Importaciones seguras de CSV grandes en producción sin que la app se caiga
Aprende a importar CSV grandes en producción de forma segura: parseo por streaming, validar por fila, permitir fallos parciales y generar informes claros sin que la app se caiga.
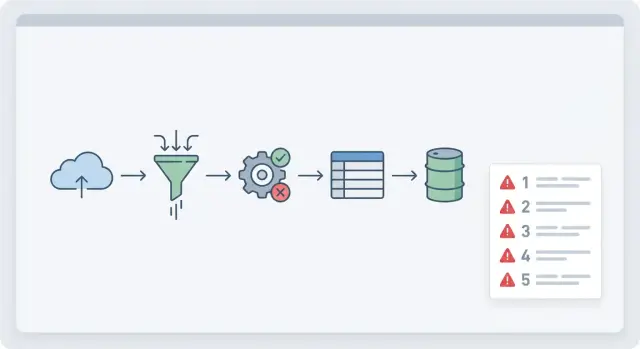
Por qué fallan las importaciones grandes de CSV en producción
Una importación CSV puede funcionar con un archivo de prueba pequeño y luego desmoronarse la primera vez que un cliente sube 300.000 filas. En producción hay redes más lentas, límites de tiempo más estrictos y datos desordenados. Si la importación se construyó como una característica rápida, normalmente asume que todo está limpio y es pequeño.
El fallo más común es la memoria. Muchas importaciones leen el archivo entero en RAM, lo parsean en objetos, lo validan y lo mantienen en arrays hasta el final. Un archivo que parece "no tan grande" puede explotar la memoria al expandirse en estructuras internas. Añade unas cuantas subidas concurrentes y el servidor empieza a intercambiar, trabarse o reiniciarse.
El segundo gran fallo es el tiempo. Las peticiones web y los jobs serverless a menudo tienen límites de ejecución estrictos. Aunque una importación pudiera terminar en 10 minutos, puede ser terminada a los 60 segundos y dejar datos a medio escribir.
Otros puntos comunes de fallo:
- Picos de memoria por cargar el archivo entero o almacenar demasiado en buffer
- Timeouts por validar y escribir en la base de datos dentro de la petición
- Una fila mala que hace caer toda la importación
- Duplicados por reintentos, doble clics o re-subir el mismo archivo
- Escrituras parciales que dejan datos inconsistentes
Lo que ven los usuarios es simple: la página se congela, el spinner no termina o reciben un vago "Import failed" sin pista para corregir. Peor aún, pueden no notar filas faltantes hasta días después.
Lo que tu equipo necesita es lo contrario: resultados previsibles y pruebas. Quieres saber cuántas filas fueron aceptadas, rechazadas y omitidas, además de las razones exactas. Esa claridad convierte una operación aterradora en algo rutinario.
Un ejemplo pequeño: un cliente sube una lista de ventas con la columna de email vacía en la fila 18.237. Si tu importador lanza una excepción y se detiene, pierdes horas y confianza. Si registra el error de la fila y sigue, terminas el trabajo y devuelves un informe accionable.
Qué significa “seguro” para tu importación CSV
Una importación CSV es segura cuando termina sin tirar abajo la app y el resultado es predecible. La mayoría de fallos en producción ocurren porque la importación intenta hacer demasiado de una vez o tiene reglas poco claras.
Empieza por decidir qué significa “éxito” para tus usuarios:
- Todo o nada: si alguna fila está mal, nada se guarda.
- Éxito parcial: las filas buenas se importan y las malas se rechazan con razones claras.
El éxito parcial suele ser más amable con los usuarios, pero exige un diseño cuidadoso para no acabar con datos a medio crear que rompan otras partes de la app.
Pon expectativas claras desde el principio. Una buena función de importación no es ilimitada. Define límites de tamaño de archivo y número de filas, y sé estricto sobre columnas requeridas. Si una columna es obligatoria (como email, SKU o user_id), falla rápido antes de hacer trabajo pesado. Si un campo es opcional, trata valores faltantes como normales y documenta el valor por defecto que aplicas.
