Evita la pérdida accidental de datos en actualizaciones con la semántica PATCH
Evita la pérdida accidental de datos en actualizaciones usando la semántica PATCH, listas blancas de campos y defaults claros para que los campos ausentes nunca se borren.
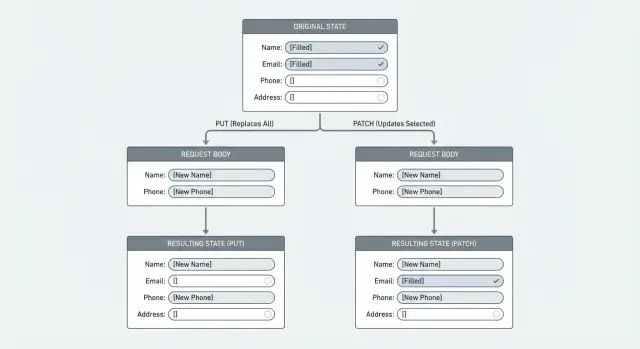
Por qué las actualizaciones estilo reemplazo borran datos por accidente
Una actualización por reemplazo le dice al servidor: “trata este cuerpo de petición como el registro nuevo y completo.” Lo que envíes se convierte en la nueva verdad, y todo lo que no incluyas se considera que ya no está presente. Así es como los campos se borran.
Esto suele pasar cuando un endpoint se comporta como PUT (reemplazo total) aunque todo el mundo lo llame “update”. El cliente envía una carga parcial, el backend la mapea al modelo y luego la guarda. Si falta un campo, algunos caminos de código lo ponen a un valor vacío (""), null o a un default. El resultado parece una eliminación silenciosa.
Ejemplo: un usuario edita su perfil y solo cambia el display name. El formulario envía { "displayName": "Sam" }. Si tu servidor reemplaza todo el perfil, campos como phone, address o marketingOptIn pueden convertirse de repente en null o false, aunque el usuario nunca los tocó.
Esto suele aparecer cuando los clientes no (o no pueden) enviar el registro completo, por ejemplo:
- Formularios web que solo envían inputs visibles
- Apps móviles que mandan “solo campos cambiados” para ahorrar ancho de banda
- Paneles de administración donde algunos campos están ocultos en pestañas o por permisos
Es fácil pasarlo por alto en pruebas. Un test actualiza un campo y verifica que cambió, pero no confirma que todos los demás campos permanezcan iguales. Los usuarios descubren el problema después cuando desaparece una dirección, se restablece una configuración de notificaciones o una integración deja de funcionar.
El primer paso es identificar endpoints donde “update” realmente significa “replace”.
PUT vs PATCH: qué cambia y qué se mantiene
PUT y PATCH responden a preguntas diferentes.
PUT significa: “Aquí está el recurso completo. Reemplaza lo que tienes por esto.” Si el servidor trata PUT como un reemplazo verdadero, cualquier cosa que el cliente no incluya puede ser eliminada o reiniciada.
PATCH significa: “Aquí hay cambios específicos. Aplícalos sobre lo que ya tienes.” Está diseñado para ediciones parciales, donde el cliente envía solo los campos que quiere cambiar.
Esto importa porque muchos clientes se comportan como formularios de edición. Una app móvil podría enviar solo { "displayName": "Mina" }. Si tu endpoint espera un objeto completo (PUT) pero recibe uno parcial, puedes borrar campos como bio, photoUrl o timezone.
Una regla simple que evita la mayoría de las sorpresas es definir qué significa “ausente”:
- Campo ausente: deja el valor almacenado tal cual.
- Presente con valor: actualízalo.
- Presente con
null: bórralo, pero solo si se permite explícitamente.
Si usas PUT, no trates los campos ausentes como “elimínalos.” Trátalos como un error para que los clientes deban enviar una representación completa.
Cuando el reemplazo completo (PUT) sigue siendo útil
El reemplazo completo funciona cuando el cliente realmente posee el documento entero y puede enviar todos los campos de forma fiable cada vez. Por ejemplo, una herramienta interna de administración que edita un pequeño registro de configuración, o un proceso de sincronización que siempre tiene una instantánea completa.
Si no puedes garantizar eso (la mayoría de las APIs públicas no pueden), usa PATCH para ediciones y documenta las reglas para que los clientes no tengan que adivinar.
