Redacta PII en logs: enmascarar correos, tokens e IDs
Redacta PII en logs con patrones prácticos para enmascarar correos, tokens e IDs y poder depurar sin exponer datos de usuarios.
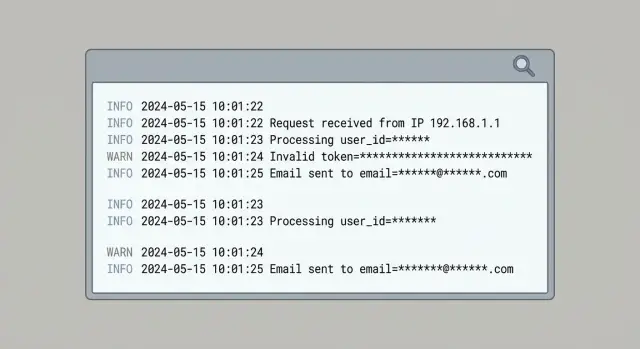
Qué cuenta como PII en los logs (y por qué sigue apareciendo)
PII (información personal identificable) es cualquier dato que puede identificar a una persona por sí solo, o que se vuelve identificable al combinarse con otros datos que ya tienes. En logs y analytics, eso suele incluir direcciones de correo, números de teléfono, nombres, direcciones de domicilio o facturación y direcciones IP. También incluye identificadores “técnicos” que en la práctica suelen apuntar a una sola persona: IDs de usuario, IDs de dispositivo, advertising IDs, IDs de sesión, cookies y ubicación precisa.
La PII aparece porque el logging suele añadirse bajo presión, especialmente cuando algo está roto. El atajo común es “loguear el objeto entero” y limpiarlo más tarde. Ese “objeto entero” tiende a incluir campos que nunca pensaste almacenar.
Los puntos de entrada típicos son cuerpos de petición (registro, restablecimiento de contraseña, mensajes de soporte), headers (tokens de Authorization, cookies y a veces el correo en headers personalizados), objetos de error (pueden incluir la petición original o datos de usuario serializados), query strings (parámetros de tracking, correos pegados en URLs) y payloads de SDKs de terceros que capturan automáticamente información de dispositivo y red.
Los eventos de analytics repiten el mismo riesgo. Los equipos copian campos de los logs del servidor en eventos como user_email, session o propiedades de “debug” para facilitar gráficos. Esos eventos luego se propagan a múltiples proveedores y paneles, ampliando el radio de impacto de un solo error.
La redacción (redaction) vence al “ten cuidado” porque el modo de fallo es predecible: se despliega un nuevo endpoint, alguien añade un log de depuración o una librería cambia lo que serializa. Trata la redacción como una capa de seguridad por defecto, no como una preferencia del desarrollador.
Decide qué necesitas conservar realmente para depurar
Antes de redactar nada, aclara para qué sirven tus logs. La mayoría de equipos recoge mucho más de lo que usa, y ese detalle extra es donde se esconden correos, tokens y headers sin procesar.
Apunta las preguntas específicas que esperas que los logs respondan durante un incidente. Si una línea de log no ayuda a responder una de esas preguntas, es buena candidata para eliminarse o reducirse.
La mayoría de las necesidades de depuración se reducen a unos básicos: qué falló y cuándo, qué endpoint/versión se llamó, si la falla ocurrió antes o después de la autenticación, si una dependencia causó el error y si múltiples fallas pertenecen a la misma petición o sesión.
A partir de ahí, define una forma "mínima útil" de log en la que puedas confiar en todas partes: timestamp, un request ID (o trace ID), nombre de ruta, código de estado y un código de error interno. Añade un contexto pequeño y controlado como flags de características o un nombre corto de componente. Evita volcar objetos enteros.
Mantén las necesidades de soporte de usuario separadas de las de ingeniería. Soporte a menudo necesita encontrar a un usuario y entender el impacto, pero eso no requiere almacenar el correo en cada evento. Un patrón más limpio es guardar una clave interna estable de usuario en los logs y dejar la búsqueda de usuario dentro de un sistema de administración seguro.
Algunas cosas nunca deberían registrarse, ni siquiera “temporalmente”: contraseñas y códigos de un solo uso, tokens completos y claves de API, cookies de sesión, headers Authorization sin procesar y cuerpos completos de request/response.
