Errores SSL en la base de datos solo en producción: solucionar desajustes de modo SSL
Los errores SSL que aparecen solo en producción suelen deberse a modos SSL desajustados o certificados faltantes. Aprende los errores comunes en la cadena de conexión y cómo probarlo localmente.
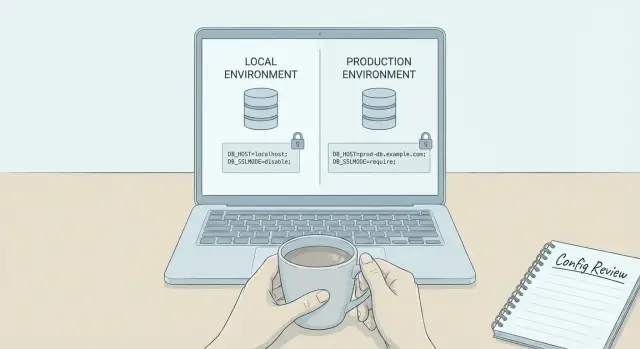
Por qué los errores SSL de la base de datos aparecen solo en producción
Los errores SSL que solo aparecen en producción suelen significar que tu app no se está conectando al mismo tipo de instalación de base de datos que tienes localmente. El código puede ser idéntico, pero en producción cambian las reglas sobre redes y seguridad.
En un portátil, Postgres suele ejecutarse en localhost, a veces dentro de Docker, y se permiten conexiones TCP sin cifrar. En producción, un servicio de Postgres gestionado normalmente está detrás de un balanceador, proxy o pooler de conexiones, exige cifrado y espera un sslmode específico.
Cuando una base de datos alojada dice “SSL required”, te está diciendo que rechazará conexiones no cifradas. Algunos proveedores van más allá y requieren validación de certificados, no solo cifrado. Ahí es donde importan ajustes como sslmode=require frente a sslmode=verify-full: require cifra la conexión, mientras que verify-full también verifica el certificado del servidor y confirma que el hostname coincide.
Aunque no cambies código, el comportamiento puede diferir porque la configuración y los valores por defecto son distintos. Tu .env local puede no incluir parámetros SSL, mientras que las variables de entorno en producción sí las incluyen (o tu plataforma las inyecta). Algunos drivers por defecto usan prefer (intentar SSL y luego degradar), lo que puede funcionar localmente pero fallar cuando producción exige verificación estricta.
Los detalles de red también cambian. Las conexiones en producción suelen pasar por un proxy, PgBouncer o un endpoint privado. Eso puede cambiar el hostname al que te conectas y el certificado que se presenta. Una cadena de conexión que usa una IP puede funcionar con require pero fallar con verify-full, porque los certificados rara vez coinciden con IPs crudas.
Síntomas típicos incluyen errores como:
- “SSL is required” o “no pg_hba.conf entry for host ... SSL off”
- “certificate verify failed”, “unable to get local issuer certificate”, o “self signed certificate”
- “hostname mismatch” o “certificate does not match host”
- Funciona localmente y en preview, pero falla al desplegar en la base de datos de producción
- Fallos intermitentes cuando hay un pooler o proxy en la ruta
Un ejemplo realista: localmente te conectas a postgres://localhost:5432/app sin ajustes SSL. En producción, tu base de datos gestionada proporciona una URL como postgres://user:[email protected]:5432/app?sslmode=verify-full. Si tu app elimina el parámetro (o usa sslmode=disable), producción rechazará la conexión aunque las mismas consultas funcionaran en casa.
Primeros 10 minutos: obtén el error exacto y el contexto
El camino más rápido a una solución es dejar de adivinar y capturar la falla exacta. Los pequeños detalles en el mensaje, el host y dónde corre el código suelen apuntar directo al desajuste.
Copia el texto completo del error, incluidas las líneas de “caused by”, y anota la ventana temporal exacta. Si tienes logs centralizados, filtra alrededor de ese timestamp para ver qué ocurrió justo antes de la falla.
A continuación, apunta dónde se abre la conexión. Una conexión creada durante una petición web puede comportarse distinto a una creada en un worker en segundo plano, una función serverless o un job programado. También verifica si falla inmediatamente o sólo después de un periodo. “Funciona un rato y luego cae” suele indicar pooling, timeouts o algo que rota (certificados, rutas o endpoints).
