IDs de correlación para rastrear clics entre APIs y jobs
Los correlation IDs conectan un clic de usuario con logs de API y jobs en segundo plano para localizar fallos rápido, compartir informes claros y arreglar problemas con menos conjeturas.
Por qué depurar se siente aleatorio sin un ID compartido
Un informe de error suele comenzar simple: “Hice clic en Guardar y falló.” Luego abres los logs y todo se convierte en conjeturas. La consola del navegador tiene un conjunto de mensajes, los logs del API están en otro lugar y los logs de los jobs en segundo plano viven en otro sistema. Incluso si cada sitio registra mucho, nada coincide.
Ahí es cuando la depuración se siente aleatoria. Buscas por rango de tiempo, ID de usuario o texto vago como “pago fallido”, esperando dar con las líneas correctas. Si varios usuarios están activos o hay reintentos, es fácil seguir el hilo equivocado.
También explica por qué aparece tanto el “funcionó en mi máquina”. En tu portátil reintentaste el mismo clic y funcionó. En producción, ese mismo clic puede golpear otro servidor, perder una caché, llamar a un tercero lento o encolar un job que falle después. Sin una forma de conectar esos eventos, la historia se divide en fragmentos.
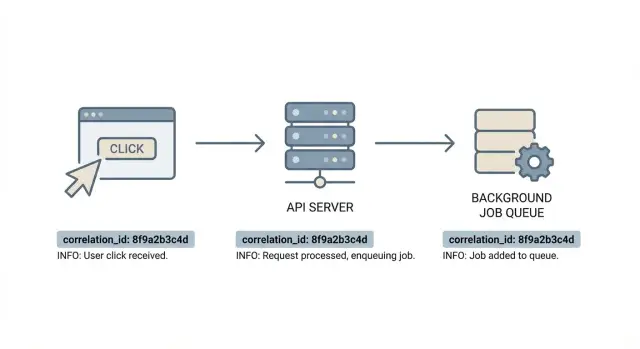
Una acción de usuario puede multiplicarse rápidamente: un clic en el frontend dispara una o varias llamadas API; el API toca la base de datos y quizá otros servicios; puede encolar jobs para email, facturación, procesamiento de imágenes o indexado; y esos jobs pueden ejecutarse después en máquinas distintas, a veces con reintentos. Webhooks y callbacks pueden añadir más pasos.
El objetivo es simple: un rastro que puedas seguir de principio a fin. Con correlation IDs, tomas un ticket de soporte, coges un identificador y extraes el evento del frontend, la petición API exacta y cada línea de log de los jobs que se ejecutaron después. La depuración deja de ser una búsqueda del tesoro y pasa a ser una línea temporal en la que puedas confiar.
Qué es un correlation ID (y qué no es)
Un correlation ID es una etiqueta única que sigue una unidad de trabajo mientras se mueve por tu sistema. Piénsalo como el contexto de “una acción de usuario”: un clic, una petición API, los jobs en segundo plano que provoca y las llamadas downstream.
Cada línea de log que pertenece a esa cadena incluye el mismo ID. Eso te permite buscar una vez y ver toda la historia.
Un correlation ID no es un identificador de usuario. No debe describir quién es el usuario, qué clicó o qué datos estaban implicados. Es una etiqueta opaca que te ayuda a conectar eventos entre sistemas sin adivinar.
A menudo se confunde con otros IDs:
- Session ID agrupa muchas acciones en el tiempo a una misma sesión de navegador. Útil para autenticación y analítica, pero demasiado amplio para rastrear una acción rota concreta.
- ID de registro en la base de datos identifica una fila (por ejemplo, un ID de pedido). Útil para lógica de negocio, pero no conecta automáticamente frontend, API y procesamiento en colas.
- Correlation ID (request ID) une todos los pasos de un flujo, incluso cuando hay múltiples servicios y jobs implicados.
¿Cuándo debes crearlo? Idealmente en el borde: en el navegador cuando empieza la acción (y luego enviarlo como header), o en el primer punto de entrada del API (gateway/load balancer/app server) si no confías en el cliente. Muchos equipos aceptan un ID proporcionado por el cliente, validan el formato y generan uno nuevo si falta o es inválido.
