Evita cargas en cascada del lado del cliente para acelerar tu app
Evita cargas en cascada del lado del cliente ejecutando solicitudes en paralelo o agregándolas en el servidor para reducir el tiempo de carga y el time-to-interactive.
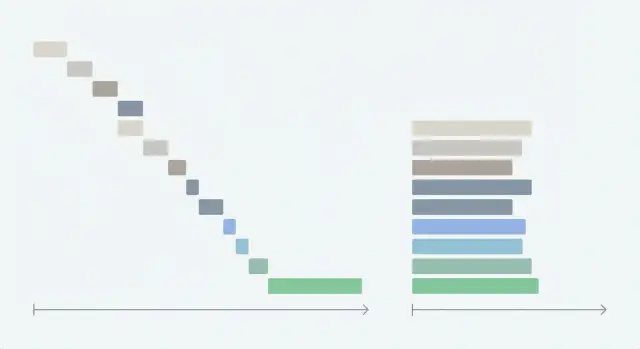
Qué son las cargas en cascada y por qué ralentizan tu app
Un “waterfall” o carga en cascada ocurre cuando tu app hace una solicitud de red, espera a que termine y luego inicia la siguiente. Cada petición añade su propio retraso, así que el tiempo total se vuelve la suma de todas las esperas en lugar de aproximarse a la más larga.
Esto perjudica el tiempo hasta interactivo porque la pantalla a menudo no puede mostrar nada útil hasta que regrese la última petición. Los usuarios lo perciben como una página en blanco, un spinner que se alarga, o una UI que aparece pero queda medio vacía y sigue moviéndose.
Las cascadas suelen aparecer en unos patrones recurrentes:
- Fetches encadenados donde la petición B solo empieza dentro del handler de éxito de la petición A.
- Renderizado ligado a la llegada de datos, de modo que las partes más profundas de la página ni siquiera se montan hasta que regresa la información anterior.
- Componentes anidados que cada uno “hace fetch al montarse”, lo que obliga a que las peticiones de los hijos esperen a las de los padres.
- Código por conveniencia que convierte una pantalla en cinco endpoints, aunque los datos siempre se necesiten juntos.
Esto es especialmente común en prototipos generados por IA. Suelen ir bien en una máquina local rápida, pero se vuelven lentos en producción porque las llamadas secuenciales se acumulan.
La buena noticia es que normalmente puedes prevenir las cargas en cascada del lado del cliente sin reescribirlo todo. Muchas correcciones son directas: ejecutar peticiones independientes en paralelo, empezar la carga antes y quitar trabajo de coordinación del cliente cuando haga demasiado.
Cómo detectar rápidamente una cascada en el cliente
Empieza observando la pantalla como lo haría un usuario. Las cascadas suelen parecer “ocupadas” pero poco responsivas.
Una pista fuerte es la experiencia de carga. Si aparece un spinner, desaparece y luego vuelve a aparecer, probablemente la app está esperando en cadena. Otra señal es la UI que llega por etapas: primero el encabezado, luego la barra lateral, luego la tabla, luego los filtros. Esa sensación escalonada suele significar que los datos van llegando una petición a la vez.
Concéntrate en las pantallas de las que la gente se queja más. Las cascadas adoran los dashboards, las páginas de configuración y cualquier vista con muchas necesidades de datos “pequeñas”.
Qué buscar en el navegador
Abre DevTools y ve a la pestaña Network. Recarga la página y busca:
- Una cadena larga donde cada petición empieza solo después de que la anterior termine
- Huecos de inactividad entre peticiones (nada sucede mientras la UI espera)
- Muchas llamadas similares que varían solo ligeramente
- Peticiones que bloquean el primer contenido significativo
- Un “fan-out” que ocurre tarde (una llamada regresa y luego dispara varias más)
Después de identificar una cadena sospechosa, haz clic en la primera petición y revisa qué la desencadenó (Initiator o stack trace, según el navegador). Si un fetch en un componente desencadena otro en un componente hijo, has encontrado la forma típica de waterfall.
