Evitar registros de usuario duplicados con restricciones de unicidad y backfills seguros
Aprende a evitar registros de usuario duplicados con restricciones únicas, normalización de entradas y un plan de backfill seguro que evita downtime y pérdida de datos.
El problema real: por qué siguen ocurriendo usuarios duplicados
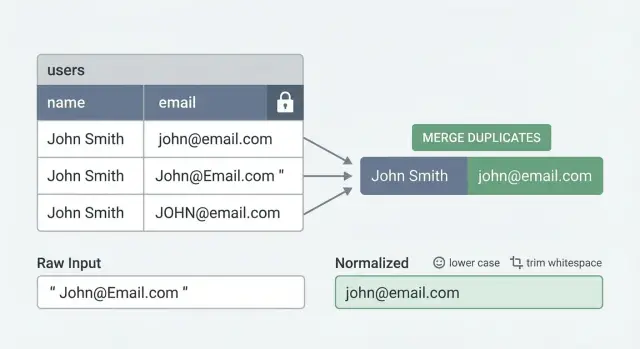
Los usuarios duplicados raramente parecen el mismo email tecleado dos veces. Normalmente aparecen como pequeñas diferencias que los humanos tratan como la misma persona, pero la base de datos ve como valores distintos.
Ejemplos comunes:
- Mismo correo, diferente uso de mayúsculas:
[email protected]vs[email protected] - Espacios ocultos:
[email protected]vs[email protected] - Múltiples métodos de inicio de sesión: una cuenta creada con contraseña, otra después con Google o GitHub usando el mismo email
- Diferentes puntos de creación: un registro de usuario creado durante el checkout y otro durante el onboarding
- Peculiaridades del proveedor:
[email protected]usado una vez,[email protected]usado otra vez (algunas apps quieren que esto sea la misma persona y otras no)
El resultado parece aleatorio para los clientes. Alguien inicia sesión con “el otro” método y cae en “la otra” cuenta. La facturación puede dividirse, así que un usuario pagado parece no tener pago. Los tickets de soporte se convierten en trabajo de detective porque “no veo mis proyectos” en realidad es “tienes dos cuentas y tus datos están en la otra”. La analítica también se ensucia, y la retención y la conversión dejan de ser fiables.
Los equipos suelen intentar evitar duplicados en la UI: desactivar el botón de enviar, mostrar “email ya existe” o añadir una comprobación antes de crear un usuario. Eso ayuda, pero no es suficiente. Tu base de datos puede ser escrita por apps móviles, APIs backend, paneles de administración, importaciones, jobs en background, webhooks y reintentos tras timeouts. Dos requests también pueden competir: ambos comprueban “¿existe este email?” al mismo tiempo, ambos ven “no” y ambos insertan.
La protección a nivel de base de datos es diferente. La base de datos aplica la regla siempre, sin importar de dónde venga la escritura. Defines qué debe ser único (a menudo un email normalizado, o una combinación como provider + provider_user_id) y la base de datos rechaza inserts o updates que crearían un segundo registro con la misma identidad. Esa barrera convierte “intentamos no duplicar usuarios” en “los duplicados ya no pueden ocurrir”.
Formas comunes en que se crean duplicados
Los registros de usuario duplicados aparecen cuando la app asume que la base de datos “lo manejará”. Si la base no hace cumplir la unicidad, los casos límite se convierten en muchas filas para la misma persona, y terminas intentando prevenir duplicados solo con código de aplicación.
Una causa frecuente es una condición de carrera durante el registro. Dos requests pueden llegar a tu servidor casi a la vez (doble clic, conexión inestable, dos pestañas). Si ambos ejecutan “comprobar si el usuario existe” antes de que alguno inserte, los dos deciden que el usuario es nuevo.
Otra fuente común son los múltiples puntos de entrada que crean usuarios: web app, app móvil, panel de admin, importación CSV, flujo de invitaciones, herramienta de soporte. Cada camino desarrolla sus propias reglas con el tiempo. Uno recorta espacios, otro no. Uno comprueba usuarios existentes, otro omite la comprobación “solo para esta función”.
OAuth también puede dividir identidades. Un usuario se registra con email y contraseña y, más tarde, hace clic en “Continuar con Google” usando el mismo email. Si el callback de OAuth crea una nueva fila en lugar de enlazarla al registro existente, ahora tienes dos cuentas que parecen válidas.