¿Cómo debe ser? Hazlo único, opaco y seguro para registrar. Un UUID o un valor estilo ULID funciona bien. No metas emails, IDs de usuario ni nada sensible.
Dónde debe viajar el ID en una app típica
Un correlation ID solo ayuda si sobrevive todo el recorrido. Piénsalo como una etiqueta que sigue una acción de usuario desde el navegador, pasando por tu API y hasta el trabajo en segundo plano, de modo que cada línea de log pueda vincularse al mismo momento.
En la mayoría de apps eso significa llevar el mismo ID por:
- el evento del frontend (clic o envío de formulario)
- la petición API
- las llamadas downstream (servicios internos y terceros)
- los jobs en segundo plano (publicación y procesamiento por workers)
- los efectos secundarios finales (escrituras, emails, procesamiento de archivos)
Usa los mismos “contenedores” en todas partes. En la web, el carrier más común es un header HTTP (muchos equipos usan un nombre como X-Request-Id o X-Correlation-Id). En el servidor, guárdalo en el contexto por petición para que cada línea de log lo incluya automáticamente. Para jobs, añádelo en los metadatos del job o en el payload para que el worker pueda restaurarlo antes de registrar.
La trazabilidad suele romperse en los límites:
- redirecciones y navegación cross-domain que eliminan headers personalizados
- reintentos y timeouts que crean un nuevo request ID sin copiar el anterior
- publishers de colas que olvidan incluir el ID en el payload del job
- código de worker que registra antes de cargar el ID en el contexto de logs
- trabajos fan-out (un clic produce muchos jobs) sin una relación padre-hijo clara
Una regla simple que evita mucha confusión: el primer backend que recibe la petición es la fuente de verdad. El frontend puede reenviar un ID existente cuando ya lo tiene, pero el backend decide qué se acepta y qué se genera.
Paso a paso: añadir correlation IDs de extremo a extremo
Elige un nombre de header y úsalo en todas partes. La consistencia importa más que la ortografía exacta, porque cada salto (navegador, API, cola, worker) debe reconocer el mismo campo.
Empieza en el frontend. Cuando el usuario hace clic en un botón, reutiliza un ID existente para la acción actual o crea uno nuevo. Manténlo en memoria (o en un objeto de contexto de corta vida) y adjúntalo a cada llamada API que dispare ese clic.
En el API, lee el header en middleware. Si falta, genera uno. Guárdalo en el contexto de la petición para que logs, errores y llamadas downstream lo puedan incluir. También refléjalo en el header de la respuesta, para que el navegador (y soporte) puedan referenciar el ID exacto usado.
Un flujo práctico se ve así:
- El frontend establece
X-Correlation-Iduna vez por acción de usuario y lo reutiliza para las peticiones relacionadas. - El API acepta el header (o crea uno), lo almacena en el contexto de la petición y lo incluye en las respuestas.
- Al encolar, se copia el mismo ID en los metadatos o payload del job.
- El worker restaura el ID en el contexto del worker antes de loggear.
- Los errores incluyen el ID en las respuestas que se muestran a usuarios o soporte.
Los reintentos son donde los equipos suelen perder la pista. Si una petición se reintenta por un timeout, mantén el mismo ID para saber que sigue siendo la misma acción de usuario. Si el usuario vuelve a clicar más tarde, genera un ID nuevo.
Si trabajas en una base de código desordenada, implementa esto en un solo lugar por capa primero: un helper en el frontend, un middleware en el API y un wrapper para jobs. Eso suele ser suficiente para que la depuración deje de sentirse impredecible.
Logging que haga útil al ID
Un correlation ID solo ayuda si aparece en los logs que realmente lees. La forma más sencilla de hacerlo buscable es registrar en un formato consistente y estructurado. Los logs en JSON son fáciles de filtrar por correlation_id y comparar entre frontend, API y jobs en segundo plano.
Como mínimo, cada línea de log relacionada con una petición debería incluir algunos campos confiables:
correlation_idroute(oaction)status(status HTTP o resultado del job)message(breve y legible)duration_ms(cuando aplique)
No registres todo. Una base limpia es una línea al inicio de la petición, otra al final y líneas extra solo para ramas importantes como fallos de validación, reintentos, llamadas externas y excepciones.