Reglas estrictas vs flexibles
Sé estricto con la estructura, flexible con el contenido.
- Estructura: cabeceras requeridas, tipos de datos que necesitas, relaciones de las que depende tu app.
- Contenido: columnas extra que ignoras, campos opcionales, pequeñas diferencias de formato que puedes normalizar (por ejemplo, recortar espacios).
Una manera simple de definir seguridad es responder:
- ¿Qué límites vas a aplicar (filas, tamaño, cabeceras obligatorias)?
- ¿Qué errores detienen toda la importación y cuáles solo rechazan una fila?
- ¿Qué registrarás para soporte y qué mostrarás al usuario?
- ¿Cómo evitarás que el mismo archivo se importe dos veces?
Ese último punto es la idempotencia. Da a cada importación una clave estable (checksum del archivo más usuario y ventana temporal) y haz que envíos repetidos sean seguros.
Parseo en streaming en vez de cargar todo el archivo
Cargar un CSV entero en memoria funciona en demos y luego colapsa en producción. Un solo archivo de cliente puede ser cientos de MB. Si tu app lo lee todo a la vez, hay picos de memoria, timeouts y el servidor puede reiniciarse.
El streaming mantiene la memoria estable. En vez de construir una gran cadena o array, lees un trozo pequeño, parseas unas filas, las procesas y sigues. Bien hecho, el streaming es la base para importaciones fiables porque limita el daño que puede hacer un archivo malo.
Cómo se ve el streaming en la práctica
Un parser en streaming lee bytes de la subida en pequeños fragmentos y emite filas completas tan pronto las compone. Tu código procesa filas una a una o en pequeños lotes, así el progreso continúa aun cuando el archivo sea enorme.
Aquí es donde aparecen las peculiaridades reales del CSV:
- Codificación: exige UTF-8 (o detecta la codificación) y falla rápido si no puede decodificar.
- Delimitadores: soporta comas o punto y coma cuando sea relevante, pero no intentes adivinar eternamente.
- Campos entre comillas: usa un parser CSV real para que comas dentro de comillas no separen columnas.
- Saltos de línea: acepta finales de línea Windows y Unix sin contar mal las filas.
Antes de procesar miles de filas, detecta problemas fatales a nivel de archivo temprano. Si faltan cabeceras o las columnas no coinciden con lo esperado, continuar solo crea ruido.
Una puerta de validación temprana simple verifica:
- El archivo no está vacío y tiene fila de cabecera
- Existen las columnas requeridas
- El delimitador y las reglas de comillas parsean las primeras N líneas correctamente
- El recuento de columnas está dentro de un máximo razonable (protege contra comillas rotas)
Validación por fila que detecta problemas pronto
Trata la validación como un embudo: verifica el archivo una vez y luego valida cada fila mientras entra por streaming.
Comprobaciones a nivel de archivo responden “¿es este el archivo correcto?” antes de tocar la base de datos. Confirma nombres de cabecera, codificación, delimitador y límites aproximados de tamaño. Si la cabecera está mal, detén temprano con un mensaje claro.
Comprobaciones a nivel de fila responden “¿es utilizable esta fila?” y deberían ejecutarse de forma independiente para cada línea. Una fila mala no debería tumbar la importación ni envenenar todo el lote.
Un validador práctico por fila cubre:
- Campos obligatorios (email faltante, SKU vacío)
- Tipos y rangos (cantidades no negativas, precios dentro de límites sensatos)
- Fechas y formatos (fechas inválidas como 2025-02-30)
- Valores permitidos (estado debe ser active, paused o archived)
- Reglas de negocio (claves únicas, relaciones válidas como que customer_id exista)
Normaliza los inputs antes de validar para no rechazar datos que están bien en esencia. Recorta espacios, estandariza mayúsculas donde ayude (por ejemplo, emails) y trata nulls comunes ("N/A", "null", "-") como vacíos. Aplica la misma normalización en todas partes para que duplicados no entren como "ACME" vs "acme ".