Elige y documenta tus reglas de actualización
La mayoría de los bugs de campos borrados son un desacuerdo en el equipo: el servidor piensa “reemplazar”, mientras el cliente envía “solo campos cambiados”. Antes de tocar código, decide qué significa cada endpoint.
Para cada endpoint de actualización, define:
- Modo de actualización: replace o patch
- Campos ausentes: ignorados o rechazados
nullexplícito: permitido para borrar o rechazado- Propiedad: qué campos puede editar el cliente vs campos propiedad del servidor
- Validación: qué se comprueba en cada actualización
La distinción “ausente vs null” es donde los equipos se queman. Si el cliente omite phone, normalmente quieres dejarlo sin cambios. Si el cliente envía "phone": null, eso puede significar “bórralo”, pero solo si quieres permitirlo.
La consistencia entre web, móvil y herramientas de admin importa. Diferentes clientes suelen enviar formas de payload distintas, y un cliente con comportamiento de replace puede borrar datos creados por otro.
Un chequeo rápido: elige un campo (como timezone) y describe qué pasa para (1) ausente, (2) null y (3) cadena vacía. Si el equipo no puede responder rápido, las reglas no son lo bastante claras.
Usa listas blancas de campos para controlar lo que se puede actualizar
Una lista blanca de campos significa que el servidor acepta cambios solo para campos específicos y nombrados. Todo lo demás se bloquea o se rechaza.
Esto ayuda de dos maneras:
- Evita escrituras accidentales en campos que la UI nunca pretendió cambiar.
- Impide que los clientes actualicen campos sensibles y propiedad del servidor.
Los campos propiedad del servidor casi nunca deberían ser editables desde un endpoint normal de “update profile/settings”, por ejemplo:
- role o permisos
- flags de estado de cuenta
- totales de facturación
createdAt/updatedAt- flags internos como
isAdminoriskScore
Rechaza campos desconocidos en lugar de almacenarlos silenciosamente. La aceptación silenciosa oculta errores tipográficos, clientes obsoletos y formas de payload inesperadas.
Listas blancas anidadas para objetos complejos
Si aceptas objetos anidados como address o settings, aplica la misma regla dentro de ellos. Lista en blanco la clave de primer nivel y luego lista en blanco las claves anidadas. Eso permite que settings.theme sea editable mientras se bloquea algo inseguro como settings.isAdmin.
Paso a paso: implementar actualizaciones parciales seguras
Una actualización parcial segura es “aplica estos cambios”, no “reemplaza el registro”. El patrón más fiable es: carga lo que existe, aplica solo lo que el cliente envió (y puede cambiar), valida y luego guarda.
Un flujo de implementación práctico
Una secuencia repetible se ve así:
- Obtén el registro actual de la base de datos (y verifica la propiedad por usuario/tenant).
- Construye un objeto
changesdesde el cuerpo de la petición usando una lista blanca. - Valida los cambios (tipos, formatos, límites de longitud, enums).
- Aplica solo los campos que están presentes en la petición. No escribas defaults para campos ausentes.
- Guarda y luego devuelve el registro actualizado para que el cliente pueda resincronizar.
Esto evita el modo de fallo común donde el cliente envía dos campos y el servidor sobrescribe diez campos con valores vacíos.
Registrar sin filtrar datos sensibles
Cuando algo falla, quieres visibilidad sin almacenar valores sensibles. Registra metadatos como:
- id del registro (y id de usuario/tenant)
- qué nombres de campos cambiaron
- fallos de validación
Registra “updated: displayName, avatarUrl”, no el display name real.
Maneja missing, null y defaults sin sorpresas
La mayoría de los bugs de “mis datos se borraron” se reducen a una confusión: el servidor no puede distinguir entre “el usuario no tocó esto” y “el usuario quiere borrar esto.”
Trata el payload como instrucciones:
- Ausente significa “déjalo como está”.
nullsignifica “bórralo”, pero solo para campos donde borrar tenga sentido.
También decide cómo manejar valores vacíos. Una cadena vacía no es lo mismo que ausente, y un arreglo vacío no es lo mismo que null. Si un usuario borra todas las tags, "tags": [] debe poner tags a vacío. Si el cliente envía "tags": null, decide si eso significa “eliminar tags” o “entrada inválida” y cúmplelo.