Captura estos básicos antes de cambiar nada:
- Texto de error completo y stack trace (el primer error, no el último retry)
- Ventana temporal y el ID de la petición o del job (si disponible)
- Ubicación de ejecución (servidor web, serverless, cron, worker)
- Si falla de inmediato o tras algunas consultas exitosas
- El host de base de datos al que realmente se está conectando
Ese último punto importa mucho. Muchas apps tienen múltiples URLs de base de datos por ahí (variables de entorno, gestores de secretos, defaults hardcodeados, entornos de preview). Registra el host resuelto en tiempo de ejecución (sin loguear credenciales). Si producción se conecta a un host distinto del que crees, sus requisitos SSL y certificados pueden ser distintos también.
También comprueba si falla en todas las regiones de producción o solo en una. Un fallo de una sola región puede significar un endpoint distinto, una ruta de red distinta o una cadena de certificado distinta.
Modos SSL en lenguaje llano (y por qué importan)
La mayoría de los fallos SSL que aparecen solo en producción se reducen a un desacuerdo sobre cuán estricta debe ser la conexión. Las bases de datos locales suelen permitir no-SSL o SSL “mejor esfuerzo”. Postgres gestionado comúnmente exige SSL.
El SSL hace dos cosas distintas, y ayuda separarlas:
- Cifrado: mantiene el tráfico privado para que otros no puedan leer contraseñas o datos en tránsito.
- Verificación de identidad: prueba que estás hablando con el servidor de base de datos real.
El “modo SSL” controla cuán estricto eres respecto a esas dos funciones.
Los modos SSL comunes
En drivers y herramientas de Postgres verás normalmente:
- disable: nunca usar SSL
- prefer: intentar SSL primero, pero caer a no-SSL si SSL falla
- require: usar siempre cifrado SSL, pero no probar estrictamente la identidad del servidor
- verify-ca: usar SSL y confirmar que el certificado encadena a una CA de confianza
- verify-full: usar SSL, validar la CA y verificar que el hostname coincide con el certificado
Si fijas un modo estricto como verify-full sin la cadena de certificados o el hostname correcto, puedes seguir obteniendo errores SSL aunque “esté cifrado”.
Validación de hostname: la ruptura habitual en producción
La validación de hostname exige que el certificado del servidor coincida con el host al que te conectas. Si tu cadena usa una dirección interna, una IP o un nombre DNS distinto al que figura en el certificado, verify-full fallará. Esto pasa a menudo cuando producción te enruta a través de un proxy o endpoint privado.
Los valores por defecto difieren según el driver (y eso importa)
Los valores por defecto de los drivers varían. Uno puede comportarse como prefer, otro como require, y tu proveedor cloud puede rechazar no-SSL de plano.
Antes de cambiar nada, responde:
- ¿Producción fuerza SSL o permite no-SSL?
- ¿Estás usando
requireoverify-full? - Si usas
verify-full, ¿coincide el host de la cadena de conexión con el certificado? - ¿De dónde viene el certificado CA en producción (archivo, variable de entorno, store de confianza del sistema)?
- ¿Tu entorno local está probando realmente el mismo modo, o está degradando silenciosamente?
Errores típicos en las cadenas de conexión que causan fallos
Los problemas SSL en producción suelen ser pequeñas discrepancias entre lo que la base de datos espera y lo que tu app envía.
1) Nombre de parámetro incorrecto para tu driver
Diferentes drivers leen distintos ajustes SSL. Algunos buscan sslmode, otros ssl=true, y algunos esperan un objeto en vez de una cadena. Si usas el nombre equivocado, el driver puede ignorarlo y caer al valor por defecto.
Esto es especialmente común en proyectos generados por IA porque el código mezcla ejemplos de distintos ecosistemas. Puedes ver sslMode en un sitio y sslmode en otro. Uno se respeta, el otro se ignora.
