Eliminar constantes mágicas del código generado por IA (de forma segura)
Elimina las constantes mágicas del código generado por IA centralizando límites, URLs y toggles en un solo lugar para que las actualizaciones sean más seguras, rápidas y fáciles de revisar.
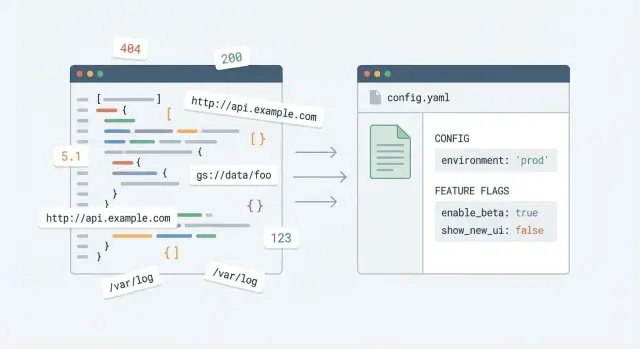
Por qué las constantes mágicas dan problemas en el código generado por IA
Las constantes mágicas son valores esparcidos por el código sin nombre ni explicación. Aparecen como números hardcodeados (como 7 o 10000), URLs pegadas (como un endpoint de API) o cadenas que controlan el comportamiento (como "beta", "admin" o "enabled"). Cuando las ves después, no sabes por qué existe ese valor ni qué se rompe si lo cambias.
Los prototipos generados por IA empeoran esto porque el código suele producirse en pequeños trozos separados. Un componente tiene un timeout, otro tiene otro timeout distinto, y un tercero copia una URL con una ruta ligeramente diferente. La app funciona lo suficiente para una demo, pero la misma regla termina implementada en muchos sitios con pequeñas diferencias.
Por eso quitar constantes mágicas puede parecer arriesgado. Una petición simple como “aumentar el límite de subida de 10MB a 25MB” se convierte en una búsqueda por controladores, componentes de UI, helpers de validación y jobs en background. Si fallas en un sitio, envías un bug que solo aparece en producción.
Normalmente verás los síntomas pronto:
- Comportamiento inconsistente entre páginas (una pantalla permite 25MB, otra bloquea en 10MB)
- Arreglos que funcionan en un flujo pero fallan en otro
- Tests difíciles de escribir porque las reglas están dispersas
- Hotfixes que crean nuevos casos límite mientras los valores divergen con el tiempo
- Reportes de soporte confusos (“a veces funciona”) sin patrón claro
Un ejemplo realista: tu app tiene "https://api.example.com" hardcodeada en el flujo de login, pero otro archivo usa "https://api.example.com/" y un tercero apunta a "https://staging-api.example.com" que quedó de un prompt anterior. Cambias una y la auth sigue fallando para algunos usuarios; ahora persigues fantasmas.
Este es uno de los problemas más comunes que vemos en apps rotas generadas por IA en FixMyMess. El camino más rápido hacia cambios más seguros es hacer que los valores importantes sean aburridos: un nombre, un lugar, una sola fuente de verdad.
Qué cuenta como constante mágica (y qué no)
Una constante mágica es cualquier valor incrustado en el código cuyo significado no es obvio, y cambiarlo después implica buscar archivos y adivinar qué más afecta. En prototipos generados por IA, ese riesgo aumenta porque los mismos valores suelen repetirse en muchos archivos.
¿Qué es una constante mágica?
Suelen aparecer como números mágicos, strings mágicos y URLs hardcodeadas. A menudo son “valores por defecto importantes” que controlan comportamiento sin explicación.
Ejemplos comunes:
- Timeouts como
3000o30(¿milisegundos o segundos?) - Tamaños de paginación como
10,20,50 - Conteos de reintentos como
3o5 - URLs base de API como
https://api.example.com/v1 - Toggles de característica ocultos como
"enableNewCheckout" = true
El problema no es que existan estos valores. El problema es que el código no explica qué significan. Seis semanas después, 3000 parece una suposición, no una decisión.