Evita aplicar defaults de creación durante actualizaciones. Los defaults pertenecen a los flujos de create. En las actualizaciones, los defaults suelen ser destructivos.
Protégete contra actualizaciones perdidas y condiciones de carrera
Incluso con semántica PATCH, dos ediciones pueden sobrescribirse entre sí. El riesgo es el tiempo.
Ejemplo: un usuario abre “Editar perfil” en laptop y móvil. El móvil actualiza displayName y guarda. La laptop, que todavía muestra datos antiguos, actualiza bio después. Sin una comprobación de vigencia, el segundo guardado puede deshacer parte del primero.
Usa control de concurrencia optimista para que el servidor pueda rechazar ediciones obsoletas:
- Campo de versión: guarda un entero como
profileVersion; solo actualiza si coincide. - Comprobación
updatedAt: el cliente envía el timestamp visto por última vez; el servidor actualiza solo si no cambió. - ETag + If-Match: el cliente demuestra que está editando la versión más reciente.
En caso de conflicto, devuelve un error claro (a menudo HTTP 409 o 412) e indica al cliente que recargue.
Errores comunes que borran campos
La mayoría de la pérdida de datos en actualizaciones no es un problema de base de datos. Es un problema de contrato de API: el servidor trata los campos ausentes como “elimínalos.”
Causas comunes:
- Usar semántica PUT con un cliente que solo envía campos cambiados
- Guardar un objeto completo construido desde estado cliente obsoleto
- Actualizar objetos anidados como un todo en vez de hacer patch de hijos (reemplazar
addressborraaddress.line2si el cliente solo envióaddress.city) - Rellenar campos ausentes con defaults durante validación o normalización
Una mentalidad más segura es simple:
- Ausente: déjalo tranquilo
- Null: bórralo (solo cuando esté permitido)
- Desconocido: recházalo
Comprobaciones rápidas antes de publicar
Antes de sacar un endpoint de actualización, haz una pasada centrada en un riesgo: ¿actualizar un campo cambia otros por accidente?
Una lista de verificación corta:
- Confirma que cada ruta de actualización siga las mismas reglas de missing/null.
- Impone listas blancas en el servidor (no solo en la UI).
- Prueba que los campos ausentes no cambien los datos almacenados (actualiza solo
displayName, verifica queemail,phone,addresssigan idénticos). - Prueba que
nullborre solo los campos que explícitamente permites. - Añade una comprobación de concurrencia para que dos ediciones no se sobrescriban.
Un escenario rápido que detecta muchos problemas: toma un registro real de staging con muchos campos configurados, envía una actualización con un solo campo, luego vuelve a obtener y diff. Cualquier cambio inesperado es una señal de alarma.
Ejemplo: una edición de perfil que borra campos no enviados
Un bug común parece inofensivo: un usuario actualiza su foto de perfil, pulsa Guardar y más tarde nota que su número de teléfono desapareció. Nada lo borró intencionadamente. Fue sobrescrito.
Así es como ocurre. La pantalla de perfil solo permite cambiar la foto, así que el cliente envía solo ese campo. El servidor trata la petición como un reemplazo total y escribe un nuevo registro usando solo lo enviado.
Antes: actualización estilo replace (borra campos)
Registro existente en la base de datos:
{
"id": "u_123",
"displayName": "Sam",
"phone": "+1-555-0100",
"photoUrl": "https://cdn.example/old.png"
}
El cliente envía:
{ "photoUrl": "https://cdn.example/new.png" }
El servidor hace (conceptualmente):
profile = request.body
save(profile)
Resultado: phone desaparece porque no se incluyó.
Después: semántica PATCH + lista blanca de campos (mantiene campos)
En lugar de reemplazar todo el registro, trata el payload como cambios y acepta solo los campos que ese endpoint puede editar.
allowed = ["photoUrl"]
changes = pick(request.body, allowed)
profile = loadProfile(userId)
profile = merge(profile, changes)
save(profile)
Ahora solo cambia photoUrl. Todo lo demás permanece igual.