Esto es lo que “visible en éxito y fallo” suele parecer:
{"level":"info","message":"request_start","correlation_id":"c-9f3a","route":"POST /checkout","user_id":"u_42"}
{"level":"info","message":"request_end","correlation_id":"c-9f3a","route":"POST /checkout","status":200,"duration_ms":184}
{"level":"error","message":"payment_failed","correlation_id":"c-9f3a","route":"POST /checkout","status":402,"error":"card_declined"}
Ten cuidado con lo que registras. No vuelques cuerpos completos de peticiones, headers de auth, tokens, cookies ni secretos. En lugar de eso, registra resúmenes pequeños como items_count, plan=pro, provider=stripe o email_domain=gmail.com. Esto importa aún más en prototipos construidos rápido, donde a veces los logs imprimen variables de entorno o URLs de bases de datos por accidente.
Jobs en segundo plano: mantener la pista a través de colas
Los logs de peticiones y los logs de jobs responden a preguntas distintas. Los logs de peticiones cubren lo que pasó mientras el usuario esperaba: el clic, la llamada API, la respuesta. Los logs de jobs cubren lo que pasó después: emails enviados, archivos procesados, reintentos y fallos que aparecen minutos más tarde. Sin un identificador compartido, esos dos mundos nunca se encuentran.
Cuando publiques un mensaje en una cola, adjunta el mismo ID que usaste para la petición API. Algunos equipos lo ponen en los metadatos del mensaje (headers/attributes) y también en el payload como fallback. La clave es la consistencia: elige un nombre de campo y úsalo en todas partes para que la búsqueda en logs sea predecible.
Un patrón legible:
- Usa un correlation ID raíz por acción de usuario.
- Cuando el API encola un job, incluye ese ID raíz y, opcionalmente, un ID de job separado.
- Si un clic crea múltiples jobs, mantén el mismo ID raíz para todos ellos.
- Para jobs programados sin clic de usuario, genera un ID raíz en el scheduler.
En el lado del worker, trata el ID como lo primero que lees. Antes de registrar nada, extrae el ID del mensaje, ponlo en el contexto de logs y luego empieza el procesamiento. Si no, ocurre la falla más dolorosa: el job hace trabajo útil, lanza un error y solo entonces registra algo sin el ID.
El fan-out merece una regla extra: conserva el ID raíz compartido, pero añade un identificador hijo por job para que puedas ver qué rama falló.
Hacer el ID visible para soporte y reportes de errores
Si solo los ingenieros pueden ver el ID, no ayudará cuando un cliente reporte “el botón no hizo nada.” Haz que el correlation ID sea fácil de encontrar cuando algo falle, para que soporte pueda pedirlo y ingeniería salte directamente a los logs correctos.
Un enfoque simple es mostrar una etiqueta corta en estados de error, no en todas las pantallas. Ponla donde los usuarios ya miran detalles: un toast de error, el mensaje de un formulario fallido o una página de “Algo salió mal”.
Cómo mostrarlo sin confundir a los usuarios
Usa una línea calmada como: “Referencia: ABCD-1234.” Evita palabras técnicas como “traza” o “distribuido.” Si el ID es largo, muestra una versión abreviada (por ejemplo, los primeros 8–12 caracteres) y deja el valor completo disponible mediante un botón “Copiar”.
Soporte también necesita un guion consistente. Manténlo simple: pide el código “Referencia”, y si no lo ven, pídeles reproducir y hacer una captura del error. Si es posible, recoge la hora aproximada y qué clicaron, luego pega el código en el ticket para que ingeniería pueda buscar de inmediato.
Nota de privacidad
Trata los correlation IDs como etiquetas de diagnóstico, no como datos personales. No codifiques emails, IDs de usuario ni huellas del dispositivo dentro del valor. Manténlo aburrido y aleatorio para que sea seguro compartir en una captura o ticket.
Errores comunes que rompen la trazabilidad
La mayoría de fallos de trazabilidad no son bugs sofisticados. Son pequeñas decisiones que cortan la cadena entre un clic, una petición API y un job en segundo plano.