Ejemplo: si los usuarios reportan “Login failed”, puedes loguear request_id=abc123, route=/login, status=401, error=AUTH_INVALID_TOKEN, auth_stage=post-parse. Eso es suficiente para depurar sin registrar el token.
Patrones de enmascaramiento para direcciones de correo
Los correos aparecen en logs porque son fáciles de capturar: formularios de registro, restablecimiento de contraseña, invitaciones, tickets de soporte y errores de “usuario no encontrado”. Si quieres redactar PII en logs sin perder valor para depurar, conserva solo lo necesario para detectar patrones (como el dominio) sin exponer la dirección completa.
Un valor predeterminado seguro es conservar el dominio y solo una pequeña pista de la parte local, por ejemplo j***@example.com o jo***@example.com. Eso suele bastar para notar “las fallas se agrupan en example.com” sin filtrar identidades.
El direccionamiento con "plus" requiere cuidado. [email protected] y [email protected] suelen ser el mismo buzón. Si enmascaras de forma ingenua, puedes tratar a una misma persona como usuarios distintos. Normaliza antes de enmascarar: pasa la dirección a minúsculas, elimina el +tag y luego aplica tu máscara.
Si necesitas correlación estable entre eventos, prefiere un hash con clave en lugar de una revelación parcial: hash(email) + "@" + domain. Usa un secreto de aplicación (un pepper) para que el hash no pueda invertirse desde una lista de correos comunes. Nunca registres el correo sin procesar junto al hash.
El texto libre es la mayor fuente de fugas: mensajes de excepción, prints de depuración y cuerpos de request copiados. Añade un paso de escaneo y reemplazo en tu logger para que los correos se limpien incluso cuando aparezcan dentro de oraciones.
Opciones comunes que siguen siendo útiles:
- Dominio + primeros 1-2 caracteres locales:
ma***@gmail.com - Dominio + solo longitud local:
[email protected] - Hash con clave + dominio:
a9f3c1…@example.com - Reemplazo completo cuando el riesgo es alto:
[REDACTED_EMAIL]
Pase lo que pases, aplícalo en un solo lugar (un helper de logging compartido) para que sea consistente entre servicios y analytics.
Patrones de enmascaramiento para tokens, claves API e IDs de sesión
Los secretos se filtran porque están en lugares “aburridos” que los ingenieros registran sin pensar: el header Authorization, cookies, query strings y campos JSON como token, apiKey, sessionId o csrf. La regla es simple: nunca registres secretos sin procesar, ni siquiera en errores.
Diferentes secretos requieren distinto tratamiento. Las claves API suelen ser de larga duración y deben tratarse como contraseñas. Los JWT pueden contener claims legibles, así que registrarlos puede filtrar correos o IDs de usuario. IDs de sesión y tokens CSRF pueden ser de corta vida, pero aún permiten secuestro de sesión.
Un patrón práctico es conservar lo suficiente para correlacionar eventos:
- Prefijo + sufijo: conserva los primeros 4 y los últimos 4 caracteres
- Solo longitud: registra
len=32cuando no se necesita correlación - Etiquetas de tipo:
kind=jwtokind=api_keypara parsing/depuración - Hash estable: un hash unidireccional cuando necesitas coincidencia consistente
Haz tu redactor resistente a cadenas del mundo real. Los secretos aparecen como Bearer \u003ctoken\u003e, pero también dentro de mensajes concatenados, sin espacios o con mayúsculas extrañas. Redacta por patrón, no por “formato bonito”.
Aquí tienes un ejemplo simple de antes/después:
BEFORE error=\"upstream 401\" Authorization=\"Bearer eyJhbGciOi...\" cookie=\"sid=s%3A0f1a9...\" query=\"?api_key=sk_live_ABC123...\"\nAFTER error=\"upstream 401\" Authorization=\"Bearer eyJh...9Q2w\" cookie=\"sid=\u003credacted len=48\u003e\" query=\"?api_key=sk_l...8xKQ\"\n```
(El bloque anterior está intacto para mantener el ejemplo técnico exacto.)
## Manejo de IDs de usuario, IDs de dispositivo y otros identificadores
No todos los IDs son inofensivos. Si un identificador puede enlazarse a una persona real (directamente, o combinándolo con otros datos), trátalo como datos personales. Eso incluye muchos campos "internos" como `user_id`, `account_id`, `device_id`, `ip_address` y IDs de cookies “anónimas” si persisten en el tiempo.
Una regla útil: si puedes usarlo para encontrar a una persona en tu base de datos, asúmelo como sensible.