Próximos pasos: audita tus endpoints de actualización y arregla los riesgos
Encuentra cada endpoint que pueda cambiar datos guardados (perfiles, ajustes, facturación, “update status”). Para cada uno, compara lo que existe en almacenamiento, lo que el cliente envía y lo que el servidor escribe. Si el servidor puede escribir más campos de los que contiene la petición, tienes un riesgo.
Una lista de auditoría práctica:
- Busca handlers que sobrescriban registros enteros desde bodies de petición.
- Haz que cada endpoint sea o bien un reemplazo verdadero (y rechace payloads parciales) o bien un patch verdadero (aplica solo campos permitidos y presentes).
- Añade una lista blanca por endpoint y rechaza campos inesperados.
- Estandariza reglas de missing vs null para que los clientes se comporten consistentemente.
- Audita jobs en background y herramientas de admin también, no solo APIs públicas.
Si heredaste una base de código generada por IA, los endpoints de actualización son un punto de fallo común porque los handlers generados suelen por defecto comportarse como “replace”. FixMyMess (fixmymess.ai) se centra en diagnosticar y reparar este tipo de problemas en producción, incluyendo endurecer la semántica de actualizaciones, añadir listas blancas y reforzar la validación para que los datos reales de usuarios no se borren.
Preguntas Frecuentes
¿Debo usar PUT o PATCH para actualizaciones?
Usa PATCH para ediciones parciales de modo que los campos ausentes permanezcan sin cambios. Mantén PUT solo para reemplazos completos cuando el cliente pueda enviar todo el recurso de forma fiable en cada petición.
¿Por qué se borran campos cuando “actualizo” solo un campo?
Porque una actualización estilo reemplazo trata el cuerpo de la petición como el nuevo registro completo. Cualquier campo que no envíes puede ser sobrescrito con null, un valor vacío o un default, lo que parece una eliminación silenciosa.
¿Cuál es la forma más segura de tratar missing vs null?
Elige una regla clara y aplícala en el servidor: missing significa “dejar como está”, mientras que null significa “borrarlo” solo para los campos donde permitir el borrado tiene sentido. Si no puedes soportar borrar de forma segura, rechaza null para ese campo.
¿Pueden los formularios web causar pérdida de datos aunque el usuario no tocara esos campos?
Sí, y es común. Muchos formularios solo envían inputs visibles, así que campos ocultos o en pestañas no se incluirán en la carga. Si el backend reemplaza el registro, esos campos no enviados pueden restablecerse.
¿Cómo evito que los clientes actualicen campos que no deberían tocar?
Usa una lista blanca de campos por endpoint y aplica cambios solo a las claves que estén permitidas y presentes en la petición. Los campos desconocidos deberían rechazarse para que errores tipográficos y clientes desactualizados no cambien datos silenciosamente.
¿Cuál es un patrón seguro del lado servidor para actualizaciones parciales?
Carga el registro existente, construye un objeto changes eligiendo solo las claves permitidas de la petición, valida los cambios, luego mergea y guarda. Evita construir un modelo completo únicamente desde el cuerpo de la petición.
¿Cómo manejo objetos anidados como address sin borrar subcampos?
No trates objetos anidados como reemplazos totales salvo que ese sea el contrato. Haz patch de claves anidadas individualmente (por ejemplo address.city) para que enviar un campo anidado no borre hermanos como address.line2.
¿Por qué son peligrosos los defaults en endpoints de actualización?
Los defaults pertenecen al flujo de creación, no al de actualización. Si aplicas defaults durante actualizaciones, los campos ausentes pueden llenarse “útilmente” con valores por defecto y sobrescribir datos reales almacenados.
¿Cómo evito que dos ediciones se sobrescriban entre sí (condiciones de carrera)?
Usa control de concurrencia optimista para que clientes obsoletos no puedan sobrescribir cambios más recientes. Un número de versión, una comprobación updatedAt o ETag/If-Match permiten al servidor rechazar ediciones desactualizadas con una respuesta de conflicto clara.
¿Cuál es la prueba más rápida para detectar bugs de campos borrados antes de publicar?
Haz la prueba con un registro real que tenga muchos campos fijados, envía una actualización que cambie solo un campo y vuelve a obtener y comparar el registro completo. Si algo más cambió, tu ruta de actualización está haciendo reemplazo o aplicando defaults incorrectamente.