usando un servicio. Un fallo común es apuntar green a la base de datos equivocada, a un callback de OAuth incorrecto o a una clave de pago de pruebas.
Checklist mínima de configuración
Antes de tu primer corte, quieres poder responder "sí" a esto:
- Configuraciones separadas para blue y green (env vars, secretos, claves de terceros), con nombres claros y una forma fácil de verificar lo que se cargó.
- Un artefacto de build reproducible que se promociona (build una vez, despliega muchas). No reconstruyas para green.
- Un health check que pruebe más que "el servidor está arriba" (incluye dependencias críticas como base de datos y cache).
- Monitorización básica de lo que sienten los usuarios (tasa de errores y latencia) más una o dos acciones clave (registro, checkout, subida de archivo).
- Logs que puedas leer bajo estrés (request IDs, errores útiles y una forma de comparar blue vs green).
Los health checks merecen atención extra. Un endpoint "200 OK" está bien para un load balancer, pero también quieres una señal más profunda antes del corte. Por ejemplo: ¿la app puede alcanzar la base de datos, leer una fila y escribir un registro liviano? Si no puedes probar escrituras de forma segura, al menos verifica que la app pueda conectarse y ejecutar una consulta simple.
Mantén los lanzamientos aburridos. La mayor ventaja de blue-green es la confianza de que estás cambiando a lo mismo que ya probaste. Si tu build cambia entre entornos, estás probando una cosa y enviando otra.
Paso a paso: un runbook simple de despliegue blue-green
Blue-green funciona mejor como una checklist corta y repetible. No buscas sofisticación; buscas ser aburrido y seguro.
1) Escoge cómo vas a cambiar el tráfico
Elige un método de corte y cúmplelo:
- Cambio en load balancer o reverse proxy
- Swap de plataforma (si tu host lo soporta)
- Cambio de DNS (funciona, pero el caching lo hace impredecible)
Decide de antemano quién tiene acceso, cuánto tiempo tarda y cómo deshacerlo.
2) Despliega green para que coincida con blue
Despliega la nueva versión en green con la misma "forma" que blue: los mismos servicios (cola, cache, almacenamiento), el mismo enfoque de gestión de secretos, la misma configuración de workers en background y ajustes de runtime equivalentes. Los valores pueden diferir, pero la estructura debe ser consistente.
La mayoría de fallos en blue-green ocurren porque green no es realmente similar a producción. Green apunta a otra base de datos, falta un secreto que causa fallo de auth solo después del corte, o un runner de jobs no está conectado igual.
3) Verifica green antes de que los usuarios la toquen
Haz pruebas de humo rápidas contra green usando una cuenta real (o una segura para staging). Manténlo simple y céntrate en lo que rompe ingresos y confianza:
- Iniciar y cerrar sesión
- Cargar algunas páginas clave
- Crear y actualizar un registro real
- Disparar un job en background (email, webhook, reporte)
- Escanear logs en busca de nuevos picos de error
Si tu app usa caches o workers, lánzalos temprano y deja que se calienten. Un patrón común es que "funcionó en pruebas" pero falla cuando las caches están frías y los workers comienzan a procesar colas reales.
4) Haz el corte y observa de cerca
Cambia el tráfico de forma controlada. Si tu infraestructura permite tráfico gradual (incluso 10% primero), hazlo. Si es todo o nada, hazlo en una ventana tranquila.
Durante los próximos 10 a 30 minutos, vigila un conjunto corto de señales: tasa de errores, latencia, éxito de login, checkout o tu acción clave, y carga en la base de datos. Decide de antemano qué números significan "parar y volver atrás."
Cambios en la base de datos sin perder escrituras
La parte más difícil del blue-green suele ser la base de datos.
El riesgo central es simple: por un tiempo, dos versiones de tu app pueden estar vivas. Si ambas hablan con la misma base de datos pero esperan tablas o columnas diferentes, una versión puede empezar a lanzar errores. Peor aún, puede escribir datos que la otra versión no pueda leer o sobrescribir campos de maneras inesperadas.
Un patrón más seguro es hacer los cambios de base de datos compatibles hacia atrás primero. Añade cosas antes de quitar otras. Mantén funcionando el código antiguo mientras la versión nueva se despliega.
Usa el enfoque "expandir y luego contraer"
La mayoría de las apps pequeñas evitan downtime dividiendo el trabajo de esquema en movimientos más pequeños:
- Expandir: añade columnas o tablas nuevas y conserva las antiguas.