Por qué un “edición rápida” sale mal
En prototipos generados por IA, la misma constante a menudo se copia y pega en componentes, rutas y helpers. La cambias en un sitio, los tests pasan y luego otra pantalla se rompe porque usaba una copia ligeramente distinta.
Los duplicados ocultos son especialmente feos: timeout = 3000 en un archivo, timeout = 3500 en otro y timeoutMs = 3000 en otro sitio. Esa diferencia puede ser intencional o deriva accidental. En cualquier caso, ahora tienes comportamiento que depende de qué ruta tome el usuario.
Qué NO cuenta como constante mágica
No todo literal necesita convertirse en configuración. Algunos valores están bien inline porque son autoexplicativos y poco probables de cambiar.
Buenos ejemplos no-mágicos:
0o1como contador simple en un bucle404al devolver un status HTTP en un handler- Un valor pequeño de espaciado UI que es claramente local a un componente
Una regla útil: si cambiar el valor debería ser una decisión deliberada de producto (límites, URLs, reintentos, gating), pertenece a un lugar con nombre.
Una forma simple de encontrar y priorizar qué arreglar
Lo difícil no es el cambio en sí. Es elegir por dónde empezar para no crear nuevos bugs.
Empieza con un inventario rápido. Usa la búsqueda del editor para buscar valores repetidos: la misma URL, el mismo timeout, el mismo 10 o 1000, la misma cadena de estado. Si un valor aparece en 5+ sitios, es candidato fuerte. Si aparece en solo 2 sitios pero afecta dinero o login, también es candidato.
Enfócate en el riesgo, no en la perfección. Las constantes que más dañan son las que pueden romper producción o crear problemas de seguridad cuando están mal.
Regla rápida de triage
Ordena lo que encuentres en “arreglar ahora” y “arreglar después”. “Arreglar ahora” suele incluir:
- Auth e identidad: URLs de OAuth, URLs de callback, tiempos de vida de tokens, ajustes de cookies
- Pagos y webhooks: endpoints de proveedores, nombres de secretos de firma, demoras de reintento
- Límites y cuotas: máximas de requests, máximo de subidas, tamaños de paginación
- Timeouts y reintentos: valores de timeout de API, intervalos de jobs en background
- URLs externas base: cualquier cosa que apunte a staging, localhost o un servidor personal
Luego elige un ítem y crea una única fuente de verdad antes de tocar muchos archivos. El código generado por IA suele tener el mismo valor en formas ligeramente distintas, y las ediciones rápidas se vuelven refactors a medias.
Nómbralo para que cualquiera lo entienda
Usa nombres que expliquen la intención. Evita CONST_1 o DEFAULT_VALUE. Prefiere AUTH_TOKEN_TTL_SECONDS o PAYMENTS_WEBHOOK_BASE_URL. Pon unidades en el nombre (segundos vs milisegundos) para que nadie tenga que adivinar.
Ejemplo: si encuentras tres URLs de webhook de Stripe diferentes y dos valores de timeout en handlers, crea PAYMENTS_WEBHOOK_URL y PAYMENTS_API_TIMEOUT_MS en un solo lugar. Luego actualiza los sitios de llamada uno por uno, verificando el comportamiento a medida que avanzas.
Si heredaste un prototipo roto de herramientas como Bolt, v0, Cursor, Lovable o Replit, este suele ser el primer paso de limpieza que hacemos en FixMyMess: centralizar los valores riesgosos y luego hacer el resto de las reparaciones sobre algo estable.
Paso a paso: centralizar límites, URLs y timeouts
El objetivo es simple: poner “cosas que cambian” en un solo lugar con nombres claros, para poder actualizarlas sin buscar en todo el código.
Una forma práctica de hacerlo
Trátalo como una serie de ediciones pequeñas y seguras, no como una reescritura grande.