Cruzar con logs del backend
Una cascada también puede aparecer como llamadas repetidas por el mismo dato. Un dashboard podría solicitar el usuario actual en tres componentes diferentes porque cada uno “se asegura” y lo pide de nuevo.
En codebases generados por IA esto es habitual: los componentes copian y pegan lógica de fetch y crean cadenas y duplicados sin querer.
Ejemplo: una pantalla de dashboard que espera cinco endpoints
Un waterfall realista es un dashboard construido desde un prototipo que carga datos paso a paso. Cada petición espera a la anterior, así que la página no se estabiliza.
Imagina que la página hace esto al montarse: fetch del usuario, luego del equipo, luego permisos, luego la lista de widgets y finalmente los datos de cada widget. Si cada llamada tarda 200–400 ms, los usuarios pueden esperar fácilmente 1.5–3 segundos antes de que la pantalla se sienta usable, incluso con buena conexión.
Aquí tienes un conjunto típico de endpoints (los nombres varían, lo importante es el comportamiento):
GET /api/me(datos básicos del perfil como nombre, avatar)GET /api/team(id del equipo, nombre del equipo)GET /api/permissions?teamId=...(roles, feature flags)GET /api/widgets?teamId=...(qué tarjetas mostrar)GET /api/widgets/:id/data(números, gráficos, elementos recientes)
Lo que lo convierte en una cascada no es el número de peticiones: es el orden forzado.
A menudo la página espera a /api/me antes de iniciar /api/team, aunque esas llamadas podrían ejecutarse juntas. Luego espera permisos antes de renderizar las tarjetas, así que los usuarios se quedan mirando una carcasa vacía. Más tarde, las tarjetas aparecen una a una y se reordenan a medida que llegan los datos.
Para prevenir cargas en cascada del lado del cliente, separa lo que realmente depende de algo de lo que solo está codificado así.
Algunas llamadas pueden normalmente ejecutarse en paralelo (como /api/me y /api/team, y a veces /api/widgets). Otras son verdaderamente dependientes (por ejemplo /api/permissions, que necesita un teamId, y las llamadas de datos de widgets que necesitan los IDs de widgets).
La idea principal: normalmente solo necesitas un pequeño conjunto de campos al inicio para renderizar una primera vista estable (encabezado, estructura, placeholders). Todo lo demás puede paralelizarse o agruparse.
Ganancias rápidas antes de un gran refactor
No siempre necesitas reescribir todo para evitar las cascadas. Unos cambios dirigidos pueden recortar segundos del tiempo hasta interactivo y reducir la sensación de “salto”.
Empieza por confirmar qué es lo realmente lento. En el panel Network, ordena por Duration y encuentra el endpoint que domina la línea de tiempo. Es fácil refactorizar tres llamadas “obvias” y perder el verdadero problema, como una comprobación de permisos lenta.
Luego haz que la primera pantalla sea utilizable antes. Si los datos no son necesarios para la primera vista significativa (por ejemplo, “elementos recomendados”, “actividad reciente” o un gráfico pesado), cárgalos después de que el usuario ya pueda interactuar. La gente tolera mucho mejor la carga en segundo plano que una página en blanco.
Un conjunto corto de mejoras rápidas que suele dar resultado:
- Inicia peticiones antes (en la navegación o cambio de ruta), no después de que se monten componentes profundos.
- Evita fetches duplicados solicitando datos compartidos una vez y reusándolos.
- Cachea resultados en memoria por un corto periodo para que una navegación de ida y vuelta no repita las mismas llamadas.
- Prefetchea la pantalla probable siguiente cuando la app esté inactiva, pero solo si es seguro y no es información sensible.
- Mueve llamadas no críticas a “después del paint”, para que la página sea interactiva primero.
Ejemplo: los dashboards a menudo vuelven a pedir "/me" en cada tarjeta porque cada widget pregunta por el usuario por separado. Un arreglo simple es pedir el usuario una vez a nivel de pantalla y pasarlo hacia abajo.
Paso a paso: refactoriza solicitudes secuenciales a llamadas en paralelo
Empieza listando cada petición que una pantalla hace y por qué la necesita. Marca cada una como independiente (puede cargarse ya) o dependiente (necesita un ID o valor de otra respuesta).