- Escribir con solapamiento: actualiza la versión nueva para escribir en el nuevo lugar mientras mantienes lecturas compatibles.
- Contraer: después del corte y una ventana segura, elimina columnas, tablas o caminos de código antiguos.
Ejemplo: quieres renombrar users.fullname a users.display_name. No elimines fullname durante el corte. Añade display_name, despliega código que escriba ambos campos (o escriba uno y haga backfill del otro) y limpia más tarde.
Separa el despliegue de las migraciones destructivas
Evita empaquetar "drop column", "reescribir tabla" o "backfill de 50 millones de filas" en el mismo momento en que cambias el tráfico. Haz el trabajo lento o riesgoso con anticipación, mientras la versión actual aún sirve a los usuarios. Si una migración va a tomar minutos o bloquear filas, trátala como una pre-migración y hazla segura para correr mientras la app antigua está viva.
Durante la ventana de corte, comprueba la compatibilidad en ambas direcciones: la app vieja leyendo filas escritas por la nueva y la nueva leyendo filas escritas por la vieja. Ahí es donde aparecen suposiciones ocultas, como listas de columnas codificadas, manejo nulo faltante o defaults inseguros.
Sesiones y auth: mantener a los usuarios conectados durante el cambio
La forma más rápida de convertir un corte seguro en una pesadilla de soporte es desconectar a todos por accidente. Las sesiones suelen romperse porque algo cambió entre blue y green: un nombre de cookie, una clave de firma, un formato de token o incluso el dominio/subdominio.
Mantén las reglas de identidad idénticas en ambos lados
Durante la ventana de corte, considera estos elementos como contratos compartidos que no deben cambiar:
- Claves de firma y encriptación de sesiones (secretos de cookies, claves de firma JWT, secretos CSRF)
- Ajustes de cookies (nombre, dominio, path, Secure, HttpOnly, SameSite)
- Formatos de token y sesión (claims, reglas de expiración, serialización)
- Callbacks de auth y URLs de redirección (para OAuth)
Si necesitas rotar claves, hazlo con solapamiento. Green debe aceptar tanto la clave vieja como la nueva para verificación, mientras solo emite sesiones nuevas con la clave nueva. Los usuarios existentes siguen conectados y los inicios nuevos usan la clave más segura.
Prefiere auth stateless (pero mantén compatibilidad)
Si tu app puede usar tokens de acceso de corta vida más un flujo de refresh, los cortes son más sencillos porque el servidor no necesita recordar sesiones. Lo importante es la compatibilidad: green debe aceptar tokens emitidos por blue hasta que expiren naturalmente. Evita cambiar nombres de claims o reglas de audiencia en el mismo lanzamiento.
Si usas sesiones del lado servidor, haz que el almacén de sesiones sea compartido. Tanto blue como green deben leer y escribir en el mismo respaldo (a menudo Redis o una tabla de base de datos). Si cada entorno tiene su propio almacén, los usuarios pasarán a green y parecerán "desconocidos" aunque su cookie esté bien.
Los checkouts y formularios largos son puntos comunes de dolor. Alguien está en medio de un pago, ocurre el corte y su siguiente petición llega a green. Manténlo seguro almacenando estado de carrito y orden en la base de datos (no solo en memoria), usando idempotencia para acciones de pago y haciendo envíos de formularios tolerantes a reintentos. Cuando sea posible, cambia el tráfico gradualmente y deja que blue termine las solicitudes en vuelo antes de cortar completamente.
Hacer rollback rápido sin empeorar las cosas
En blue-green, rollback suele no significar revertir cambios de código. Significa cambiar el tráfico de producción de vuelta al entorno anterior (de green a blue). Si el enrutamiento está limpio, esto puede ser rápido.
El objetivo es rapidez y certeza. Elige un responsable para la decisión y mantén una acción obvia que invierta el tráfico (un botón, un comando, un paso claro del runbook). Cuando todos improvisan su "arreglo rápido", los rollbacks se retrasan y se vuelven caóticos.
Acordad los triggers de rollback antes del corte. Comunes son un pico súbito de 5xx/timeouts, fallos de login o signup, fallos de pago, problemas claros de integridad de datos (órdenes faltantes, duplicados, totales raros) o un incremento de latencia que hace que la app se sienta rota.