-
Elige un hogar obvio para la configuración. Crea un módulo único (o archivo) que toda la app pueda importar, como
configosettings. -
Añade nombres legibles y valores por defecto. Prefiere nombres que expliquen propósito, no tipo:
API_BASE_URL,REQUEST_TIMEOUT_MS,MAX_UPLOAD_MB,PASSWORD_MIN_LENGTH. Usa defaults seguros para que las ejecuciones locales no fallen. -
Reemplaza literales gradualmente. Elige una carpeta o feature, cambia literales por valores de config, haz commit y continúa. Los pasos pequeños son más fáciles de revisar y deshacer.
-
Haz una comprobación ligera después de cada bloque. Ejecuta la app y prueba lo que tocaste (login, subida, checkout). Si tienes tests, ejecútalos. La idea es feedback rápido.
-
Mantén los commits enfocados. Un commit para “centralizar timeouts”, otro para “centralizar URLs de API”. Así es más fácil detectar errores (segundos vs milisegundos).
Un ejemplo pequeñísimo que previene bugs futuros
Imagina que tu app llama https://api.example.com en cinco archivos, y cada uno usa un timeout distinto: 2000, 5000, 15_000. Tras centralizar, pones API_BASE_URL y REQUEST_TIMEOUT_MS una sola vez. La próxima vez que cambies a un servidor de staging o necesites timeouts mayores en picos, cambias un archivo, no cinco.
Dónde guardar la configuración: env vars, archivos de config y defaults
Una vez que sacas valores del código, necesitas un hogar claro. El objetivo: una fuente de verdad fácil de cambiar y segura para enviar a producción.
Qué va en env vars vs defaults en código
Las variables de entorno son mejores para valores que cambian entre entornos o que no deberían vivir en el repo. Los defaults en código sirven para valores no secretos que facilitan el setup local.
Una división práctica:
- Variables de entorno: API keys, secretos de auth, URLs de bases de datos, endpoints de servicio privados, secretos de webhooks de terceros
- Archivos de config (en repo): settings no secretos como disponibilidad de features, URLs públicas conocidas, defaults de paginación, conteos de reintento
- Defaults en código: valores de fallback que mantienen la app en marcha si falta un setting (nunca para secretos)
Si un valor puede romper producción o exponer datos, prefiere env vars. Si es solo un default sensato (como PAGE_SIZE=20), un default en código está bien.
Manejar local, staging y producción sin sorpresas
Muchos prototipos generados por IA hardcodean “el único entorno” que el autor probó. En su lugar, haz la config consciente del entorno: local usa variables locales (o un .env local), staging usa sus propios settings de despliegue y producción usa secretos bloqueados.
Mantén reglas predecibles:
- Mismas claves de configuración en todos lados (solo cambian los valores)
- Fallar rápido si faltan secretos requeridos en staging/producción
- Permitir defaults solo para valores no sensibles
Por ejemplo, puedes permitir REQUEST_TIMEOUT_MS=8000 por defecto en local, pero requerir DATABASE_URL y JWT_SECRET antes de que la app arranque en staging o producción.
No mezcles la carga de configuración con la lógica de la app
Un error común es esparcir lecturas de process.env... por todo el código. Eso convierte la configuración en lógica oculta.
En su lugar, carga y valida la configuración una vez al inicio (en un módulo) y pasa esa config a las partes de la app que la necesiten.
Toggles de función que no se vuelven un desastre
Los feature toggles son interruptores simples que te permiten desplegar código sin exponerlo a todos los usuarios. En código generado por IA, los toggles suelen aparecer como booleanos aleatorios dispersos por los archivos, que es otra forma de constante mágica.
Un buen toggle responde a una pregunta en lenguaje llano: “¿Deben los usuarios ver X?”. Para despliegues riesgosos esto es útil. Puedes lanzar un nuevo flujo de signup a un subconjunto de usuarios o mantener una nueva página de precios ocultas hasta su aprobación. La clave es que voltear el toggle cambie el comportamiento sin editar varios archivos bajo presión.
