Estrategia de reintentos para trabajos en segundo plano: backoff, límites y alertas
Estrategia de reintentos para trabajos en segundo plano: añade backoff, límites de intentos, una dead-letter queue y alertas para que las fallas sean visibles y recuperables.
Por qué “no se ejecutó” es una forma arriesgada de encontrar fallos
Los trabajos en segundo plano son las pequeñas tareas que tu app ejecuta detrás de escena para que el producto principal siga rápido. Envían correos, importan CSV, sincronizan datos, procesan pagos y entregan webhooks. Los usuarios rara vez ven el trabajo en sí. Solo notan el resultado.
Por eso la falla más común se parece a esto: funcionó durante las pruebas y luego se detuvo silenciosamente en producción. Nadie ve una página de error. Nada se cae a la vista. Solo te enteras días después cuando un cliente dice: "Nunca recibí el correo" o falta una exportación.
Las fallas silenciosas son peores que las visibles porque dañan la confianza y ocultan la causa. Las fallas visibles obligan a responder. Las silenciosas crean una acumulación de promesas rotas: correos no enviados, datos sin sincronizar, onboarding atascado, reembolsos sin procesar. Para cuando lo notas, estás arreglando el trabajo y limpiando el desastre que dejó.
Un buen plan de reintentos no es "intentar para siempre". Debe hacer cuatro cosas:
- Recuperarse de problemas temporales (timeouts, cortes breves, límites de tasa).
- Backoff bajo presión para no golpear la base de datos o una API externa.
- Parar tras un número razonable de intentos.
- Hacer las fallas obvias para que un humano pueda intervenir.
Si un proveedor de correos devuelve un 503 temporal, reintentar más tarde tiene sentido. Pero si el trabajo falla por una variable de plantilla incorrecta o autenticación rota, reintentar solo quema tiempo y dinero mientras nada se arregla.
Esto aparece mucho en prototipos generados por IA. La app "funciona en su mayoría", luego el trabajo en segundo plano falla silenciosamente porque faltan secretos, el manejo de errores es frágil o la lógica del trabajo está enredada. El primer paso es hacer las fallas ruidosas, acotadas y recuperables.
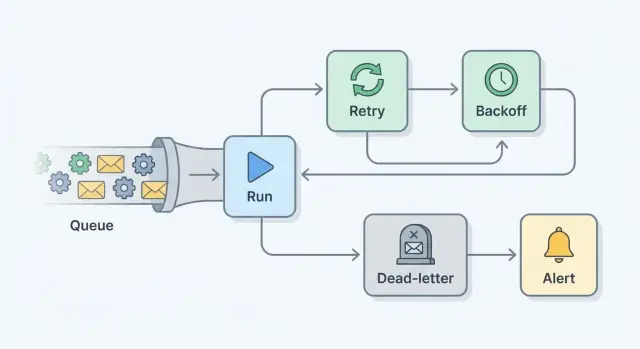
Piezas clave: reintentos, backoff, intentos máximos, dead-letter, alertas
Un plan de reintentos es en realidad un conjunto de pequeñas guías que convierte fallas silenciosas en trabajo visible y recuperable.
Un reintento ejecuta el mismo trabajo otra vez después de fallar. Ayuda cuando la falla es temporal, como una llamada de red inestable.
Backoff es la pausa entre intentos. En lugar de reintentar al instante (y crear una avalancha), esperas más cada vez, a menudo con algo de aleatoriedad.
Intentos máximos es el límite duro. Tras N intentos, paras para que un trabajo malo no entre en un bucle infinito.
Una dead-letter queue (DLQ) (o tabla de trabajos fallidos) es donde van los trabajos después de rendirte. Nada se pierde. Puedes inspeccionar qué pasó, arreglar la causa raíz y reejecutar el trabajo intencionalmente.
Alertas es cómo los humanos se enteran. El objetivo no es notificar por cada reintento. Es notificar cuando algo necesita atención, por ejemplo cuando un trabajo alcanza el máximo de intentos o el volumen de la DLQ empieza a crecer.
Una idea que evita mucho dolor: idempotencia
Un trabajo es idempotente si es seguro ejecutarlo dos veces.