Las diferencias en el formato de entrada crean duplicados sigilosos:
- Diferencias de mayúsculas y espacios en email (
[email protected]vs[email protected]) - Diferencias de formato de teléfono (
+1 555 123 4567vs5551234567) - Campos opcionales que llegan más tarde (el usuario empieza con teléfono y añade email después)
- Variaciones internacionales (códigos de país, ceros iniciales)
- Lookalikes Unicode (raro, pero real)
Los reintentos y timeouts también pueden provocarlo. Si un cliente no recibe respuesta (problema de red, timeout de gateway), puede volver a intentar automáticamente. Si tu servidor trata cada reintento como un nuevo registro en lugar de la misma intención, obtendrás duplicados. Esto es especialmente común en prototipos donde la lógica de registro se copia entre rutas sin idempotencia o constraints en la base de datos.
Define qué significa “usuario único” para tu producto
Antes de añadir restricciones, decide qué significa “usuario único” en tu sistema. La mayoría de los duplicados ocurren porque el producto tiene más de una idea de identidad.
Empieza con los identificadores en los que confías: email, número de teléfono e IDs externos de proveedor (sub de Google, id de GitHub, sub de SSO empresarial). Si soportas múltiples métodos de inicio de sesión, decide si todos apuntan a una sola fila de usuario o si cada método puede crear su propia fila que luego se enlaza.
Luego maneja los casos desordenados explícitamente:
- ¿Y si el email está vacío, no verificado o es privado (Apple private relay)?
- ¿Permites usuarios guest que nunca se registran?
- Si el email puede ser
NULL, ¿se permiten variosNULL(a menudo sí) y cómo pasa un guest a cuenta real?
El alcance por tenant o workspace importa igual. ¿La unicidad es global o por tenant? En muchas apps B2B, el mismo email puede existir en distintos workspaces, pero debe ser único dentro de uno. En una app de consumo, normalmente quieres unicidad global.
Un escenario concreto para decidir de antemano: alguien se registra con Google el lunes y luego con email y contraseña el martes usando el mismo email. Si tu definición es “una persona = una fila”, necesitas una regla de fusión y dejarla por escrito.
Una política de fusión simple:
- Elegir un registro “primario” (gana el email verificado; de lo contrario, la sesión más reciente).
- Conservar campos sensibles para seguridad del primario (hash de contraseña, ajustes MFA).
- Fusionar campos de perfil (nombre, avatar) solo si faltan en el primario.
- Reapuntar datos relacionados (órdenes, membresías, claves API) al primario.
- Dejar una nota de auditoría para poder explicar lo ocurrido más tarde.
Escribe estas reglas en lenguaje claro antes de tocar la base de datos. Mantiene alineados a ingeniería, soporte y producto cuando aparezcan casos límite reales.
Normaliza las entradas para que la base de datos pueda aplicar unicidad
Las restricciones únicas solo funcionan si los valores que guardas son consistentes. Si una persona puede registrarse como [email protected], [email protected] y [email protected], la base de datos ve tres cadenas distintas.
Normalizar significa elegir un formato de almacenamiento para una misma identidad y siempre escribir ese formato en la base de datos. Este es el paso silencioso que hace que una restricción única realmente funcione.
Qué normalizar (y con qué precaución)
Para email, empieza simple: recorta espacios y pasa a minúsculas antes de guardar. Decide cómo quieres tratar el plus-addressing ([email protected]). Algunos equipos eliminan la parte +... para reducir duplicados, pero eso es específico del proveedor y no siempre seguro. Un valor por defecto más seguro es lowercase + trim, y solo añadir el manejo de plus-addressing si estás seguro de que encaja con las reglas de tu producto.
Para números de teléfono, almacena un formato consistente, idealmente con el código de país y solo dígitos. Si no, +1 (415) 555-0123 y 4155550123 pueden pasar la comprobación de unicidad.
Para nombres de usuario, adapta la normalización al comportamiento de tu producto. Si tu UI trata Jane y jane como lo mismo, tu backend debe normalizar de la misma manera antes de insertar.
Un patrón práctico es almacenar ambos:
- Entrada cruda (lo que el usuario escribió, útil para mostrar y soporte)
- Valor normalizado (sobre el que aplicas unicidad)
La aplicación backend vence a las pistas en frontend
Normaliza en el backend cada vez que creas o actualizas un usuario. Las comprobaciones en frontend mejoran la UX, pero son fáciles de evitar (clientes antiguos, múltiples apps, llamadas directas a la API).