### Prefiere IDs estables y no reversibles para depurar
Aún necesitas conectar eventos durante un incidente. El patrón más seguro es una representación estable pero no reversible, como un hash salado. Obtienes correlación repetible sin exponer el valor original.
Por ejemplo, en lugar de registrar `user_id=483920`, registra `user_key=hash(tenant_salt + user_id)`. Mantén la salt fuera de los logs, rótala si es necesario y usa salts separadas por entorno.
Para mantener los logs útiles, incluye campos de correlación que no estén ligados a una persona: `request_id` para una sola petición, `trace_id` para seguir una llamada entre servicios, una `session_key` de corta vida que expire rápido y `tenant_id` cuando identifica a una organización en lugar de a un individuo.
Las apps multi-tenant necesitan cuidado adicional. Un `tenant_id` suele ser seguro si representa a una compañía o espacio de trabajo, no a un único usuario. No hashes user IDs globalmente entre todos los tenants. Usa `hash(tenant_id + user_id)` para que los identificadores no puedan emparejarse entre tenants.
## Logs estructurados vs no estructurados (y cómo redactar cada uno)
Los logs no estructurados son donde la PII se cuela con más frecuencia. Un `console.log(user)` rápido o un error que incluye headers de la petición puede volcar correos, tokens e IDs en una sola línea desordenada. Una vez enviado a una herramienta de logs, es difícil limpiarlo después.
El logging estructurado (normalmente JSON) hace que la redacción sea predecible. En lugar de adivinar con regex en toda la línea, puedes apuntar a campos específicos como `user.email`, `auth.token` o `request.headers.authorization`.
Redacta a nivel de campo primero y luego usa regex como respaldo para texto libre. La redacción solo por regex en líneas completas falla en casos límite y también puede sobrereditar, lo que dificulta la depuración.
Un enfoque práctico es registrar metadatos estables (endpoint, status, feature flag, código corto de error), mantener la "forma" sin el contenido (longitud de token, dominio de email, últimos 4 caracteres) y separar el texto libre en `message` más `context` estructurado. Luego añade un paso final de limpieza para cualquier cadena restante que parezca email o token.
Hazlo fácil con una única utilidad `redact()` y úsala en todas partes (logs, reporte de errores, analytics). Si equipos diferentes implementan sus propias reglas, acabarás perdiéndote algo.
```js
export function redact(value) {
if (value == null) return value;
const s = String(value);
// emails
const email = s.replace(/[A-Z0-9._%+-]+@([A-Z0-9.-]+\\.[A-Z]{2,})/gi, "\u003credacted:@$1\u003e");
// bearer tokens / api keys (best-effort)
return email.replace(/\\b(Bearer\\s+)?[A-Za-z0-9-_]{20,}\\b/g, "\u003credacted:token\u003e");
}
(El bloque JS anterior se mantiene exactamente como en el original.)
Paso a paso: añade redacción a tu pipeline de logging
La redacción funciona mejor cuando es automática. El objetivo es eliminar valores sensibles antes de que anything salga de la aplicación en ejecución, así no dependes de una configuración de proveedor o de un job de limpieza posterior.
Empieza listando todos los lugares donde se crean logs y eventos. Los equipos recuerdan el servidor API y luego olvidan el worker, el reverse proxy, el cliente móvil o un reportero de errores en el navegador.
A continuación, define un “mapa de redacción”: nombres de campo que nunca quieres enviar (como email, authorization, cookie, set-cookie, password, token) más reglas basadas en patrones para texto libre desordenado.
Luego añade una capa de redacción justo antes de exportar, idealmente en una función compartida para que sea difícil eludirla. Mantén el despliegue controlado: añade tests, implanta gradualmente y verifica que la depuración sigue funcionando.
Demuéstralo con tests, no con esperanza
Usa fixtures desordenados: una petición con Authorization: Bearer ..., un body JSON que contenga email y una URL que incluya un token de restablecimiento. Tus tests deben confirmar que las partes sensibles son reemplazadas mientras que el contexto restante sigue explicando lo ocurrido.
Redactar PII en eventos de analytics sin perder perspectiva
Analytics filtra los mismos tipos de datos que los logs: URLs, referrers, valores de formularios y mensajes de error. La diferencia es dónde acaban. Los datos de analytics se copian a más sitios y a menudo se conservan más tiempo.