Mantén los mensajes de validación cortos y accionables. Un buen patrón es: número de fila, columna, problema y una pista.
Ejemplo: “Fila 128, start_date: fecha inválida. Usa YYYY-MM-DD.”
Idempotencia y protección contra duplicados
Una importación CSV parece simple hasta que alguien hace doble clic en “Importar”, el navegador reintenta o dos personas suben el mismo archivo al mismo tiempo. Sin idempotencia no solo obtienes duplicados, también puedes tener actualizaciones en conflicto y totales rotos.
Decide cómo el sistema reconocerá “esta fila otra vez”. Los números de fila no son estables si los usuarios ordenan o editan el archivo, así que compáralos con campos clave que describan el registro.
Enfoques comunes:
- Claves naturales (email para un usuario, SKU para un producto)
- IDs externas (un ID desde el sistema origen)
- Clave compuesta (organization_id + invoice_number)
- Una clave de importación a nivel de archivo más una huella por fila (hash de campos clave)
Los reintentos deben ser seguros por diseño. Crea un registro de “sesión de importación” cuando comienza la subida, luego registra el resultado de cada fila contra esa sesión. Añade una clave de idempotencia por fila y hazla cumplir con una restricción de unicidad en la base de datos. Si la misma fila llega otra vez, sáltala o trátala como una actualización según tus reglas.
Las condiciones de carrera aparecen cuando dos importaciones tocan los mismos registros a la vez. Usa restricciones de base de datos como último guardián y controla la concurrencia. Por ejemplo, procesa importaciones para el mismo tenant de una en una, o bloquea por una clave natural durante las escrituras.
Fallos parciales sin corromper datos
Los fallos parciales son normales con archivos de clientes. El riesgo no es que unas pocas filas estén mal. El riesgo es acabar con datos a medio escribir que rompen el resto de la app.
Tu objetivo debería ser simple: la importación termina en un estado conocido y válido, o deja la base de datos sin cambios.
Elige una política de fallo clara
Elige una política y muéstrala en la UI:
- Todo o nada: cualquier fila inválida rechaza toda la importación
- Aceptación parcial: las filas válidas se guardan, las filas inválidas se reportan
- Umbral: acepta solo si los fallos están por debajo de un límite (por ejemplo, 2%)
Sea cual sea, añade un paso de staging. Parsea y valida en una tabla de staging (o almacén temporal) primero. Solo escribe los registros finales después de que el lote pase las comprobaciones. Si permites aceptación parcial, igualmente haz staging primero y luego confirma solo las filas buenas en transacciones controladas por lote.
Registra los resultados por fila para poder explicar qué pasó sin adivinar. Un conjunto pequeño de estados funciona bien: success, failed, skipped (duplicado/vacío), updated (coincidió con un registro existente).
Maneja filas dependientes con cuidado
Las dependencias son donde las importaciones parciales se vuelven peligrosas.
Ejemplo: un CSV contiene Clientes y Pedidos. Guardar un Pedido sin su Cliente crea datos rotos.
Elige una regla y aplícala:
- Requerir padres primero (fallar filas hijas si falta el padre)
- Importación en dos pasadas (cargar padres, luego hijos)
- Cuarentena de dependientes (retener filas hijas hasta que el padre exista)
Cuando reportes “éxito parcial”, usa lenguaje claro: cuántas filas se guardaron, cuántas no y si algo fue omitido o actualizado.
Informes de error amigables que la gente pueda arreglar
Una importación CSV puede ser correcta técnicamente y aún así sentirse rota si el informe de errores es confuso. El objetivo es decir a la gente qué pasó, qué corregir y cómo volver a intentarlo sin adivinar.
Empieza con un resumen claro arriba: filas totales, importadas, omitidas, fallidas. Si soportas éxito parcial, indica claramente que algunas filas se guardaron.