"Establecer el estado de la factura a PAID" es más seguro que "cobrar la tarjeta". Cuando no puedes hacer una acción completamente idempotente, añade un guard: una clave única, una bandera de "ya procesado" o un token de idempotencia del proveedor.
Fallos transitorios vs permanentes
Los fallos transitorios suelen resolverse solos: timeouts, cortes breves, filas bloqueadas. Los fallos permanentes no: registros faltantes, direcciones de correo inválidas, una clave de API incorrecta.
Los reintentos reducen incidentes, pero no eliminan todas las fallas. La idea es contener el radio de daño, sacar a la superficie los problemas reales rápido y darte un lugar seguro (DLQ) para recuperarlos.
Saber qué estás reintentando: errores transitorios vs permanentes
Un plan de reintentos empieza con una decisión: ¿esta falla probablemente desaparecerá por sí sola, o fallará siempre hasta que alguien cambie algo? Si reintentas todo, tendrás colas ruidosas, facturas más altas y retrasos que ocultan el problema real.
Los errores transitorios son temporales. Reintentar (con backoff) suele ayudar porque el entorno cambia: la red se estabiliza, el servicio se recupera, se libera un bloqueo o se restablece la ventana de límite de tasa.
Los errores permanentes no se arreglan solos. Reintentarlos solo consume tiempo mientras los usuarios esperan. Suelen ser problemas de datos, permisos, migraciones faltantes o bugs.
Equivocarse en la clasificación importa. Tratar un error permanente como reintentable puede crear una acumulación que bloquea el trabajo sano. También dificulta detectar incidentes porque el sistema parece "ocupado" en vez de "roto".
Una regla simple: reintenta solo cuando puedas nombrar una condición realista que cambiará sin intervención humana. Si el trabajo probablemente tendría éxito al reintentarlo en 1 a 10 minutos, es reintentable. Si fallaría igual mañana, para, pásalo a DLQ y alerta.
Backoff que se comporta bien bajo presión
Cuando un trabajo falla, lo peor es reintentar al instante en un bucle cerrado. Si la falla viene de una caída parcial, un límite de tasa o una base de datos lenta, los reintentos inmediatos añaden carga justo cuando el sistema ya está intentando recuperarse.
El backoff exponencial es un buen valor por defecto: cada reintento espera más que el anterior. Un patrón simple puede ser 5 s, 15 s, 45 s, 2 min, luego 5 min.
Añade jitter (un poco de aleatoriedad) a cada retraso. Sin él, workers que fallaron juntos reintentará al mismo tiempo, creando picos. Con jitter, una espera planificada de 2 minutos puede ser de 1:30 a 2:30. Esa pequeña variación suaviza los reintentos.
El backoff debe ajustarse al trabajo. Un correo de restablecimiento de contraseña y un informe nocturno no necesitan el mismo ritmo. Como punto de partida, los trabajos orientados al usuario pueden reintentar rápido con un tope corto, mientras que trabajos pesados y APIs estrictas necesitan topes más largos y jitter en cada intento.
Establecer intentos máximos y condiciones claras de parada
Los reintentos ilimitados dan seguridad aparente, pero pueden convertir una falla en un bucle sin fin. El trabajo sigue ejecutándose, acumula tiempo en cola y costes de API, y oculta un bug real porque nada llega a ser una "falla final".
También hay un riesgo práctico: reintentos repetidos pueden causar daño. Puedes enviar el mismo correo muchas veces, crear registros duplicados o cobrar una tarjeta otra vez si el trabajo no es idempotente.
Elige intentos máximos según el impacto. Acciones de alto riesgo como pagos deberían fallar rápido (a menudo 1 a 3 intentos). Notificaciones de usuario más seguras pueden permitir más intentos. Para APIs lentas de terceros, más intentos están bien si el backoff es conservador.
Añade también un límite de tiempo total, no solo un conteo. Por ejemplo: "Reintentar hasta 5 veces, pero detenerse después de 2 horas." Eso evita que un trabajo dure días.
Cuando un trabajo alcanza el máximo de intentos, trátalo como un evento real. Registra lo suficiente para depurar y volver a reproducirlo de forma segura: el último error, el tipo de error, marcas temporales de los intentos y la carga útil (o una versión enmascarada). Captura IDs externas (user_id, order_id) que ayuden a rastrear lo afectado.