2) Elegir la estricticidad errónea (require vs verify-full)
Dos patrones de fallo frecuentes:
- Pones
sslmode=require, pero tu proveedor espera validación de certificado (verify-caoverify-full). - Pones
sslmode=verify-full, pero el nombre de host o la cadena de certificados no coinciden, así que producción falla mientras local parecía tolerar ajustes más débiles.
3) Falta de certificado CA al usar verify-ca o verify-full
Si verificas certificados, normalmente necesitas un certificado CA (a menudo vía sslrootcert o una opción específica del driver). Sin él, los errores se ven como “self signed certificate”, “unable to get local issuer certificate” o “certificate verify failed”.
Un ejemplo simple de lo que la gente pretende (los nombres varían por driver):
... sslmode=verify-full sslrootcert=/path/to/ca.pem
4) Usar una dirección IP en vez de un hostname
verify-full comprueba que el certificado coincida con el hostname. Si tu URL usa una IP como 10.0.0.12, pero el certificado está emitido para algo como db.myprovider.com, la verificación falla.
5) Variables de entorno que sobreescriben lo que crees haber configurado
Es común cambiar código, redeployar y seguir fallando porque la plataforma inyecta DATABASE_URL (u otra variable) que sobreescribe tus nuevos ajustes. La app sigue usando la URL antigua.
6) Copiar y pegar la URL y romper la contraseña
Las contraseñas con caracteres especiales (@, :, #, %) deben estar codificadas en las URLs. Copiar/pegar desde dashboards, herramientas de chat o archivos .env puede corromperlas y generar errores de autenticación que parecen problemas SSL.
Si quieres comprobaciones rápidas antes de profundizar:
- Confirma que tu driver lee el ajuste SSL que usaste (nombre y mayúsculas).
- Ajusta
sslmodea lo que producción requiere, no a lo que tolera local. - Si verifiques, asegúrate de que el certificado CA esté presente y accesible en tiempo de ejecución.
- Usa un hostname (no una IP) cuando uses
verify-full. - Verifica que ninguna variable de entorno esté sobreescribiendo la cadena de conexión que quieres usar.
Paso a paso: construir la configuración de conexión para producción correctamente
La solución empieza por hacer obvios e intencionales los ajustes finales de conexión.
1) Lista todos los orígenes de configuración
Antes de cambiar nada, lista todas las fuentes que pueden influir en la conexión a la base de datos: variables de entorno en tiempo de ejecución, secretos de la plataforma, archivos de configuración de la app, inyección en tiempo de build y ajustes del ORM.
Luego confirma cuál gana si el mismo ajuste aparece dos veces. Muchos bugs de “modo SSL” son en realidad “editaste el sitio equivocado”.
2) Crea una única fuente de verdad para la cadena de conexión
Elige una representación canónica para producción, normalmente una sola DATABASE_URL. Quita otros controles (como flags SSL separados) o deriva estrictamente esos valores desde la URL.
Una buena URL de producción indica explícitamente la intención SSL:
postgres://USER:PASSWORD@HOST:5432/DBNAME?sslmode=verify-full
Si tu proveedor requiere cifrado pero no verificación estricta de identidad, podrías usar sslmode=require. Si exige verificación completa, usa verify-full y configura certificados y comprobaciones de hostname.
3) Decide el modo SSL según los requisitos del proveedor
No adivines. Elige un modo en función de lo que exige el proveedor y anota por qué (un comentario corto junto a la variable es suficiente). Esto evita deriva futura.
4) Añade el certificado CA y el nombre de servidor esperado cuando haga falta
Para verify-ca y verify-full necesitarás normalmente el certificado CA del proveedor disponible en tiempo de ejecución (como ruta de archivo o pasado directamente, según el driver).
Para verify-full, el nombre del servidor debe coincidir con el certificado. Si te conectas por IP o mediante un alias, puedes tener un desajuste incluso con credenciales correctas.
5) Registra una versión segura y enmascarada de la configuración final
Registra lo que la app usará después de todas las sobreescrituras, pero nunca registres contraseñas, tokens ni el contenido completo de certificados.
DB host=prod-db.example.com port=5432 db=app sslmode=verify-full sslrootcert=set user=app_user password=REDACTED
Esa línea única al arrancar suele ser suficiente para detectar un host equivocado, una ruta CA faltante o un modo SSL inesperado.