La parte difícil sigue siendo la base de datos. Una vez que green empieza a recibir escrituras, volver a blue solo es seguro si blue puede leer la nueva forma de los datos. Si tu release incluyó una migración que eliminó una columna, renombró campos o cambió constraints, blue podría fallar o comportarse mal silenciosamente. Ahí el rollback se convierte en una caída mayor.
Una regla práctica es mantener los cambios de base de datos compatibles hacia atrás por una ventana corta. Añade nuevas columnas primero, conserva las antiguas, despliega código que maneje ambas y solo elimina los campos viejos después de que pase la ventana de seguridad.
Fija una ventana de decisión. Por ejemplo: "Si vemos fallos críticos en los primeros 10 a 20 minutos, volvemos atrás. Después de eso, corregimos hacia adelante salvo que haya pérdida de datos." Eso evita debates eternos mientras los usuarios están afectados.
Una secuencia simple de rollback:
- Nombrar un responsable de incidente y congelar otros cambios
- Voltear el tráfico de nuevo al entorno anterior
- Verificar logins, pagos y los flujos de usuario principales
Errores comunes que provocan caídas
Blue-green suena simple, pero la mayoría de las caídas ocurren en los huecos aburridos entre "dos entornos" y "tráfico cambiado."
Un gran error es tratar a blue y green como dos apps distintas. Empieza pequeño: falta una variable de entorno, un secreto rotado solo en un lugar o un feature flag con valor distinto. Luego ocurre el corte y fallan los pagos o dejan de enviarse correos. Blue y green deben ser la misma build y tener la misma forma de configuración, con solo las diferencias mínimas (color de despliegue y hostnames).
Otra omisión común es el trabajo en background. El tráfico web puede cambiar limpiamente, pero el runner de jobs sigue apuntando al entorno viejo, o ambos entornos ejecutan la misma tarea programada. Eso puede causar facturas duplicadas, notificaciones dobles o dos jobs de limpieza peleando entre sí.
Los cambios de base de datos son donde la gente más se hiere. Los equipos ejecutan una migración incompatible justo en el momento del corte. Si green usa el nuevo esquema y blue sigue escribiendo la forma antigua (o viceversa), puedes perder escrituras o corromper datos rápido. El patrón más seguro es: cambios compatibles primero, desplegar, cambiar tráfico y luego eliminar lo antiguo.
Las pruebas locales no bastan. Blue-green falla en detalles propios de producción: proveedores de auth reales, cookies reales, caches reales, timeouts reales y carga real. Si solo pruebas green en tu portátil, no estás probando lo que vas a servir a los usuarios.
Finalmente, los equipos dudan durante un incidente porque no definieron una regla de parar la línea. Decide de antemano qué desencadena un rollback inmediato: un pico de errores, fallos de login que cruzan un umbral, un flujo clave roto (registro, checkout, restablecer contraseña), errores de base de datos incrementándose (deadlocks, timeouts), trabajo en background duplicado o el simple hecho de no poder explicar el problema en pocos minutos.
Checklist rápida y siguientes pasos
Blue-green funciona mejor cuando cada release es una rutina corta que detecta las pocas cosas que más dañan a los usuarios: login roto, escrituras fallidas y ralentizaciones justo después del cambio.
Antes de tocar el tráfico, haz una pasada previa: confirma health checks en el nuevo entorno (incluyendo dependencias críticas), verifica que variables de entorno y secretos se carguen del lugar correcto, revisa migraciones por seguridad (primero aditivas, sin borrados sorpresa) y asegúrate de que logs y monitorización funcionen.
Justo después del corte, prueba como un usuario real. Para muchas apps pequeñas eso significa: registrarse o iniciar sesión, crear o actualizar un registro y completar una acción central de dinero o mensajería (checkout, pago, enviar una invitación, guardar un borrador).
Tras los primeros minutos, deja de hacer clics y mira las señales. Observa cambios, no números perfectos: un aumento repentino de errores, un pico de latencia o un backlog en colas.
Decide las reglas de rollback antes de necesitarlas. Un rollback no es solo un cambio; también es una decisión sobre datos: quién tiene autoridad para revertir, la acción exacta para cambiar y cuánto tarda, qué pasa con las escrituras hechas tras el corte, cómo manejar sesiones y cuándo dejar de retroceder y empezar a arreglar hacia adelante.