Usa una dead-letter queue para que las fallas sean recuperables
Los reintentos son para problemas temporales. Algunos trabajos nunca tendrán éxito sin un cambio. Una DLQ es el lugar seguro para poner esos trabajos después de alcanzar el máximo de intentos, así dejan de consumir recursos y se hacen visibles para un humano.
Piensa en la DLQ como una bandeja de "necesita atención". En lugar de perder trabajo o entrar en un bucle infinito, capturas detalle suficiente para diagnosticar, arreglar y reejecutar intencionalmente.
Qué almacenar en un registro de dead-letter
Una entrada en la DLQ debe responder dos preguntas: ¿qué intentaba hacer el trabajo? y ¿por qué falló?
Mantenlo pequeño pero completo: nombre del trabajo (y versión si la tienes), payload de entrada (o una referencia si es grande), mensaje y tipo de error (más stack trace si está disponible), conteo de intentos con marcas temporales y IDs de correlación (user ID, order ID, request ID) para enlazar con logs.
Ten cuidado con secretos. Si los payloads pueden incluir tokens o contraseñas, enmáscara antes de guardar.
Cómo reencolar de forma segura
Reencolar debe ser deliberado, no un bucle automático. Arregla la causa raíz, luego reintenta desde una pantalla de administración o un script pequeño.
Añade una traza de auditoría mínima: cuando reencolas, reinicia el contador de intentos y registra quién lo reencoló y por qué. Si la falla es una entrada mala que nunca validará, permite marcarla como "no reintentaré" con una nota breve.
La retención importa también. Conserva los elementos de la DLQ el tiempo suficiente para detectar patrones y manejar correcciones lentas, pero no tanto como para que queden datos sensibles demasiado tiempo.
Alertas útiles, no ruidosas
Las alertas deben responder una pregunta rápidamente: "¿Qué se rompió, quién está afectado y qué debo hacer ahora?" Si las fallas permanecen ocultas horas, solo te enterarás por un cliente.
Empieza con disparadores que representen dolor real, no cada intento fallido. Señales útiles incluyen fallos repetidos de un mismo tipo de trabajo, nuevos o crecientes mensajes en la DLQ, tiempo largo en cola (trabajos esperando más de lo prometido al usuario), caídas de throughput y picos de error para un trabajo específico.
Dirige las alertas a quien pueda actuar. En equipos pequeños suele ser el ingeniero on-call o el fundador. Incluye contexto suficiente para que no pasen 20 minutos buscando: nombre del trabajo, entorno, primera hora de fallo, último mensaje de error, cuántos trabajos afectan y si hay entradas en la DLQ.
Para evitar ruido, usa tres controles: umbrales (alertar tras N fallos), agrupación (una alerta por tipo de trabajo por ventana de tiempo) y una ventana de enfriamiento (no volver a alertar durante 15 minutos a menos que empeore).
Si necesitas escalado, mantenlo simple: notifica al on-call primario, luego al backup tras un breve retraso y después un canal más amplio con un resumen de impacto si sigue creciendo.
Haz las fallas visibles con logs y métricas básicas
Un plan de reintentos solo funciona si puedes ver qué está pasando. Si no, terminas con el mismo informe siempre: "el trabajo no se ejecutó." El objetivo es simple: cada intento deja rastro claro y unos pocos números básicos te dicen si va a peor.
Para logs, mantén campos consistentes para que una falla sea fácil de rastrear a través de reintentos. Cada intento debe incluir un job ID (o correlation ID), número de intento, hora de inicio y fin, y resultado. En caso de fallo, registra una clase de error (timeout, auth, validation) más un mensaje corto. También ayuda incluir la cola y el nombre del worker.
Mantén los logs seguros. No registres tokens, contraseñas, claves de API, encabezados completos de requests o datos personales en bruto. Usa IDs internos o valores enmascarados.
Para métricas no necesitas mucho: tasa de éxito por tipo de trabajo, reintentos por trabajo (media y p95), conteo y tasa de la DLQ y tiempo hasta éxito (cuánto tiempo pasan los trabajos reintentando).
Durante un incidente, un pequeño panel debe responder: ¿sube la DLQ? ¿Un tipo de trabajo genera la mayoría de reintentos? ¿Los fallos empezaron en un momento concreto (indicio de un deploy o una caída externa)?