Una cadena común es: cargar usuario, luego cargar equipo usando user.teamId, luego cargar proyectos con team.id. Solo las llamadas a team y projects son realmente dependientes. Cualquier otra cosa que no necesite esos IDs no debe estar atascada en la cadena.
1) Mapea qué puede ir junto
Agrupa las solicitudes en dos cubos: “puede pedir ahora” y “debe esperar a X”. Planea dos oleadas:
- Oleada 1: inicia todas las independientes al mismo tiempo.
- Oleada 2: cuando tengas los IDs necesarios, inicia también en paralelo las llamadas dependientes.
2) Reemplaza awaits encadenados por llamadas paralelas
Si ves await tras await para llamadas no relacionadas, ese es tu primer objetivo de refactor.
async function loadScreenData() {
const [me, flags, notifications] = await Promise.all([
api.get("/me"),
api.get("/feature-flags"),
api.get("/notifications"),
]);
const [team, projects] = await Promise.all([
api.get(`/teams/${me.teamId}`),
api.get(`/teams/${me.teamId}/projects`),
]);
return { me, flags, notifications, team, projects };
}
Mantén los grupos paralelos pequeños y con sentido. Si una llamada es opcional (como “consejos” o “noticias”), cárgala después del primer paint.
3) Centraliza la carga de datos por pantalla
En lugar de esparcir fetches entre widgets, crea una función “load screen data” (o un hook a nivel de ruta) que sea la responsable de los datos de la pantalla.
Esto hace que las dependencias sean más fáciles de razonar. También hace que los reintentos y el cache sean más predecibles, y ayuda a evitar “cinco spinners” por todas partes.
Apunta a un estado de carga por pantalla cuando sea posible. Los usuarios suelen preferir “el dashboard se está cargando” antes que cinco spinners separados que terminan en momentos distintos.
Mide antes y después. Controla el tiempo hasta el primer contenido (cuando algo útil aparece) y el tiempo hasta interactivo (cuando los controles responden).
Cuándo agregar en el servidor en vez de en el cliente
La agregación en servidor significa que una petición devuelve todo lo que la pantalla necesita, en lugar de que el navegador haga muchas llamadas pequeñas.
Si quieres prevenir las cascadas del lado del cliente, esto puede ser la solución más limpia porque el cliente deja de coordinar una cadena de solicitudes dependientes.
La agregación ayuda sobre todo cuando:
- La pantalla necesita muchos endpoints pequeños.
- La latencia es notable (usuarios móviles, regiones lejanas).
- Cada endpoint repite el mismo trabajo (chequeos de auth, permisos, consultas a la BDD).
Cinco solicitudes que cada una toma 150–300 ms pueden convertirse rápidamente en más de un segundo antes de que la UI se estabilice.
Un contrato simple lo mantiene predecible. Por ejemplo, un dashboard podría llamar a un endpoint y obtener lo básico en una sola respuesta:
GET /dashboard->{ profile, team, widgets }
Controla el alcance. Evita la agregación cuando crea una carga enorme, incluye datos raramente usados “por si acaso” o mezcla datos con reglas de privacidad distintas. Otra bandera roja es cuando la respuesta se vuelve tan amplia que un pequeño cambio rompe muchas partes no relacionadas de la UI.
Un plan de migración seguro es añadir el endpoint agregado manteniendo los endpoints viejos funcionando. Envía el cambio del cliente detrás de un feature flag, compara resultados y luego mueve el tráfico gradualmente. Cuando la nueva ruta sea estable, retira las llamadas antiguas.
Reduce el tamaño de las cargas y las llamadas redundantes
No mires solo el orden de las peticiones. Mira también cuánto pesa cada respuesta y con qué frecuencia pides el mismo dato. Incluso las peticiones perfectamente paralelas pueden parecer lentas si cada respuesta es pesada o se repite.
Recorta las respuestas de la API a lo que la pantalla realmente usa. Si una tarjeta necesita name, status y updatedAt, no envíes el registro completo con logs, comentarios y descripciones largas.