Paso a paso: prueba el mismo modo SSL localmente
El objetivo es que tu portátil se comporte como producción. Si producción exige SSL y tu entorno local se conecta silenciosamente sin él, embarcarás un fallo.
1) Igualar las entradas de producción, no solo los valores
Arranca localmente con las mismas entradas que usa producción: la URL completa, el modo SSL y cualquier ruta de certificado. Evita mezclar “defaults locales” con “valores prod” en la misma ejecución.
Un patrón práctico es un archivo local dedicado, como .env.prodlike, y ejecutar la app solo con ese archivo cargado.
# Example (names vary by framework/driver)
DATABASE_URL=postgres://user:[email protected]:5432/appdb?sslmode=verify-full
PGSSLMODE=verify-full
PGSSLROOTCERT=./certs/prod-ca.pem
2) Trae la misma cadena de certificados CA
Exporta o descarga el bundle CA que usa producción y guárdalo localmente (por ejemplo ./certs/prod-ca.pem). Apunta tu driver a ese archivo. Sin él, verify-ca y verify-full fallarán aunque todo lo demás esté correcto.
3) Fuerza el modo SSL exacto y evita “auto fallback”
Algunas bibliotecas prueban múltiples opciones o degradan a no-SSL cuando SSL falla. Eso oculta el problema real. Haz explícito el modo SSL y busca logs que indiquen reintentos con distintos ajustes TLS. Si ves “retrying without TLS/SSL”, considera la prueba fallida.
4) Haz que el hostname coincida con lo que verify-full espera
Si te conectas localmente usando una IP, localhost o un DNS diferente al de producción, verify-full puede fallar incluso con la CA correcta.
Usa el mismo hostname DNS que usa producción en tu cadena de conexión. Si debes mapearlo localmente, actualiza hosts/DNS para mantener el mismo nombre.
5) Comprobación externa a la app
Antes de culpar al código, prueba la conexión con un cliente simple usando los mismos ajustes. Si eso falla, tu app también fallará.
Demuestra la solución: pruebas rápidas antes de redeployar
Después de cambiar ajustes SSL, demuestra que la conexión funciona antes de enviar el despliegue. Aísla el problema del código de la app para no adivinar si el cambio lo solucionó.
Empieza probando conectividad fuera de la app, usando el mismo host, puerto, usuario y nombre de BD. Un CLI o un script pequeño elimina al framework y al ORM de la ecuación. Si la conexión directa falla, estás frente a un problema de SSL, certificados, DNS o red.
Una breve tanda de pruebas:
- Conéctate desde el mismo entorno que producción (misma imagen de contenedor o misma VM) usando un cliente mínimo.
- Imprime los ajustes finales que la app usará en tiempo de ejecución (saneados) y confirma que el
sslmodees el esperado. - Confirma que el runtime puede leer la ruta del archivo CA configurado (el archivo existe y permisos adecuados).
- Compara versiones de driver entre local y producción (los valores por defecto cambian).
- Si usas contenedores, verifica si la imagen incluye bundles de CA del sistema (un problema común con imágenes mínimas).
Después de una conexión exitosa, rompe la configuración a propósito para confirmar qué se valida:
- Cambia el hostname a uno incorrecto y confirma que el error cambia a DNS o conexión.
- Pasa a un modo más estricto (
verify-full) sin la CA correcta y confirma errores de validación de certificado. - Apunta la ruta CA a un archivo inexistente y confirma errores de archivo o permisos.
Si estos cambios no afectan el error, puede que no estés ejecutando el mismo path de código que en producción. Eso suele significar que los ajustes SSL se están ignorando o siendo sobreescritos.
Escenario de ejemplo: una base de datos gestionada exige SSL en producción
Un patrón común: todo funciona en tu portátil, despliegas y la app no puede conectarse. Los logs muestran “SSL handshake failed”, “certificate verify failed” o “server does not support SSL, but SSL was required”.
Lo que suele pasar con un servicio Postgres gestionado: localmente ejecutas Postgres sin SSL, o tu cliente local tolera ajustes débiles. En producción, la base de datos gestionada exige SSL y tu app corre en un contenedor que no tiene los certificados CA adecuados.