Ejemplo: un trabajo de correo que falla y luego se recupera con seguridad
Un trabajo común es enviar un correo de onboarding tras el registro. Funciona semanas y luego soporte informa: "algunos usuarios no recibieron el correo." Si solo buscas "no se ejecutó", perderás la historia real: se ejecutó, falló y desapareció.
Qué pasa cuando empiezan los fallos
A las 9:02 el trabajo intenta enviar un correo, pero el proveedor hace timeout. Eso es transitorio, así que el worker reintenta con backoff exponencial. Espera 30 s, luego 2 min, luego 10 min. El backoff reduce la presión sobre el proveedor y tu sistema.
En el quinto intento sigue fallando. El trabajo alcanza el máximo de intentos y se detiene. En lugar de perderse, se mueve a la DLQ con detalles útiles: user ID, tipo de correo (onboarding), último error, conteo de intentos y cuándo empezaron los fallos.
Se dispara una alerta una sola vez, no 50 veces: "OnboardingEmailJob: 12 mensajes en DLQ en los últimos 15 minutos. Error principal: timeout." La persona on-call puede ver que es real, que crece y que necesita acción.
Cómo arreglar y reencolar con seguridad
Investigas y encuentras la causa raíz: la clave de API fue rotada, pero el worker sigue usando el secreto antiguo. Esto es común en bases de código tempranas donde los secretos están hardcodeados o se cargan de forma inconsistente.
Tras actualizar el secreto y redeployar, reencolas los mensajes de la DLQ. Antes de cerrar el incidente confirmas que el conteo de la DLQ baja, que nuevos registros reciben correos dentro del tiempo normal, las alertas se despejan y los logs muestran envíos exitosos sin timeouts repetidos.
La falla se vuelve visible, contenida y recuperable, y ningún usuario queda saltado silenciosamente.
Errores comunes que causan incidentes repetidos
Los incidentes repetidos normalmente no son "mala suerte." Provienen de algunos patrones que convierten una pequeña falla en un backlog.
Uno de los mayores es reintentar un trabajo que no es idempotente. Si "ejecutar dos veces" significa "cobrar dos veces" o "enviar dos correos", los reintentos pueden crear un problema para el cliente aun cuando el error original fue menor. Añade una clave de solicitud única, comprueba el estado actual antes de actuar y escribe resultados para que una segunda ejecución sea un no-op.
Otra trampa es capturar cualquier error y reintentar para siempre. Parece seguro, pero oculta bugs reales (datos malos, lógica rota, permisos faltantes) y consume capacidad.
Las fuentes más comunes de dolor repetido son:
- No tener intentos máximos o condición de parada, así los fallos loop hasta que alguien lo nota.
- No tener DLQ (o equivalente), así no puedes revisar y recuperar trabajos fallidos.
- Alertas que no tienen dueño, o alertas tan ruidosas que se silencian.
- Secretos o datos personales en payloads y logs, convirtiendo la depuración en un problema de seguridad.
- Reejecuciones manuales sin saber qué ya tuvo éxito, creando duplicados.
Un ejemplo realista: un trabajo de recibo de pago hace timeout después de que el cobro ya se completó, luego reintenta y envía dos recibos. Semanas después, alguien vuelve a ejecutar un lote "por si acaso" y los clientes reciben spam nuevamente.
Lista rápida antes de lanzar
Antes de activar un nuevo worker o cola en producción, decide cómo es una "falla segura".
- Define qué es reintentable (timeouts, 503s, límites de tasa) vs qué debe fallar rápido (entrada mala, registro faltante, errores de permisos).
- Usa backoff con jitter y un tope sensato para que una caída no cree una gran pila de reintentos.
- Establece intentos máximos y un límite de tiempo (por ejemplo, "detener después de 10 minutos totales"), luego marca como fallido.
- Habilita una DLQ (o tabla de trabajos fallidos) y confirma que puedes reencolar de forma segura sin duplicados.
- Haz las fallas observables: registra job ID, número de intento, nombre de cola, mensaje de error y contexto seguro (IDs internos, no secretos).
Luego prueba todo el ciclo una vez. Elige un trabajo (como enviar un recibo), fuerza una falla transitoria (devuelve un 502 falso una vez) y confirma que reintenta con la demora esperada, tiene éxito en el siguiente intento y produce exactamente un correo.