Nomenclatura y estructura que siga siendo legible
Elige un estilo de nombres consistente y mantenlo. Lo descriptivo vence a lo corto. enableNewSignupFlow es mejor que flag2 porque cualquiera puede adivinar qué hace durante un hotfix.
Mantén los toggles en un solo lugar (tu módulo de config o archivo de settings). Si el valor debe variar por entorno, mapea a una variable de entorno, pero expónlo siempre a través del mismo objeto de configuración para que el resto de la app no le importe de dónde vino.
Algunas reglas que previenen la proliferación de toggles:
- Prefiere nombres
enableXouseXque coincidan con comportamiento visible para el usuario - Un toggle por feature, no por archivo
- Añade una fecha de expiración o nota de eliminación para toggles temporales
- Por defecto, apagar cambios riesgosos
Decide quién puede voltear el interruptor
Los toggles pueden causar daño real si cualquiera los cambia a la ligera. Decide quién puede cambiarlos y cómo se revisan los cambios.
Ejemplo: tu app generada por IA tiene una nueva página de checkout detrás de un toggle. Un stakeholder pide apagarla tras un pico de tickets. Si el toggle está centralizado, puedes cambiar un valor y tener confianza de que no perdiste una copia oculta del mismo boolean.
Un ejemplo realista: un cambio, un lugar
Piensa en una startup que lanzó rápidamente un prototipo generado por IA. Funciona en demos, pero el código tiene los mismos valores copiados por todo: URLs de API, timeouts, límites y un switch “nuevo checkout”.
Antes: cambio pequeño, muchas ediciones riesgosas
Necesitas apuntar la app de la API de staging a producción. Buscas https://api-staging... y la encuentras en seis archivos: fetch en frontend, un cliente backend, un handler de webhook y un job de background. Los cambias todos, lo subes y luego descubres que un archivo aún apunta a staging. La mitad de la app lee datos viejos.
Luego llega tráfico real. Tu rate limit debe pasar de 10 a 50 requests por minuto y un timeout de 2s a 8s. Esos números están dispersos y en un sitio usan milisegundos y en otro segundos. Un ajuste simple se vuelve un juego de adivinanzas.
Finalmente, aparecen errores en una nueva feature. El código de la IA agregó ENABLE_NEW_CHECKOUT = true en dos módulos distintos. Pones uno en false, pero los usuarios siguen viendo el camino roto porque el otro constante sigue true.
Así suele lucir ese patrón desordenado:
// auth.js
const API_BASE_URL = "https://api-staging.example.com";
// orders.js
fetch("https://api-staging.example.com/orders", { timeout: 2000 });
// worker.js
const TIMEOUT_MS = 2000;
const RATE_LIMIT = 10;
// checkout.js
const ENABLE_NEW_CHECKOUT = true;
Después: una actualización de config
Tras centralizar, el resto de la app importa desde un módulo de config (y usa variables de entorno cuando tiene sentido):
// config.js
export const config = {
apiBaseUrl: process.env.API_BASE_URL ?? "https://api.example.com",
timeoutMs: Number(process.env.TIMEOUT_MS ?? 8000),
rateLimitPerMin: Number(process.env.RATE_LIMIT ?? 50),
features: {
newCheckout: process.env.FEATURE_NEW_CHECKOUT === "true",
},
};
// orders.js
fetch(`${config.apiBaseUrl}/orders`, { timeout: config.timeoutMs });
Ahora “cambiar la URL base de la API” significa actualizar una variable de entorno, no editar media base de código. “Subir el timeout” significa cambiar un número con una unidad clara. “Desactivar la nueva feature” significa voltear una sola bandera rápidamente cuando algo falla.
Errores comunes y trampas a evitar
El objetivo es seguridad: menos ediciones riesgosas, menos sorpresas, cambios más sencillos después. La mayoría de problemas ocurren cuando el refactor parece ordenado pero el comportamiento cambia en silencio.