- Generar un ID nuevo en cada salto. Los IDs nuevos están bien para suboperaciones, pero conserva el original como padre.
- Sobrescribir un ID que viene de upstream. Gateways, CDNs o servicios asociados pueden ya enviar un request ID. Si lo reemplazas, pierdes la capacidad de casar sus logs con los tuyos.
- Eliminar el ID al encolar trabajo. Si el log del API muestra el ID pero el log del job no tiene nada, te quedarás adivinando.
- Registrarlo solo en una capa. IDs solo en frontend no ayudan cuando el servidor falla antes de responder. IDs solo en servidor no ayudan a soporte a conectar con lo que el usuario vio.
- Tratar el ID como seguridad. Un correlation ID no es un token de sesión. No lo uses para auth ni metas secretos en él.
Un ejemplo rápido: un usuario hace clic en “Exportar.” El navegador crea un ID, pero el API genera uno nuevo y solo lo registra. El job de exportación más tarde registra su propio ID aleatorio. Ahora tienes tres IDs no relacionados para un solo clic.
Una regla simple arregla la mayoría: acepta un ID entrante, valida su formato y pásalo sin cambiar. Si necesitas más detalle, añade un segundo campo como parent_id o job_id.
Lista rápida para confirmar que funciona
Sabrás que los correlation IDs hacen su trabajo cuando un solo ID puede responder: “¿qué pasó después de ese clic?”
Prueba una acción (staging está bien): haz clic en “Guardar”, copia el correlation ID desde la UI o el header de respuesta y búscalo en los logs del servidor. Deberías ver un inicio y fin claros de la petición, además de cualquier llamada downstream.
Checklist:
- Un ID encuentra el inicio, pasos clave y el fin de la petición.
- El mismo ID aparece en cada job en segundo plano creado por esa petición (enqueue, inicio del job, fin del job).
- Los errores incluyen el ID y un mensaje claro sobre qué falló (no solo un stack trace).
- Los reintentos mantienen el mismo correlation ID para la misma acción y añaden un número de intento.
- Soporte puede pedir el ID y encontrar la traza completa sin adivinar.
Comprobaciones de la realidad: si buscar por correlation ID devuelve solo una línea, no lo estás adjuntando a todas las líneas de log. Si un clic produce múltiples IDs no relacionados, estás generando IDs nuevos en el API o en el runner del job en lugar de pasar el original.
Ejemplo: rastrear un clic fallido por un API y un job
Un cliente hace clic en “Pagar” en tu página de checkout. El botón gira un segundo y la UI muestra un error genérico: “Algo salió mal.” Sin un ID compartido, adivinas. Con correlation IDs, sigues un hilo desde el navegador al backend y a la cola.
En el navegador, la app crea un ID en cuanto ocurre el clic y lo envía con la llamada API en un header (por ejemplo, X-Correlation-Id). El usuario solo lo ve si decides mostrar un código de referencia en errores.
Qué buscas, en orden:
- Consola del navegador:
pay_click correlationId=7f3a... - Log de acceso del API:
POST /api/pay correlationId=7f3a... status=500 - Log de error del API:
correlationId=7f3a... error="Stripe token missing" userId=... - Registro en la cola:
job=enrich_receipt correlationId=7f3a... queued - Log del worker:
correlationId=7f3a... failed error="DB timeout" retry=1
Ahora la búsqueda es rápida. En lugar de escanear todos los errores de pago de la última hora, filtras logs por correlationId=7f3a... y obtienes una línea temporal cerrada: clic a las 10:14:03, error del API a las 10:14:04, reintento del job a las 10:14:20.
A menudo descubres dos problemas a la vez: el bug de producto (“Stripe token missing”) y la falta de observabilidad que lo hizo parecer aleatorio (el worker no registró el mismo ID, o el mensaje en la cola lo perdió).
Próximos pasos si hoy tu app es difícil de depurar
Si tu app parece imposible de seguir, no intentes arreglar todo a la vez. Implanta esto en un pequeño slice, demuestra que funciona y luego expande.