Luego muestra detalles por fila que indiquen el problema exacto:
- Número de fila (como el usuario lo ve en el CSV)
- Nombre de columna
- El valor que recibiste
- Lo que esperabas (formato o regla)
- Un mensaje corto que puedan actuar
Haz los mensajes específicos. “Valor inválido” frustra. “La fecha debe ser YYYY-MM-DD, se recibió 3/7/24” es arreglable. Si un campo debe ser uno de unos pocos valores, listalos.
Evita filtrar detalles sensibles. No muestres stack traces, errores SQL, IDs internas ni nada que sugiera la configuración de seguridad. Mapea fallos internos a mensajes seguros como: “No pudimos guardar esta fila. Inténtalo de nuevo o contacta soporte si vuelve a ocurrir.”
Haz que re-subir sea sencillo. Mantén el mismo mapeo de columnas que el usuario eligió la primera vez y ofrece un archivo de errores que puedan editar y volver a subir (a menudo las filas originales más una columna extra de “error”).
Paso a paso: un flujo de importación listo para producción
Un flujo que sobreviva a datos reales parte de la suposición de que algo saldrá mal: una fecha mala, un campo requerido faltante, una clave duplicada o un archivo más grande de lo esperado.
El flujo
-
Crea primero una sesión de importación. Cuando el usuario sube un archivo, crea un registro de sesión con quién lo subió, cuándo, el esquema/versión esperado y un estado (queued/running/complete). Almacena el archivo crudo en almacenamiento duradero y guarda su checksum para poder probar qué se procesó.
-
Parsea por streaming y estate en staging por lotes. Parsea el CSV en streaming y escribe filas en una tabla de staging (o almacén temporal) en pequeños lotes (por ejemplo, 500–2.000 filas). Esto mantiene la memoria estable y te da puntos de control seguros.
-
Valida por fila, registra errores y sigue. Para cada fila, normaliza valores (recortar, parsear fechas, mapear enums) y ejecuta reglas por fila. En vez de lanzar excepciones, escribe un registro de error estructurado ligado a la sesión de importación y al número de fila (campo, mensaje, valor original).
-
Confirma solo las filas válidas con upserts seguros. Mueve las filas válidas de staging a las tablas finales dentro de transacciones controladas. Usa claves únicas y upserts para que los duplicados no creen registros extra.
-
Genera un resumen para el usuario. Almacena totales: filas procesadas, importadas, fallidas y los tipos de error más frecuentes. Produce un informe de errores que la gente pueda filtrar y corregir.
Ejemplo: si un usuario importa 50.000 clientes y 312 filas tienen emails inválidos, igual importas las otras 49.688 y devuelves un informe con los números de fila exactos y las correcciones.
Reintentar sin re-subir
Soporta reintentos usando la misma sesión de importación: conserva el archivo original, las mismas reglas de validación y vuelve a ejecutar tras las correcciones. Si quieres que esto sea confiable, la ruta de reintento necesita las mismas reglas de idempotencia que la primera ejecución.
Barreras de rendimiento y fiabilidad
Una importación CSV es una tarea de larga ejecución. Trátala como tal. Si corre dentro de una petición web normal, te arriesgas a timeouts, pantallas congeladas y escrituras a medio hacer. Pon las importaciones en un job en background y deja que la UI haga polling para que la app siga respondiendo.
Las actualizaciones de progreso deben ser reales, no “todavía trabajando”. Monitoriza etapas (upload, parse, validate, write, finalize) e incluye contadores como filas leídas, filas aceptadas, filas rechazadas y tiempo empleado.