Si heredaste una app generada por IA y los despliegues siguen fallando, trata eso como un problema de salud del código, no solo del proceso. Equipos en FixMyMess (fixmymess.ai) hacen diagnóstico de codebase, reparación de lógica, endurecimiento de seguridad y preparación de despliegues para prototipos generados por IA, lo que puede hacer que los cortes y rollbacks blue-green sean previsibles en lugar de estresantes.
Preguntas Frecuentes
¿Qué es el despliegue blue-green en términos sencillos?
Blue-green deployment significa mantener dos entornos completos y listos para ejecutarse. Uno (blue) atiende usuarios reales, mientras despliegas y pruebas la nueva versión en el otro (green). Cuando estés satisfecho, cambias el tráfico a green; si algo falla, vuelves a blue.
¿Por qué las apps pequeñas sufren tanto por despliegues “pequeños”?
Las apps pequeñas suelen tener menos controles antes de un lanzamiento: menos tiempo de pruebas, menos revisores y respuesta a incidentes más lenta. Un pequeño error de configuración o un cambio en la autenticación puede tumbar toda la app. Blue-green te da un paso seguro para probar en la infraestructura real sin añadir mucha ceremonia.
¿Cuál es la mejor forma de cambiar el tráfico entre blue y green?
El interruptor más común está en un load balancer o reverse proxy porque es rápido y reversible. Si tu plataforma permite un swap de entornos, puede ser aún más simple. DNS funciona, pero es menos predecible por el caching.
¿Qué debería probar en green antes de hacer el corte?
Haz una prueba de humo rápida que replique lo que más les importa a los usuarios: inicio/cierre de sesión, unas páginas clave, una acción de crear/actualizar y un trabajo en background o efecto lateral que dependa tu app. Verifica que los mismos secretos y ajustes de entorno que usas en producción estén realmente cargados. Luego vigila errores y latencia justo después del corte para poder volver rápido si hace falta.
¿Cómo evito que green apunte a la base de datos o a secretos equivocados?
Trata la configuración como el riesgo principal. Deja claro en qué entorno estás, separa configs de blue y green, y revisa los “gotchas” como endpoints de base de datos, URLs de callback de OAuth, dominios de cookies y claves de pago. La mayoría de los cortes dolorosos no son bugs de código: son ajustes equivocados.
¿Cómo evito que los usuarios se cierren sesión durante el cambio?
Mantén las reglas de identidad idénticas en ambos lados durante la ventana de corte: claves de firma/encriptación de sesiones, ajustes de cookies (nombre, dominio, path, Secure, HttpOnly, SameSite), formatos de tokens y callbacks de auth. Si necesitas rotar claves, hazlo con solapamiento: green debe aceptar la clave vieja y la nueva para verificación, mientras emite sesiones nuevas con la clave nueva.
¿Cómo manejo migraciones de base de datos sin perder escrituras?
Asume que blue y green pueden escribir en la misma base de datos por un tiempo, así que los cambios de esquema deben ser compatibles hacia atrás. Añade columnas o tablas nuevas primero, despliega código que maneje ambas formas y elimina campos viejos más tarde. Evita migraciones destructivas justo en el momento del corte.
¿Cuándo debo hacer rollback vs arreglar hacia adelante?
Haz rollback cambiando el tráfico de vuelta a blue, no tratando de reconstruir código viejo bajo presión. Decide los triggers de rollback con antelación, por ejemplo: fallos de login, fallos de pago, picos de errores o problemas claros de integridad de datos. Ten cuidado si green ya escribió datos en un formato que blue no puede leer de forma segura.
¿Cómo evito que los trabajos en background se ejecuten dos veces en blue y green?
Si el mismo job programado corre en ambos entornos puede haber duplicados: facturas dobles, notificaciones repetidas, etc. Antes del corte, confirma que solo un conjunto de workers y schedulers ejecutará tareas “únicas” o periódicas durante la transición. Después del corte, verifica que las colas, cron jobs y procesos de webhook apunten a donde esperas.
¿Blue-green ayuda si mi app fue generada por IA y ya es inestable?
El código generado por IA suele tener autenticación frágil, lógica enmarañada y manejo de configuración inconsistente, lo que hace que el comportamiento en producción sea impredecible. Blue-green reduce el radio de daño, pero no arregla problemas fundamentales como migraciones inseguras, secretos hardcodeados o sesiones inconsistentes. Si los despliegues siguen fallando, suele merecer la pena un diagnóstico y limpieza del codebase.