Un valor predeterminado sólido: envía menos, pero envíalo de forma consistente. Reemplaza propiedades de usuario por un ID seudónimo y añade solo atributos agregados que realmente uses (nivel de plan, versión de app, país, tipo de dispositivo). Aún puedes responder preguntas de producto sin enviar identificadores crudos.
Los patrones son familiares: evita email/teléfono/nombre completo como identificadores, resume cadenas sensibles (presente/no presente, longitud o categoría), elimina query strings y fragments de URLs y, para errores, envía un código y categoría en lugar de payloads completos que puedan contener entrada del usuario. Si debes correlacionar, haz hash con una salt secreta y nunca envíes el valor sin procesar.
Las URLs crudas son una fuga común. Los enlaces de restablecimiento pueden incluir token=..., invitaciones pueden llevar el correo en la query y esos valores pueden capturarse como propiedades de vista de página.
Un evento de signup normalmente no necesita [email protected]. Típicamente requiere signup_method=email, opcionalmente email_domain=company.com y si la confirmación fue exitosa.
Errores comunes que todavía filtran PII
La mayoría de las filtraciones no se deben a una regla de redacción “mala”. Ocurren porque alguien necesitó más detalle durante un incidente o porque un camino de código registra de forma diferente al resto.
Modo incidente que nunca se apaga
Un fallo clásico es activar el logging completo de peticiones durante una caída (bodies, headers, query strings), arreglar el bug y olvidar quitar el logging extra. Semanas después, los logs contienen contraseñas en payloads, bearer tokens en headers y correos en parámetros de query.
La redacción ayuda, pero no puede salvarte si sigues recopilando mucho más de lo necesario.
Redacción demasiado estrecha o inconsistente
Enmascarar solo un campo email no es suficiente. La PII aparece bajo diferentes claves y formas anidadas, y se filtra desde lugares que la gente olvida: workers, jobs en background, logging del lado cliente y reporte de errores.
Si quieres una promesa end-to-end, las mismas reglas deben ejecutarse en todos los puntos donde se generan logs y deben tener tests que incluyan entradas reales y desordenadas.
Lista rápida antes de desplegar
Haz una pasada final con un objetivo simple: conservar suficiente detalle para depurar qué pasó y dónde, sin almacenar secretos ni identificadores directos.
- Busca los peores culpables: contraseñas, headers Authorization, cookies y tokens completos. Si necesitas prueba de que existe un token, registra solo una huella corta (primeros 6 y últimos 4) o un hash unidireccional.
- Asegúrate de que direcciones de correo y teléfonos estén enmascarados en todas partes, incluyendo texto libre y stack traces.
- Reemplaza identificadores de usuario por IDs anónimos (o hazles hash con una salt estable) para poder seguir un solo recorrido sin exponer el valor original.
- Revisa eventos de analytics en busca de identificadores crudos y URLs completas. Las query strings suelen llevar tokens de restablecimiento, códigos de invitación o pistas de sesión.
- Añade tests automatizados que ejecuten payloads comunes (registro, login, restablecimiento de contraseña, fallos de webhooks) a través de tu logger y verifiquen que la salida no contenga secretos.
Un control rápido: desencadena un login fallido en staging y mira la línea de log exacta. Si contiene un correo, una cookie o un header de auth, no has terminado.
Próximos pasos: verifica qué se está filtrando y arréglalo rápido
Empieza con pruebas. Escanea logs recientes y payloads de analytics para encontrar lo que realmente aparece: patrones de correo, cadenas tipo token, nombres completos, direcciones, IPs y volcados de debug que se volvieron permanentes.
Una vez que veas repeticiones, trátalas como backlog. Arregla primero las fuentes de mayor riesgo (auth, restablecimiento de contraseña, registro, facturación, formularios de soporte) y luego ve hacia afuera. Detén nuevas filtraciones antes de preocuparte por limpiar datos antiguos.
Si heredaste una base de código generada por IA, este trabajo suele avanzar rápido porque los puntos de fuga se repiten en archivos (volcados completos de peticiones, headers, cookies, variables de entorno). Arréglalo una vez en el límite de logging y eliminarás clases enteras de errores.
Si necesitas ayuda externa, FixMyMess (fixmymess.ai) se centra en diagnosticar y reparar apps generadas por IA, incluyendo endurecer logging, arreglar flujos de auth rotos y hardening de seguridad para que los prototipos sean seguros en producción.