Un tropiezo común es renombrar una constante y no actualizar todos los usos. Esto ocurre mucho en proyectos escritos por IA donde el mismo valor está duplicado bajo nombres ligeramente distintos. La app sigue compilando, pero un límite, URL o timeout queda inconsistente.
Varios archivos de config es otra trampa. Empieza como “uno para server, uno para client” y termina en tres o cuatro archivos que divergen. Cuando cambia un valor, la mitad del equipo actualiza el archivo A y olvida el B.
También fíjate en valores de fallback “útiles” que silenciosamente sobreescriben env vars. Los defaults están bien, pero solo si son obvios y seguros. Si tu código hace “usa ENV si existe, si no usa esta URL de producción hardcodeada”, puedes enviar un build que hable con el backend equivocado.
Errores que suelen morder más fuerte:
- Renombrar constantes y no actualizar cada import y uso, dejando comportamiento dividido
- Crear varias fuentes de config (múltiples archivos, patrones distintos) que se separan con el tiempo
- Hardcodear valores de fallback que silenciosamente prevalecen sobre las env vars, especialmente en builds de producción
- Tratar secretos como constantes normales (API keys en archivos de constantes, o
.envcomiteado) - Sobre-abstraer temprano con capas de config que nadie entiende durante una caída
Si heredaste un prototipo generado por IA y no estás seguro si tu refactor cambió comportamiento, esto es exactamente lo que FixMyMess audita: duplicados ocultos, defaults inseguros y secretos mezclados en archivos de constantes.
Lista rápida antes de enviar el refactor
Tras centralizar constantes, la app puede verse más limpia pero aún ocultar huecos riesgosos. Usa esta comprobación rápida antes de mergear.
Comprobación de configuración
Haz una prueba de “cambio único”. Elige un valor que esperas cambiar después (como la URL base de la API), actualízalo una vez y confirma que la app usa el nuevo valor en todas partes. Si aún tienes que buscar en varios archivos, no lo centralizaste realmente.
También asegúrate de que no haya secretos mezclados con settings normales. Tu config puede incluir defaults seguros, pero todo lo sensible (API keys, contraseñas de DB, JWT secrets) debe venir solo de variables de entorno. Si un secreto está en el repo, asume que se filtrará tarde o temprano.
Lista previa al envío:
- Cambia una configuración clave (URL base de API, URL de webhook o host de CDN) en un lugar y verifica que toda la app la siga.
- Busca literales sobrantes que deberían tener nombre (timeouts como
30000, límites como50, reintentos como3). - Confirma que límites y timeouts están nombrados claramente y explicados con un comentario corto (qué protege y por qué ese número).
- Confirma que los feature toggles tienen un responsable, un default seguro y un plan de eliminación si son temporales.
- Ejecuta una prueba de humo: inicia sesión, recorre las pantallas principales y activa al menos un camino de error (contraseña errónea, registro faltante, modo offline).
Comprobación final “romper vidrio”
Durante la prueba de humo, mira los logs o la consola. Si ves una env var faltante, una URL de fallback inesperada o un toggle por defecto mal, arréglalo antes de enviar.
Si heredaste un prototipo frágil generado por IA y no sabes qué más está hardcodeado o es inseguro, FixMyMess (fixmymess.ai) puede empezar con una auditoría de código gratuita para localizar constantes riesgosas, secretos expuestos y patrones de configuración que suelen fallar en producción.
Próximos pasos: mantenerlo limpio a medida que la app crece
La verdadera victoria es evitar que las constantes mágicas se reinfiltren. Los equipos pequeños mueven rápido y “solo un número más hardcodeado” es la forma en que terminas con ediciones dispersas y riesgosas otra vez.