La raíz suele ser un desajuste entre tres cosas: el hostname al que te conectas, el modo SSL elegido y si el runtime puede verificar la cadena de certificados.
Por ejemplo, podrías desplegar con:
DATABASE_URL=postgres://app:[email protected]:5432/prod?sslmode=verify-full
Esto puede fallar aunque las credenciales sean correctas. verify-full comprueba que el certificado sea de confianza y que coincida con el hostname. Una IP (o un alias de host) a menudo no coincidirá con el nombre DNS del certificado.
Una solución mínima es conectarse usando el hostname que el certificado espera y asegurarte de que el runtime pueda validarlo:
DATABASE_URL=postgres://app:[email protected]:5432/prod?sslmode=verify-full\u0026sslrootcert=/etc/ssl/certs/ca-certificates.crt
Si no puedes proporcionar una ruta de bundle CA (o tu imagen la carece), un parche temporal es cambiar a sslmode=require para cifrar el tráfico sin verificación estricta. Eso puede desbloquearte, pero es menos seguro que la verificación completa.
Para evitar repetir esto:
- Usa el mismo formato de hostname localmente que usarás en producción (nombre DNS, no una IP).
- Elige el modo SSL intencionalmente y documenta por qué.
- Asegúrate de que la imagen runtime incluya certificados CA y conoce dónde está el bundle.
- Añade una prueba de humo que corra dentro de la misma imagen de contenedor que despliegas.
Trampas comunes en apps generadas por IA (Lovable, Bolt, v0, Cursor, Replit)
Las apps generadas con herramientas como Lovable, Bolt, v0, Cursor y Replit a menudo fallan de una manera específica: la configuración de base de datos parece plausible, pero fue adivinada. Por eso los errores SSL aparecen tras el despliegue.
Un patrón es un campo de cadena de conexión inventado que tu driver no usa. Una app puede poner ssl=true o tls=true y asumir que fuerza SSL, mientras el driver solo respeta sslmode=require (o un objeto ssl estructurado). Localmente tu base de datos acepta TCP plano, así que no lo notas. En producción, un Postgres gestionado exige SSL y la conexión falla.
Otro patrón son overrides ocultos. Estos proyectos suelen establecer configuración de base de datos en varios sitios, y arreglas solo uno de ellos. Localmente gana un .env. En producción, la plataforma usa otro nombre de variable, inyecta su propio valor o toma un default en tiempo de build.
La refactorización más simple que evita repetir outages es aburrida pero efectiva: elige una fuente de verdad (normalmente DATABASE_URL), parseala una vez y pasa los mismos ajustes a todos los lugares que tocan la base de datos (runtime, migraciones, jobs en background).
Checklist rápido y próximos pasos
Cuando un error SSL aparece solo en producción, rara vez es aleatorio. Normalmente es una pequeña discrepancia entre lo que tu app pide y lo que la base de datos espera.
Checklist:
- Confirma que host y puerto coinciden con el endpoint del proveedor (sin host de dev antiguo ni puerto faltante).
- Confirma que el modo SSL deseado está establecido (por ejemplo,
requirevsverify-full) y que tu driver realmente lo lee. - Si verificas certificados, asegúrate de que el certificado CA esté dentro del runtime (VM, contenedor, serverless) y que la ruta sea correcta.
- Comprueba que el hostname en la cadena de conexión coincide con el hostname del certificado (una causa común de fallo con
verify-full). - Asegúrate de tener una fuente de verdad para config, no overrides dispersos por código y dashboards.
Si sigues obteniendo “works on my machine”, compara versiones de driver y stores de confianza. Una imagen de contenedor puede no incluir un bundle CA, o en producción podrías estar usando una biblioteca cliente diferente con defaults distintos.
Un paso liviano siguiente es un preflight en el arranque que falle rápido con un mensaje claro:
Idea de preflight: al iniciar, conecta usando la misma cadena de conexión.
Si falla, loggea: sslmode, host y si se encontró un archivo CA.
Salir para que el deploy falle pronto en vez de agotar tiempo más tarde.