Empieza con una acción de usuario que falle a menudo (por ejemplo, “Guardar ajustes”) y trázala a través de un endpoint API y un tipo de job. Elige algo que puedas ejecutar repetidamente. Cuando puedas tomar un único ID desde el navegador y encontrar cada línea de log relacionada, habrás creado el patrón que reutilizarás en todas partes.
Escribe una nota corta de convención para evitar deriva:
- qué nombre de header aceptas y reenvías
- qué nombre de campo de log escribes
- dónde se genera el ID y cuándo se reutiliza
- cómo se pasa a los jobs en segundo plano
- dónde soporte puede verlo en la UI
Si heredaste un prototipo generado por IA que falla en producción, suele ayudar empezar con una auditoría enfocada de dónde se pierden los IDs y el contexto de logging entre API, colas y workers. Los equipos usan FixMyMess (fixmymess.ai) para ese tipo de diagnóstico y reparación de bases de código, especialmente cuando necesitan que la app existente sea rápidamente apta para producción.
Una vez que el primer endpoint y job sean trazables, expande por slices. La depuración mejora cada semana, sin esperar a una reescritura grande.
Preguntas Frecuentes
What is a correlation ID in plain English?
Un correlation ID es un valor opaco que etiqueta un flujo de extremo a extremo —por ejemplo, un clic y todo lo que ese clic desencadena. Te permite buscar en los registros una sola vez y ver el evento del frontend, la petición API, las llamadas downstream y los jobs en segundo plano relacionados.
Where should the correlation ID be generated?
Créalo en el borde más temprano y de confianza, normalmente en el primer punto de entrada del backend (gateway o middleware del API). Si el cliente envía uno, acéptalo solo si coincide con el formato esperado; de lo contrario genera uno nuevo y úsalo como fuente de verdad.
Should a correlation ID contain user or business data?
Trátalo como una etiqueta de diagnóstico, no como un identificador de usuario. No debe incluir emails, IDs de usuario, IDs de pedido ni nada sensible, porque terminará en logs, capturas de pantalla y tickets de soporte.
How do I pass the correlation ID from the browser to the API?
Elige un nombre de header y envíalo en cada petición API relacionada con la misma acción de usuario. Además, replícalo en el header de la respuesta para que el navegador y el soporte puedan referenciar el ID exacto que usó el servidor.
Should retries reuse the same correlation ID or generate a new one?
Sí, siempre que los reintentos correspondan a la misma acción de usuario. Mantener el mismo ID deja claro que varios intentos pertenecen a un mismo clic; puedes añadir un contador de intentos en los logs si necesitas más detalle.
How do I keep the correlation ID when work moves to a queue/background job?
Copia el mismo correlation ID en los metadatos del mensaje o en el payload del job al encolar trabajo, y haz que el worker lo cargue en el contexto de logging antes de registrar cualquier cosa. Si el worker registra sin restaurar primero el ID, la traza se rompe justo donde más la necesitas.
What if one click triggers multiple background jobs?
Usa un ID raíz por cada clic y añade un identificador de job distinto por cada rama si necesitas distinguirlas. Así buscas por el ID raíz para ver la historia completa y, si hace falta, identificas exactamente qué job falló.
What should I log alongside the correlation ID to make it actually useful?
Inclúyelo siempre como un campo consistente en cada línea de log relacionada con requests y jobs, idealmente en logs estructurados para facilitar el filtrado. Una línea al inicio, otra al final y líneas extra solo para ramas importantes (llamadas externas, reintentos, excepciones) suelen ser suficientes.
How can I expose the correlation ID to users and support without confusing them?
Muestra el ID solo en estados de error como un código “Referencia” simple para que usuarios no técnicos lo compartan sin confusión. Si el ID completo es largo, enseña una versión corta y ofrece el valor completo con un botón “Copiar” para soporte.
What’s the quickest way to implement this in a messy or AI-generated codebase?
Suele ser más rápido añadir un helper en el frontend, un middleware en el API y un wrapper para jobs que estandarice IDs y logging, y luego expandir por endpoint. Si heredaste una app generada por IA donde IDs, auth o logging están enredados, FixMyMess puede hacer una auditoría de código gratuita y normalmente arreglar problemas críticos en 48–72 horas, incluyendo trazabilidad end-to-end.