Agrupa consultas similares cuando puedas. Un patrón común es pedir una lista y luego pedir detalles por cada ítem uno por uno. Ese comportamiento N+1 añade retrasos ocultos y carga extra al servidor. Prefiere un endpoint que acepte IDs y devuelva los ítems correspondientes en una sola respuesta.
Las llamadas redundantes suelen venir de múltiples componentes pidiendo lo mismo independientemente. Un header, una barra lateral y el panel principal podrían cada uno pedir usuario actual, plan y feature flags. Pon datos compartidos detrás de una sola capa de petición (o un store) para que se pidan una vez y se reutilicen.
Comprobaciones prácticas que suelen pagar:
- Añade paginación o límites para que la primera carga sea pequeña.
- Solicita solo los campos necesarios (evita “incluir todo” en expansiones).
- Agrupa llamadas “fetch por ID” en una sola “fetch por IDs”.
- Desduplicar peticiones en vuelo para que dos componentes no lancen la misma llamada.
- Vigila patrones N+1 también en el backend (una llamada API provocando muchas consultas a la BDD).
Ejemplo: si tu dashboard carga 200 proyectos en el primer render pero solo muestra 20, pide 20 y carga más al hacer scroll o búsqueda.
Estados de carga, errores y caching sin introducir bugs nuevos
Tras refactorizar para evitar cascadas del lado del cliente, el siguiente riesgo son bugs de UX: pantallas en blanco, spinners que nunca paran y datos que parpadean o cambian inesperadamente.
Decide qué bloquea realmente la interacción y qué puede llegar después.
Divide los datos en dos grupos:
- Datos bloqueantes: necesarios para renderizar la estructura de la página o permitir la primera acción significativa.
- Datos no bloqueantes: agradables de tener, pero seguros de cargar después de que la página sea usable.
Mostrar UI parcial sin engañar
Los skeletons funcionan mejor cuando coinciden con el layout final. Úsalos para reservar espacio y mostrar estructura, luego rellena con valores reales.
Para widgets pesados (gráficos, editores, mapas), renderiza un placeholder ligero y carga el widget después de que el contenido principal esté listo.
Un patrón simple:
- Renderiza el layout inmediatamente con valores seguros por defecto
- Muestra skeletons solo donde aparecerán datos
- Carga widgets pesados después del contenido primario
- Deshabilita botones solo si realmente necesitan datos faltantes
- Prefiere un texto de “última actualización” sobre un spinner interminable
Errores: falla en pequeño, no a lo grande
Las llamadas en paralelo implican que algunas pueden fallar mientras otras funcionan. Maneja los fallos por sección, no como “toda la página está rota”. Muestra un mensaje pequeño con reintento para esa parte y mantiene lo demás interactivo.
Evita reintentos automáticos en bucles cerrados. Usa backoff y un conteo máximo de reintentos para no crear tormentas de reintentos.
El caching ayuda, pero solo con reglas claras. Decide cuánto tiempo los datos son “frescos” (por ejemplo, 30 segundos para notificaciones, 5 minutos para perfil). Cuando está obsoleto, puedes mostrar datos cacheados instantáneamente y refrescar en segundo plano, pero señala si la precisión importa.
Finalmente, protégete contra condiciones de carrera cuando los usuarios se mueven rápido. Si un usuario navega fuera, cancela las peticiones en vuelo e ignora respuestas tardías. Si no, una respuesta antigua puede sobreescribir estado más reciente.
Errores comunes que vuelven a traer cascadas
Las cascadas a menudo regresan tras un refactor “exitoso” porque la carga de datos queda permitida en demasiados sitios. El objetivo no es solo llamadas paralelas una vez: es mantener la app en forma para que siga paralela con el tiempo.
1) Fetches ocultos dentro de componentes anidados
Una trampa común es mover la pantalla principal a llamadas paralelas, pero dejar componentes hijos que aún hacen fetch al montarse. La página parece bien en local, luego se añade un widget y el cliente empieza a esperar por él silenciosamente.