Un modo de fallo común: un fundador importa usuarios desde CSV mientras se realizan registros. La importación mantiene la mayúscula original, el formulario de registro la pasa a minúsculas, y ahora tienes dos cuentas para el mismo email. La normalización en backend junto a una columna normalizada única evita esa separación.
Elije la restricción única correcta para tu esquema
Una restricción única es una regla que la base de datos aplica: no pueden existir dos filas con el mismo valor “único”. Un índice único es la herramienta que acelera la comprobación. Muchas bases de datos crean un índice único cuando añades una constraint, así que la diferencia práctica es principalmente de intención y herramientas.
Lo difícil es elegir las columnas correctas. “El email debe ser único” suena simple, pero se rompe rápido cuando añades equipos, múltiples proveedores de inicio de sesión, emails opcionales o borrados suaves.
Cuándo usar unicidad compuesta
Si los usuarios pertenecen a un workspace o tenant, a menudo quieres unicidad dentro de ese tenant, no globalmente. Eso se convierte en una regla compuesta, por ejemplo:
tenant_id + normalized_email(mismo email puede existir en diferentes tenants)provider + provider_user_id(la identidad verdadera para logins OAuth)tenant_id + provider + provider_user_id(común cuando la misma identidad del proveedor puede unirse a varios tenants)
La unicidad compuesta también ayuda cuando soportas login con contraseña y OAuth. Puedes aplicar una regla fuerte por cada tipo de identidad sin forzar que un campo (como el email) haga todo el trabajo.
Unicidad parcial y soft deletes
Los datos reales son desordenados. Algunos usuarios no tienen email aún, o permites cuentas solo con teléfono. En ese caso, aplica unicidad solo cuando el valor exista (una regla parcial). Un ejemplo común es “el email debe ser único, pero solo para filas donde email está presente”.
Los soft deletes añaden otra decisión. Si marcas usuarios como eliminados en lugar de borrarlos, elige una regla e inclúyela:
- Único entre usuarios activos solamente (permitir re-registro con el mismo email)
- Único entre todos los usuarios, incluidos los eliminados (evita la reutilización y mantiene el historial simple)
Planea los duplicados actuales antes de aplicar la restricción
Activar la unicidad cuando ya hay duplicados fallará o bloqueará registros en el peor momento. Antes de imponer nada, inventaría los duplicados, decide qué registro “gana” y asegúrate de que las referencias (sesiones, órdenes, membresías) puedan moverse de forma segura.
Paso a paso: desplegar unicidad sin downtime
El objetivo es evitar registros de usuario duplicados sin congelar inscripciones ni bloquear inicios de sesión. El enfoque más seguro es añadir las piezas primero, completarlas gradualmente, arreglar los casos sucios y solo entonces pedir a la base de datos que imponga unicidad.
Secuencia segura de despliegue
Comienza añadiendo una clave normalizada que la base de datos pueda comparar de forma fiable. Para email, eso normalmente significa una versión en minúsculas y sin espacios (más las reglas extra que use tu producto).
Un despliegue práctico:
- Añade una nueva columna para el valor normalizado (por ejemplo:
email_normalized) y actualiza tu app para que cada nuevo registro escriba tantoemailcomoemail_normalized. - Backfillea
email_normalizedpara los usuarios existentes en pequeños lotes (rangos de ID o ventanas de tiempo) para que cada lote termine rápido. - Ejecuta detección de duplicados usando la clave normalizada y agrupa colisiones (por ejemplo, todas las filas donde
email_normalized = "[email protected]"). - Resuelve cada grupo antes de aplicar la unicidad: elige un ganador, fusiona los datos que necesites y marca los otros como fusionados/deshabilitados.
- Añade el índice/constraint único solo después de que los duplicados hayan desaparecido, usando una opción online si tu base de datos lo soporta.
Ejemplo concreto: un prototipo puede almacenar [email protected], [email protected] y [email protected] como tres usuarios distintos. Cuando backfilleas email_normalized = "[email protected]", esos colisionan y se convierten en un solo grupo que puedes fusionar.
Minimizar locks y sorpresas
La mayoría del downtime ocurre cuando un cambio fuerza locks largos en tablas. Mantén cada operación rápida y predecible.