Si heredaste un prototipo generado por IA y la lógica SSL/config está dispersa por la base de código, FixMyMess (fixmymess.ai) se centra en diagnosticar y reparar estas roturas que solo aparecen en producción. Una auditoría rápida puede identificar cadenas de conexión en conflicto, manejo de CA faltante y defaults inseguros para que la app se comporte de forma predecible en producción.
Preguntas Frecuentes
¿Por qué los errores SSL aparecen solo después de desplegar a producción?
Por lo general significa que en producción te conectas a un endpoint de base de datos gestionado que exige SSL y posiblemente validación de certificados, mientras que tu base de datos local permite TCP plano o realiza una degradación silenciosa a no-SSL. El código puede ser idéntico, pero los valores por defecto del entorno y la ruta de red son distintos.
¿Cuál es la diferencia entre sslmode=require y sslmode=verify-full?
require cifra la conexión pero no verifica estrictamente la identidad del servidor. verify-full cifra la conexión y además valida la cadena de certificados y que el hostname con el que te conectas coincida con el certificado, lo que suele fallar si usas una IP, un hostname de proxy o un nombre DNS incorrecto.
¿Por qué falla con “hostname mismatch” cuando uso una dirección IP?
Porque verify-full exige coincidencia exacta del hostname y los certificados casi nunca se emiten para direcciones IP crudas. Usa el nombre DNS del proveedor que aparece en el certificado, no una IP privada o un alias interno, cuando necesites verificación estricta.
¿Qué significa “unable to get local issuer certificate” en producción?
Normalmente significa que el runtime no puede verificar la cadena de certificados. Causas comunes: certificados CA faltantes en el contenedor/VM, una ruta incorrecta en sslrootcert, o una imagen base mínima que no incluye los bundles de CA del sistema.
¿Qué debo registrar para diagnosticar esto sin filtrar secretos?
Registra el host de la base de datos resuelto, puerto, nombre de la BD y el sslmode al arrancar, con las credenciales enmascaradas. También captura el primer error y cualquier línea de “caused by”, porque los reintentos pueden ocultar la falla real.
¿Por qué sigue fallando después de “habilitar SSL” en mi configuración?
A menudo el driver está ignorando tus ajustes SSL por usar el nombre de opción equivocado o por la diferencia en mayúsculas/minúsculas, o una variable de entorno como DATABASE_URL está sobreescribiendo lo que cambiaste en código. Otra causa frecuente es que un proxy o pooler en producción presente un certificado distinto al que esperas.
¿Cómo puedo hacer que mi entorno local se comporte como producción respecto a SSL?
Ejecuta localmente con la cadena de conexión completa en estilo producción, el mismo sslmode y las mismas rutas de certificado. El objetivo es evitar que prefer u otros modos de fallback enmascaren problemas hasta que despliegues.
¿Podría ser causado por mi DATABASE_URL o un error de copiar y pegar?
Primero confirma la DATABASE_URL que la app realmente usa en tiempo de ejecución, ya que las plataformas suelen inyectarla o sobreescribirla. Luego verifica que el driver lea el parámetro que estás estableciendo y que cualquier carácter especial en la contraseña esté codificado en la URL, porque URLs mal formadas pueden parecer errores SSL.
¿Puede PgBouncer o un proxy causar fallos SSL intermitentes?
Sí. Si producción enruta el tráfico a través de PgBouncer, un balanceador o un endpoint privado, el hostname y el certificado presentado pueden diferir de lo que probaste. Esto provoca fallos de handshake intermitentes o errores de verificación si el pooler rota endpoints o usa una cadena de certificados distinta.
¿Cuándo debería pedir a FixMyMess que intervenga?
Si el proyecto fue generado por IA o la configuración está dispersa en muchos sitios, lo más rápido es una auditoría enfocada para hallar la configuración efectiva y corregir los desajustes. FixMyMess puede ejecutar una auditoría de código gratuita y luego reparar la lógica de conexión, el manejo de SSL y los defaults inseguros; la mayoría de arreglos se completan en 48–72 horas y existe la opción de reconstrucción limpia en alrededor de 24 horas cuando la base de código no admite parches.