Una regla simple ayuda: haz fetch a un nivel (ruta o pantalla), y pasa los datos hacia abajo. Si un componente necesita realmente poseer sus datos, haz esa decisión explícita y medible.
2) Peticiones “dependientes” que no lo son realmente
A veces se encadenan llamadas por seguridad, pero la petición B solo necesita una pequeña parte de A (como un ID) que ya tienes o podrías obtener antes.
Una prueba rápida: “Si A falla, ¿B aún puede ejecutarse?” Si la respuesta es sí, no son realmente dependientes.
3) Paralelizar en exceso y sobrecargar el backend
Paralelo está bien hasta que se convierte en un ráfaga. Lanzar 20 peticiones a la vez puede disparar límites de tasa, ralentizar la base de datos o generar reintentos que añaden aún más demora.
Controla la paralelización:
- Limita la concurrencia (por ejemplo, 4–6 a la vez)
- Desduplica llamadas idénticas entre componentes
- Cachea datos estables (como el usuario actual)
- Añade backoff para reintentos
4) El mega-endpoint que devuelve demasiado
La agregación en servidor ayuda, pero un endpoint único que devuelve “todo” tiende a crecer hasta convertirse en el nuevo cuello de botella. El cliente hace una llamada, pero esa llamada es pesada, lenta de computar y difícil de cachear.
5) Rondas extra por comprobaciones de auth
Si la autenticación se comprueba tarde, puedes acabar con: cargar página, recibir 401, refrescar token, reintentar todas las peticiones.
Haz el estado de auth disponible pronto y evita disparar peticiones hasta saber que la sesión es válida.
Lista de comprobación rápida antes de enviar el refactor
Haz una pasada final enfocada en el tiempo para el usuario, no solo en código más limpio. Las cascadas pueden colarse de nuevo por cambios pequeños como una nueva llamada a feature flag o un fetch “por si acaso”.
Recorre la pantalla principal como un usuario por primera vez con caché vacía. Si la página no puede mostrar nada útil hasta que muchas llamadas terminen, probablemente aún tienes una cadena oculta.
Una breve lista pre-lanzamiento:
- Empieza con una o dos peticiones “imprescindibles”, luego carga el resto tras ver el primer contenido.
- Inicia llamadas independientes en el mismo momento (mismo tick), no tras resolverse otra promesa.
- Ten un único responsable claro de la carga de datos de la pantalla (una función u hook).
- Elimina duplicados por diseño (cache cliente compartida, loaders memoizados o una respuesta agregada).
- Vuelve a revisar los tiempos de Network y el time-to-interactive tras el refactor usando el mismo throttling.
Una comprobación rápida: si tu dashboard lanza profile, permissions y workspace en paralelo y muestra header y navegación rápido, debería mantenerse así. Si después se añade una insignia de “estado de facturación” que espera a permisos antes de empezar, has introducido una mini-cascada nueva.
Siguientes pasos: recupera una carga rápida y fiable
Si tu app sigue lenta tras refactorizar, asume que hay más cascadas ocultas. Es común en codebases generados por IA, donde un componente parece limpio pero un hook debajo encadena requests, repite llamadas en cada render o vuelve a pedir el mismo dato por fila.
Elige una pantalla real que importe a los usuarios (a menudo un dashboard o la vista principal) y mide una cosa: cuánto tarda en aparecer la primera pantalla usable. Luego planea el cambio más pequeño que mejore ese número.
Una auditoría focalizada te ayuda a evitar “arreglos de velocidad” que crean bugs nuevos. Busca:
- Fetches encadenados disparados por actualizaciones de estado (fetch A ajusta estado, lo que dispara fetch B)
- Peticiones N+1 (una lista más una petición por ítem)
- Llamadas repetidas por falta de memoización o dependencias inestables
- Endpoints que devuelven demasiado, forzando parsing y render lento
- Atajos riesgosos que aparecen durante refactors (como secretos en el cliente o construcción insegura de queries)
Si heredaste código desordenado generado por IA y quieres una segunda opinión, FixMyMess (fixmymess.ai) hace diagnóstico y reparaciones en codebases rotos creados por IA, incluyendo desenredar cadenas secuenciales de fetch y ajustar llamadas API para que las pantallas carguen de forma predecible en producción.