Pon límites para que un archivo malo no monopolice el sistema:
- Tiempo máximo de ejecución por importación (falla con mensaje claro y mantiene el trabajo parcial aislado)
- Límites de tamaño de lote (lotes más pequeños reducen tiempo de bloqueo y picos de memoria)
- Conteo máximo de errores antes de parar (por ejemplo, detener tras 200 filas malas)
- Tamaño máximo de archivo y columnas máximas (rechaza temprano)
- Máximo de importaciones concurrentes por workspace/cuenta
El backpressure importa cuando la base de datos es más lenta que la lectura de archivo. Si las escrituras se quedan atrasadas, ralentiza el lector o pausa el parsing. De lo contrario la memoria sube hasta que el worker falla y pierdes estado.
Hazlo observable. Registra un ID de importación, quién la inició, metadatos del archivo y tiempos por etapa. Añade métricas básicas como filas por segundo y tiempo de escritura en BD. Cuando alguien diga “las importaciones están rotas”, quieres respuestas rápidas.
Planifica la cancelación. Si alguien sube el archivo equivocado, debe poder detenerlo de forma segura. Mantén escrituras en transacciones pequeñas y pon en staging las filas entrantes. Al cancelar o fallar, borra datos de staging y marca la importación como cancelada para que un reintento empiece limpio.
Errores comunes que causan crashes o importaciones malas
La mayoría de fallos en producción no son problemas de “big data”. Son suposiciones pequeñas que solo se rompen cuando clientes reales suben archivos reales.
Un error común es confiar en la fila de cabecera. La gente renombra columnas, añade espacios o exporta desde un sistema distinto. Si no verificas las columnas necesarias y las mapeas explícitamente, los valores pueden desplazarse a campos equivocados y no notarlo hasta después.
Las exportaciones de Excel tienen sus trampas: ceros a la izquierda en IDs se pierden, números largos pasan a notación científica y las fechas pueden llegar como texto, números seriales o formatos mezclados en la misma columna. Si tu importador adivina tipos, obtienes corrupción silenciosa en vez de un claro “Fila 42: fecha inválida”.
La variación del formato de archivo es otra fuente frecuente de fallos: archivos UTF-16, byte order marks, punto y coma en vez de comas o campos entre comillas con saltos de línea. Si tu parser espera un formato perfecto, un archivo raro puede colgar el proceso o desordenar filas.
Algunos patrones que consistentemente causan crashes o importaciones malas:
- Una transacción gigante para cientos de miles de filas (bloqueos largos, timeouts, picos de recursos)
- Tratar todo vacío como inválido aun cuando hay campos opcionales
- Escribir filas directamente sin checks de idempotencia (los reintentos crean duplicados)
- Devolver un error genérico como “Import failed” sin números de fila ni nombres de campo
- Mezclar validación y escrituras de forma que los fallos parciales sean difíciles de recuperar
Ejemplo: un usuario sube 200k contactos y 50 filas tienen fechas malas. Si tu código hace rollback de todo y muestra un error vago, intentarán de nuevo, crearán duplicados o abandonarán.
Lista rápida y siguientes pasos
Si quieres importaciones que no tumben la app, apunta a algo predecible que nunca deje la BD a medio romper.
Lista de verificación simple para producción:
- Define límites claros (max filas, max tamaño de archivo, cabeceras requeridas)
- Parsea como streaming, no cargues todo el archivo en memoria
- Valida cada fila temprano (tipos, campos obligatorios, rangos, verificaciones de relaciones)
- Hazlo idempotente (detección de duplicados y reintentos seguros)
- Stagea y confirma en pequeños lotes para controlar lo que se escribe
Decide tu política de fallos parciales desde el principio y mantenla consistente. Muchos equipos eligen “aceptar filas válidas, rechazar filas inválidas”, pero solo si el resumen es claro y las escrituras son seguras.
Un plan de pruebas corto antes de desplegar cambios:
- Un archivo pequeño y limpio
- Un archivo con filas malintencionadas (valores faltantes, fechas erróneas)
- Un archivo grande cerca de tus límites máximos
- Una subida duplicada (mismo archivo dos veces)
- Un reintento tras interrupción (parar a mitad y reanudar)
Si heredaste un importador generado por IA que se bloquea bajo carga o produce duplicados, normalmente se puede reparar sin reescribir toda la app. FixMyMess (fixmymess.ai) se centra en diagnosticar y arreglar bases de código generadas por IA, incluyendo flujos de importación que necesitan staging, idempotencia y validación más segura para funcionar en producción.