Algunas reglas que ayudan:
- Backfillea con un tamaño de lote estricto y un timeout. Si un lote no termina rápido, hazlo más pequeño.
- Mantén la app escribiendo valores normalizados antes de empezar el backfill. Si no, las nuevas filas seguirán llegando con nulls y nunca alcanzas a ponerte al día.
- Monitorea “nuevos duplicados por hora” durante el despliegue. Si sube, algo sigue escribiendo claves inconsistentes.
- Crea el índice único de forma que no bloquee escrituras (por ejemplo, creación “concurrente/online”, según lo que soporte tu base de datos).
Plan de backfill: encontrar y fusionar duplicados de forma segura
El backfill es menos sobre SQL sofisticado y más sobre tener cuidado con la identidad. El objetivo es simple: elegir un registro para conservar, mover todo a ese registro y dejar un rastro claro.
Empieza listando duplicados usando la misma clave normalizada que planeas imponer después (por ejemplo, email en minúsculas y sin espacios). Hazlo en modo solo lectura primero y luego exporta los grupos para revisión.
-- Example: find duplicate emails by normalized value
SELECT
LOWER(TRIM(email)) AS email_norm,
COUNT(*) AS user_count,
ARRAY_AGG(id ORDER BY created_at) AS user_ids
FROM users
WHERE email IS NOT NULL
GROUP BY LOWER(TRIM(email))
HAVING COUNT(*) > 1
ORDER BY user_count DESC;
Para cada grupo de duplicados, elige un usuario “primario”. Una regla práctica es conservar la cuenta que parezca real y activa. Desempates útiles: email verificado, actividad más reciente y estado de plan pagado.
Luego fusiona en un orden predecible para no perder datos:
- Bloquea el grupo duplicado (o ejecuta la fusión en una transacción) para evitar nuevas escrituras durante la migración.
- Reapunta registros relacionados (órdenes, proyectos, membresías, claves API, tickets) de duplicate_user_id a primary_user_id.
- Resuelve conflictos campo por campo (conservar email verificado, conservar detalles de perfil más recientes, conservar rol de mayor privilegio).
- Escribe una fila de auditoría: duplicate_user_id -> primary_user_id, cuándo ocurrió y quién/qué lo ejecutó.
- Deshabilita el usuario no primario (soft-delete) y solo elimina físicamente más tarde si estás seguro de que nada depende de él.
Las credenciales y los emails necesitan manejo especial. Si el primario conserva el email, elimina o deja el email en null en el registro no primario para que no pueda usarse para iniciar sesión. Para contraseñas, sesiones e identidades OAuth, migra solo si estás seguro de que pertenecen a la misma persona; de lo contrario, revoca sesiones en las cuentas no primarias y exige un nuevo inicio de sesión.
No rompas el inicio de sesión: manejar auth y sesiones durante las fusiones
Una fusión no es solo mover datos de perfil. El inicio de sesión a menudo depende de user IDs que están incrustados en sesiones, refresh tokens, enlaces de restablecimiento y webhooks de terceros. Fusionas dos cuentas y ignoras esas referencias, y la gente se encuentra con bucles de login o errores de “cuenta no encontrada”.
Un patrón seguro es conservar una cuenta primaria y tratar cada duplicado como un alias que apunta a ella. Cuando alguien inicia sesión a través de una cuenta que fue fusionada, la resuelves al primario y continúas sin cambiar lo que el usuario escribió.
Redirige los duplicados al usuario primario
Mantén un lookup pequeño (incluso una tabla) como merged_user_id -> primary_user_id. En cada lectura de auth, comprueba ese mapeo y reescribe el user ID al primario antes de crear una nueva sesión. Eso evita bucles porque el sistema nunca crea sesiones para cuentas que ya “no existen”.
Este enfoque de alias también te da tiempo para migrar llamadores antiguos sin outages.
Tokens, reseteos e integraciones: qué debe actualizarse
Antes de activar la restricción, decide qué vas a invalidar y qué vas a migrar:
- Sesiones y refresh tokens: o bien reapúntalos al user ID primario o los revocas y fuerzas un nuevo login.
- Tokens de “recordarme”: rótalos en el siguiente inicio de sesión para evitar fallos silenciosos.
- Reseteos de contraseña y verificación de email: genera nuevos enlaces ligados a la cuenta primaria; no dejes enlaces antiguos apuntando a un ID fusionado.