Siguientes pasos: mejora un trabajo, luego escala el patrón
Elige un trabajo que importe cada día y duela cuando falla. Buenos candidatos son enviar recibos, sincronizar pagos o generar facturas. Si puedes hacer que un trabajo falle de forma segura, recuperarse automáticamente y avisar cuando no puede, habrás creado una plantilla para reutilizar.
Empieza pequeño: clasifica errores y reintenta solo los transitorios. Añade backoff, un límite de intentos y una ruta DLQ para lo que siga fallando. Añade una alerta accionable cuando un trabajo alcance max attempts o vaya a la DLQ. Mantén una línea clara por intento en los logs con job ID, número de intento y el último error.
Si heredaste una base de código generada por IA donde los workers "a veces fallan", evita grandes refactors al principio. Envuelve los trabajos con guardrails (seguimiento de intentos, backoff, condiciones de parada), luego limpia la lógica cuando las fallas sean visibles.
Si no te sientes seguro cambiando el código, FixMyMess (fixmymess.ai) puede ejecutar una auditoría de código gratis para detectar problemas en la lógica de trabajos, reintentos, manejo de secretos y preparación para producción, y luego entregar correcciones verificadas listas para desplegar, a menudo en 48 a 72 horas.
Preguntas Frecuentes
What’s a “silent failure” in a background job?
Las fallas silenciosas ocurren cuando un trabajo se ejecuta en segundo plano, falla y nadie se da cuenta. Los usuarios solo notan el resultado faltante más tarde, por ejemplo: no reciben el recibo o no llega una exportación.
What’s a good default retry plan for most background jobs?
No reintentes para siempre por defecto. Reintenta solo errores que probablemente se solucionen pronto, añade backoff para no sobrecargar sistemas, detén después de un límite fijo y haz visible la falla final para que un humano la arregle.
How do I tell transient errors from permanent errors?
Los errores transitorios se resuelven sin cambios en el código o los datos, como timeouts, breves caídas, límites de tasa o bloqueos temporales. Los errores permanentes suelen ser datos malos, registros faltantes, credenciales inválidas o bugs; reintentar solo retrasa la solución real.
Why use exponential backoff and jitter instead of retrying immediately?
El backoff exponencial espacia más cada reintento y reduce la carga cuando algo ya está fallando. Añade jitter para que muchos workers no reintenten exactamente al mismo tiempo y vuelvan a crear picos.
Why are unlimited retries a bad idea?
Los reintentos ilimitados ocultan bugs reales y pueden aumentar el tiempo en cola, los costes de API y los efectos secundarios duplicados. Un límite de intentos crea un momento claro de “esto necesita atención” y evita que un trabajo roto bloquee el resto.
How many retries should I allow, and how long should I keep retrying?
Empieza por el impacto y el riesgo. Acciones de alto riesgo como pagos deben fallar rápido (a menudo 1–3 intentos). Notificaciones de bajo riesgo pueden intentar más, pero siempre con un límite de tiempo para no reintentar durante días.
What is a dead-letter queue, and why do I need one?
Una dead-letter queue (o tabla de trabajos fallidos) es donde va un trabajo después de alcanzar el máximo de intentos. Evita perder trabajo, captura el contexto para depurar y permite reejecutar intencionalmente tras corregir la causa.
How do I requeue failed jobs safely without causing duplicates?
Recoloca solo después de arreglar la causa del fallo y asegúrate de que el trabajo no genere duplicados si se ejecuta dos veces. Registra quién lo reencoló y por qué, y evita reencolar entradas con datos que nunca validarán.
What does “idempotent job” mean, and when does it matter?
Idempotencia significa que ejecutar el trabajo dos veces no genera un segundo cargo, un segundo correo o registros duplicados. Usa operaciones de “establecer estado” cuando sea posible y, si no, añade una clave única o un token de idempotencia del proveedor.
What should I alert on, and what should I log for background jobs?
Alerta cuando un trabajo se vuelve accionable, por ejemplo: alcanza el máximo de intentos o cae en la DLQ —no en cada reintento. Registra cada intento con un ID de trabajo y tipo de error, y monitoriza métricas simples como crecimiento de la DLQ y tasa de reintentos.