Un siguiente paso práctico es un sprint corto de limpieza enfocado en las constantes que realmente te afectan. No intentes arreglar todo. Elige las 10–20 valores que cambian con frecuencia o que pueden romper producción si están mal (timeouts, límites de tasa, URLs base, umbrales de precios, tamaños de subida), centralízalos y haz despliegues en pequeños lotes.
Haz una regla ligera de equipo: los nuevos valores importantes necesitan un nombre y un lugar. Si no es claramente un caso único (como un índice de bucle), pertenece a tu módulo de config o constants.
Si tu base de código fue generada por IA y se siente frágil, una auditoría experta antes de refactors más profundos puede ahorrar mucho tiempo. Estos proyectos a menudo esconden constantes riesgosas junto a problemas mayores como secretos expuestos, flujos de auth rotos o consultas a la base de datos inseguras.
Preguntas Frecuentes
¿Qué es una “constante mágica” en una app generada por IA?
Una constante mágica es un valor incrustado con significado u impacto poco claro, como 3000, "enabled" o una URL pegada. Si cambiarla después implica buscar en todo el código y adivinar qué se rompe, es una constante mágica.
¿Por qué los prototipos generados por IA terminan con tantas constantes duplicadas?
Las herramientas de IA suelen generar código en fragmentos separados que no comparten una única fuente de configuración. La misma regla (timeouts, límites, URLs) se copia en varios archivos con pequeñas diferencias, así que un “cambio simple” se vuelve un comportamiento inconsistente.
¿Cuándo debo dejar un valor inline en lugar de convertirlo en configuración?
Si el valor es estable, obvio y local a un solo punto, déjalo inline. Si controla comportamiento del producto a través de flujos (límites, URLs base, reintentos, ajustes de auth, switches de funciones), centralízalo para poder cambiarlo con seguridad.
¿Cuál es la forma más rápida de encontrar qué constantes vale la pena arreglar primero?
Empieza buscando literales repetidos: la misma URL, el mismo número de timeout, el mismo límite o la misma cadena mágica. Prioriza todo lo relacionado con login, pagos, webhooks, subidas, límites de tasa y endpoints de entorno, aunque aparezca pocas veces.
¿Cómo centralizo constantes sin romper todo?
Crea un módulo de configuración obvio (o un archivo) y mueve valores allí en pequeñas tandas. Sustituye literales por feature, ejecuta una prueba rápida después de cada lote y mantén los cambios fáciles de revisar y revertir.
¿Cómo debo nombrar las constantes para que no confundan después?
Incluye intención y unidades en el nombre para que nadie tenga que adivinar más tarde. Nombres como REQUEST_TIMEOUT_MS, MAX_UPLOAD_MB y AUTH_TOKEN_TTL_SECONDS previenen errores comunes, especialmente milisegundos vs segundos.
¿Qué debe ir en variables de entorno vs valores por defecto en el código?
Usa variables de entorno para secretos y valores que difieren por entorno, como URLs de base de datos, API keys, JWT secrets y endpoints privados. Mantén defaults seguros en el código para que el setup local funcione sin sorpresas.
¿Por qué es mala idea leer variables de entorno por todo el código?
Lee y valida las env vars una sola vez al inicio y exporta un único objeto de configuración. Si esparces process.env por toda la app, crearás diferencias de comportamiento ocultas y será más difícil testear y razonar sobre cambios.
¿Cómo manejo los feature toggles sin crear otro desorden?
Mantén los toggles en el mismo módulo de configuración y nómbralos por comportamiento visible al usuario, p. ej. enableNewCheckout. Pon por defecto off para cambios riesgosos y evita duplicar el mismo boolean en varios módulos, lo que hace que los rollbacks sean poco fiables.
¿Qué debo revisar antes de lanzar un refactor para quitar constantes mágicas?
Cambia una configuración clave (como la URL base de la API) en un solo lugar y confirma que todos los flujos la usan. Luego busca duplicados hardcodeados, confirma que no hay secretos comprometidos y recorre rutas críticas (login, subida, checkout) para detectar desajustes.