Preguntas Frecuentes
¿Por qué mi importación CSV funciona con 1.000 filas pero falla con 300.000?
Las importaciones grandes suelen fallar porque el código lee todo el archivo en memoria, hace toda la validación de golpe o intenta escribirlo todo dentro de una única petición web. Eso provoca picos de memoria, timeouts y datos parcialmente escritos cuando el proceso es terminado.
¿Qué es el parsing por streaming y por qué es más seguro que cargar todo el archivo?
El parsing por streaming lee el archivo poco a poco y procesa las filas a medida que llegan, manteniendo la memoria estable. También te permite informar progreso, manejar filas malas sin bloquear todo y mantener la app responsiva durante importaciones largas.
¿Qué debo validar antes de procesar cualquier fila?
Haz comprobaciones a nivel de archivo primero: confirma que el archivo no está vacío, que existe la fila de cabecera, que las columnas requeridas están presentes y que la codificación y el delimitador pueden ser parseados. Si la estructura es incorrecta, detén el proceso con un mensaje claro para no perder tiempo procesando basura.
¿Cómo impido que una fila mala bloquee toda la importación?
Valida cada fila de forma independiente y registra los errores en lugar de lanzar excepciones que detengan toda la importación. Mantén los mensajes accionables incluyendo número de fila, columna, qué está mal y el formato esperado.
¿Mi importación debe ser todo o nada o permitir éxito parcial?
Elige una política clara y hazla explícita: todo o nada, éxito parcial, o un umbral (por ejemplo, fallar si más del 2% son inválidas). El éxito parcial suele ser más amable con los usuarios, pero requiere staging y escrituras cuidadosas para no crear relaciones rotas o estados inconsistentes.
¿Cómo prevengo duplicados cuando los usuarios re-suben o reintentan una importación?
Trata los reintentos como algo normal: los usuarios hacen doble clic, los navegadores reintentan y colegas suben el mismo archivo. Añade una sesión de importación y una clave de idempotencia (basada en una clave estable del registro y/o una huella por fila) y aplica unicidad en la base de datos para que el re-procesado no genere duplicados.
¿Cómo evito escrituras parciales que dejen la base de datos inconsistente?
Primero guarda en staging, luego confirma las filas válidas en transacciones pequeñas y controladas. Evita una única transacción gigante para todo el archivo y evita escribir directamente en tablas finales mientras sigues detectando errores; así reduces la probabilidad de terminar con importaciones a medio hacer que no puedes explicar o revertir con seguridad.
¿Por qué las importaciones CSV deberían ejecutarse como jobs en background en vez de dentro de la petición web?
No ejecutes importaciones grandes dentro del ciclo normal de una petición web. Pon la importación en un job en background, guarda el progreso en la sesión de importación y deja que la UI haga polling para el estado, así la página no se congela y el trabajo no es matado por límites de tiempo.
¿Qué debe incluir un informe de errores útil para el usuario?
Da primero un resumen (total, importadas, fallidas, omitidas/actualizadas), y luego muestra detalles por fila que coincidan con lo que el usuario ve en su CSV. Incluye el valor recibido y la regla esperada, pero evita stack traces, errores SQL o IDs internos para no filtrar detalles sensibles de implementación.
¿Puede FixMyMess ayudar si mi importador generado por IA sigue fallando en producción?
FixMyMess se especializa en arreglar apps generadas por IA que fallan en producción, incluyendo flujos de importación CSV que se bloquean, agotan tiempo o crean duplicados. Si tu importador actual es poco fiable, podemos auditar el código, añadir streaming, staging, idempotencia e informes claros, y dejarlo funcionando sin adivinar.