- Integraciones externas: si un sistema partner almacena tu viejo user ID, mantén la resolución de alias para que los eventos entrantes se adjunten al usuario primario.
- Logs de auditoría: conserva los user IDs históricos, pero muestra la identidad primaria en tu UI de administración para reducir confusión.
Ejemplo: si Ana creó por accidente dos cuentas con el mismo email (una vía Google y otra con contraseña), la fusión debería mantener su sesión actual funcionando y cualquier futuro restablecimiento de contraseña debe apuntar solo a la cuenta primaria.
Errores comunes que causan outages o pérdida de datos
La mayoría de los outages ocurre cuando la base de datos debe aplicar una regla que tus datos aún no cumplen. Una restricción única no perdona: si existe aunque sea un duplicado, las escrituras empiezan a fallar, las colas se acumulan y las inscripciones pueden dejar de funcionar.
Un ejemplo común: un equipo añade un índice único en users.email un viernes, asumiendo “no tenemos duplicados”. De madrugada, un job de importación antiguo vuelve a ejecutarse e inserta el mismo email con diferente mayúscula. El lunes, los registros lanzan 500s y el soporte se inunda.
Errores que causan problemas:
- Activar una constraint única antes de limpiar duplicados existentes.
- Normalizar en una ruta de código pero no en otras (la web app pasa a minúsculas, el admin/import no).
- Asumir que el email siempre está presente o verificado (existen logins solo por teléfono y sociales; los usuarios cambian de email).
- Fusionar usuarios sin actualizar claves foráneas por todas partes (órdenes, membresías, logs de auditoría, claves API, sesiones, campos
created_by). - Eliminar datos silenciosamente durante las fusiones sin un plan de rollback.
Trata la desduplicación como una migración de datos reversible, no como un script de limpieza. Conserva ambos registros, registra qué cambió y solo borra cuando puedas demostrar que nada depende de la fila antigua.
Un enfoque simple y seguro que funciona bien:
- Registra cada decisión de fusión (id ganador, id perdedor, campos elegidos, timestamp).
- Mueve referencias en lotes y verifica recuentos antes y después.
- Añade un mapeo de usuario canónico para que los ids antiguos sigan resolviéndose durante la transición.
- Prueba todas las rutas de escritura (app, admin, imports, workers) usando la misma función de normalización.
Lista rápida y siguientes pasos
Empieza por la consistencia. Tu base de datos solo puede protegerte si cada ruta de escritura produce la misma “clave única”.
Checklist:
- Confirma que las reglas de normalización se aplican en cada ruta de escritura (registro, invitación, creación en admin, OAuth, importaciones, jobs en background).
- Ejecuta un escaneo de duplicados usando la clave normalizada y revisa los resultados con el equipo.
- Prueba la lógica de fusión en una pequeña muestra real primero y confirma qué pasa con perfiles, membresías, suscripciones y logs de auditoría.
- Limpia duplicados por completo y luego habilita la aplicación de la base de datos (índice/constraint único) solo después de que los datos sean seguros.
- Añade monitorización para nuevos conflictos (violaciones de constraint) para que aprendas de los logs, no de los usuarios.
Elige un responsable y un plazo. “Dedupe” se atasca cuando es vago. Hazlo concreto: define el registro canónico, cómo reapuntas claves foráneas y qué haces cuando dos registros discrepan (nombre, teléfono, info de facturación, último login).
Una prueba en seco ayuda: toma 50 clústeres duplicados de producción, ejecuta la fusión en una copia de staging y verifica que los usuarios aún puedan iniciar sesión, ver el workspace correcto y completar reseteos de contraseña.
Si heredaste una app generada por IA y los duplicados siguen apareciendo porque las constraints y la normalización nunca se aplicaron de extremo a extremo, FixMyMess (fixmymess.ai) puede ayudar diagnosticando cada ruta de creación de usuarios, reparando auth y lógica de fusión, y llevándote a una configuración de unicidad aplicada por base de datos sin romper los inicios de sesión.
Preguntas Frecuentes
¿Por qué siguen apareciendo cuentas de usuario duplicadas aunque verifiquemos en la interfaz?