Preguntas Frecuentes
¿Qué es un fetch en cascada del lado del cliente en términos sencillos?
Un fetch en cascada ocurre cuando tu app inicia la solicitud B solo después de que la A termine, aunque podrían ejecutarse al mismo tiempo. Ese orden forzado hace que el tiempo total se acumule, lo que suele verse como un spinner largo, una estructura vacía o una UI que se va llenando pieza por pieza.
¿Cómo puedo confirmar rápidamente que tengo una cascada en el navegador?
Abre DevTools → Network, recarga la página y busca una cadena donde cada petición empieza solo cuando la anterior termina. También fíjate en huecos de inactividad y en un “fan-out” donde una respuesta desencadena varias solicitudes después; ese patrón de tiempos suele indicar que tu código está coordinando solicitudes demasiado tarde.
¿Cuál es la solución más rápida para llamadas `await` secuenciales?
Si las solicitudes son independientes, reemplaza await secuenciales por Promise.all para que se inicien juntas. Si algunas dependen de IDs, lanza todo lo que puedas en la “ola 1” y, cuando tengas los IDs, lanza las dependientes en la “ola 2”.
¿Cómo evito que varios componentes vuelvan a solicitar los mismos datos?
Haz la petición una sola vez a nivel de pantalla o ruta y pasa el resultado hacia abajo, en vez de dejar que múltiples componentes anidados vuelvan a pedir lo mismo en su mount. Esto reduce llamadas duplicadas y evita cadenas ocultas donde los hijos esperan a que los padres terminen.
¿Qué datos deberían cargarse primero y cuáles en segundo plano?
Carga primero los datos pequeños “bloqueantes” necesarios para que el layout y las interacciones principales aparezcan, y deja datos no bloqueantes (recomendados, actividad reciente, gráficos pesados) para después del primer paint. Así los usuarios pueden empezar a usar la página mientras el resto carga en segundo plano.
¿Cómo hago que la carga se sienta fluida tras paralelizar las solicitudes?
Usa skeletons que coincidan con el diseño final para evitar saltos cuando los datos llegan. Evita apilar spinners; busca un estado de carga claro por pantalla y placeholders más pequeños por sección para que el contenido parcial aparezca sin dar sensación de rotura.
¿Cuál es la forma correcta de manejar errores cuando las solicitudes corren en paralelo?
Maneja fallos por sección y deja el resto de la pantalla usable, ya que las llamadas en paralelo pueden fallar de forma independiente. Ofrece un pequeño botón de reintento para la parte afectada y evita bucles agresivos de reintento que puedan bloquear la UI o sobrecargar el backend.
¿Cuándo debería agregar datos en el servidor en vez de en el cliente?
Cuando la pantalla necesita muchos endpoints pequeños, la latencia es notable, o cada endpoint repite trabajo de auth/permissions, una sola llamada que devuelva lo esencial del screen elimina la coordinación en cliente. Mantén el alcance controlado para no crear una payload enorme o un endpoint frágil “que lo contiene todo”.
¿Cómo evito peticiones N+1 en un dashboard o vista de lista?
Es cuando pides una lista y luego solicitas detalles para cada elemento uno por uno, lo que genera muchas rondas extra. Solución: ofrecer un endpoint por lotes (fetch por IDs) o devolver los campos necesarios en la respuesta inicial para evitar la cascada.
¿Por qué los codebases generados por IA tienen tantas cascadas y qué hago si heredé uno?
Los prototipos generados por IA tienden a esparcir fetches entre muchos componentes, copiar/pegar lógica de solicitudes y, sin querer, encadenar llamadas vía actualizaciones de estado. Si heredaste una app generada por IA (Lovable, Bolt, v0, Cursor, Replit) y va rápido en local pero lenta en producción, FixMyMess (fixmymess.ai) puede auditar y desenredar cadenas de fetch, duplicados y patrones de API riesgosos con una auditoría gratuita y la mayoría de arreglos en 48–72 horas.