Porque los duplicados suelen crearse por múltiples puntos de escritura y problemas de sincronización, no simplemente por “la misma dirección de correo escrita dos veces”. Dos peticiones pueden competir, las importaciones pueden omitir comprobaciones, los callbacks de OAuth pueden crear nuevas filas, o un reintento tras un timeout puede ejecutar de nuevo la lógica de registro. Solo una regla en la base de datos bloquea duplicados sin importar de dónde venga la escritura.
¿Cuál es la forma más sencilla de evitar emails duplicados por mayúsculas o espacios?
Normaliza el valor sobre el que aplicas la unicidad. Para email, una buena regla por defecto es trim + lowercase en el backend cada vez que creas o actualizas un usuario, y luego aplicar la unicidad sobre la columna normalizada. Conserva el email original si quieres mostrar exactamente lo que escribió el usuario.
¿Debemos aplicar unicidad por email o por el ID del usuario del proveedor OAuth?
En general sí: para OAuth deberías aplicar unicidad sobre la identidad del proveedor, no solo sobre el email. Guarda y aplica unicidad a algo como provider + provider_user_id para que una identidad de Google no pueda crear varias filas, y luego enlaza esa identidad al registro de usuario existente si el email coincide con tus reglas de fusión.
¿Deberíamos tratar el plus-addressing de Gmail como el mismo usuario?
Por defecto, no elimines la parte + a menos que estés seguro de que se ajusta a las reglas de tu producto. Algunos equipos quieren que [email protected] y [email protected] sean la misma persona, pero ese comportamiento depende del proveedor (y puede sorprender fuera de Gmail). Empieza con lowercase+trim y solo añade reglas específicas por proveedor si es necesario.
¿Cómo manejamos la unicidad en una app multi-tenant?
Si tu producto tiene workspaces/tenants, la unicidad suele estar limitada al tenant. Eso implica aplicar tenant_id + email_normalized para que el mismo email pueda existir en diferentes workspaces, pero nunca dos veces dentro del mismo. Las apps de consumo suelen exigir unicidad global.
¿Qué pasa con los usuarios soft-deleted—puede alguien reutilizar el mismo email más tarde?
Decide la política primero y luego encódala en la restricción. Una opción común es “único entre usuarios activos”, que permite que alguien se vuelva a registrar tras una eliminación, pero requiere una restricción parcial basada en active o deleted_at. Si necesitas un historial estricto y quieres evitar la reutilización, aplica unicidad incluyendo los usuarios eliminados.
¿Cómo se puede desplegar una restricción única sin tiempo de inactividad?
Añade la columna normalizada y empieza a escribirla para todos los nuevos registros primero, luego backfillea los usuarios existentes en lotes pequeños. Después detecta colisiones con la clave normalizada, fusiona o deshabilita duplicados, y solo entonces añade el índice/constraint único usando la opción online/concurrente si tu base de datos la soporta. Esta secuencia evita el apagón de inscripciones cuando activas la restricción.
¿Cómo fusionamos usuarios duplicados sin romper el inicio de sesión o las suscripciones?
Elige un usuario primario, repunta todos los registros relacionados a ese primario y mantén un mapeo explícito merged-to para que los IDs antiguos sigan resolviéndose durante la transición. Las sesiones, refresh tokens, reseteos de contraseña y enlaces de verificación requieren cuidado especial; la opción más segura es redirigirlos o reemitirlos para la cuenta primaria para que los usuarios no queden atrapados en bucles de inicio de sesión.
¿Cómo evitamos duplicados causados por reintentos, timeouts o registros con doble clic?
Crea una key de idempotencia para la intención de registro y trata los reintentos como la misma operación, no como la creación de una cuenta nueva. Incluso con idempotencia, conserva la restricción única en la base de datos, porque las condiciones de carrera y las solicitudes paralelas pueden seguir ocurriendo. La combinación evita tanto repeticiones accidentales como problemas de concurrencia reales.
Heredamos una app generada por IA y hay duplicados por todas partes—¿cuál es la forma más rápida de arreglarlo?
Se puede arreglar rápido si lo tratas como un problema tanto de datos como de autenticación/modelo de datos. FixMyMess (fixmymess.ai) puede auditar todas las rutas de creación de usuarios, implementar la normalización en backend, añadir las restricciones únicas adecuadas y ejecutar un plan seguro de backfill/fusión para que los duplicados dejen de aparecer sin romper los inicios de sesión. Si heredaste código generado por IA que crea usuarios inconsistentes, a menudo es más rápido que nosotros reparemos los flujos end-to-end que parchear ruta por ruta.