Interruptores de circuito para proveedores inestables para prevenir fallas en cascada
Aprende cómo los circuit breakers para proveedores inestables evitan fallas en cascada usando timeouts, reintentos, fallbacks y recuperación segura cuando las dependencias se estabilizan.
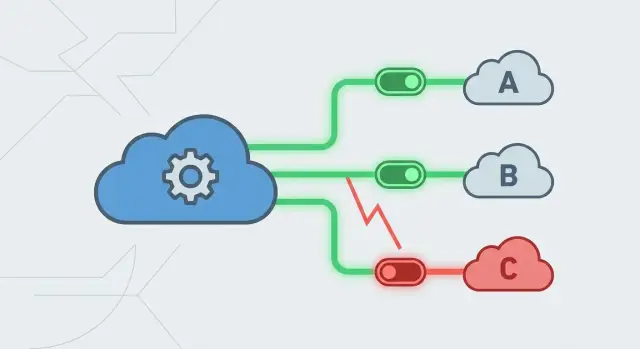
Por qué los proveedores inestables pueden tumbar una app que por lo demás está bien
Una app puede ser sólida y aun así caerse porque algo de lo que depende empieza a fallar. Un gateway de pagos se ralentiza, un servicio de correo devuelve errores o un proxy de base de datos tiene problemas. Si tu app sigue llamando a esa dependencia como si no pasara nada, un problema pequeño se propaga rápido.
Esa reacción en cadena es una falla en cascada: una dependencia lenta o con errores hace que las solicitudes esperen, las solicitudes en espera se acumulan y pronto las partes sanas de la app no pueden respirar. Los hilos se quedan bloqueados, los pools de conexión se llenan, las colas se atascan y todo parece “caído” aunque la mayor parte de tu código esté bien.
Esto suele comenzar con desencadenantes ordinarios:
- Timeouts demasiado largos, de modo que cada solicitud espera mucho más tiempo del que el usuario tolerará.
- Límites de tasa, seguidos de reintentos que empujan aún más tráfico hacia el throttle.
- Cortes parciales donde algunas llamadas funcionan y otras quedan colgadas, que es más difícil de detectar.
- “Éxitos lentos” donde las respuestas finalmente funcionan pero tardan 10x más y atascan recursos.
Los reintentos sin límites empeoran la situación. Si cada acción de usuario dispara tres reintentos y tienes cientos de usuarios golpeando el mismo proveedor, puedes crear tu propio pico de tráfico. Por eso importan los circuit breakers: evitan que tu app toque la estufa caliente una y otra vez.
Desde el punto de vista del usuario, es simple y doloroso. Los botones giran para siempre, las páginas se refrescan en errores y la gente hace clic otra vez porque no pasa nada. Eso conduce a acciones duplicadas (pedidos dobles, cargos dobles, múltiples tickets). Peor aún, los usuarios no saben si sus datos se guardaron o si un pago se procesó.
Este modo de falla aparece mucho en apps heredadas generadas por IA: faltan timeouts, reintentos agresivos y manejo de errores solo para el “camino feliz” pueden convertir un fallo de proveedor en una caída completa. La solución empieza por tratar la falla de una dependencia como algo normal, no excepcional.
Circuit breakers en un minuto: qué hacen y por qué
Un circuit breaker es una protección alrededor de una llamada externa. Cuando una dependencia empieza a fallar, dejas de llamarla por un tiempo corto. Eso evita más tráfico, más errores y más hilos bloqueados. En lugar de que cada solicitud se quede colgada, fallas rápido y cambias a un fallback.
Los circuit breakers suelen moverse por tres estados:
- Cerrado: las llamadas fluyen con normalidad y registras resultados.
- Abierto: el proveedor parece poco saludable, así que se bloquean las llamadas inmediatamente y devuelves una respuesta controlada.
- Semiabierto: después de un periodo de enfriamiento, permites un pequeño número de llamadas de prueba para ver si el proveedor se recuperó.
Esto no es lo mismo que “añadir reintentos y timeouts”. Un timeout limita cuánto esperas, pero todavía puedes acumular mucho trabajo en espera cuando un proveedor es lento. Los reintentos pueden multiplicar el tráfico en el momento justo equivocado. Un breaker añade una regla de más alto nivel: has visto suficientes fallos, así que deja de intentar por ahora.
Cuando está bien configurado, el resultado es intencionalmente aburrido:
- Los usuarios obtienen una respuesta rápida, aunque degradada (datos en caché, trabajo en cola o un claro “intenta de nuevo pronto”).
- Tus servidores se mantienen responsivos porque no están esperando a una dependencia fallida.
- Los incidentes se contienen porque una dependencia inestable no desencadena una reacción en cadena.
Ejemplo: si el flujo de registro envía un correo de confirmación y la API de correo empieza a hacer timeouts, un breaker puede detener los intentos de envío por unos minutos y encolar los correos para más tarde. Los usuarios aún pueden crear una cuenta en lugar de ver la página girar y fallar.
Las bases de código generadas por IA a menudo omiten este patrón o lo conectan mal. FixMyMess suele ver timeouts largos junto con reintentos agresivos, lo que convierte un tropiezo del proveedor en una caída. Un circuit breaker es una de las formas más rápidas de hacer que las fallas de dependencias sean previsibles.
Dónde añadir circuit breakers primero (los puntos de mayor impacto)
Empieza donde una dependencia pueda bloquear toda la app. Los mejores objetivos iniciales no son “funciones raras”. Son llamadas en pantallas de alto tráfico y flujos críticos.
Una forma simple de priorizar es pensar en dos dimensiones:
- Riesgo: el proveedor falla, se ralentiza o impone límites con frecuencia.
- Radio de alcance: una llamada lenta bloquea muchas solicitudes, ata hilos de trabajo o rompe un flujo de usuario crítico.
Elige dependencias que fallen ruidosamente (y con frecuencia)
Los servicios de terceros en la ruta crítica merecen protección primero: pagos, email/SMS, proveedores de autenticación y APIs de LLM. Están fuera de tu control y pueden degradarse sin aviso.
Si solo proteges una cosa, elige la dependencia que puede parar dinero o acceso. Un checkout que se queda colgado es peor que un recibo retrasado. Un timeout en el login es peor que análisis perdidos.
Enfócate en endpoints ligados a acciones críticas
Los breakers importan más en endpoints donde los usuarios intentan completar algo: login, registro, onboarding, checkout, restablecer contraseña y cualquier acción de “enviar” que deba devolver rápido.
Para elegir los primeros puntos de llamada, haz esto:
- Identifica tus endpoints principales por tráfico e impacto de negocio.
- Mapea las llamadas externas que hace cada endpoint.
- Señala llamadas sincrónicas dentro del camino request/response.
- Decide qué significa “falla” (timeouts y 5xx, pero también payloads malos o incompletos).
- Confirma qué pasa hoy cuando la dependencia es lenta (spinners, acumulación en colas, agotamiento de hilos).
Los equipos a menudo se sorprenden por lo que cuenta como fallo. Un proveedor puede devolver HTTP 200 con un payload roto, campos faltantes o un token que no puedes usar. Trata eso también como fallo, o el breaker no se abrirá cuando deba.
Ejemplo: si el onboarding llama a un LLM para generar un mensaje de bienvenida y esa llamada tarda 20 segundos, los usuarios asumen que el registro está roto. Pon el breaker alrededor de esa llamada, fija un timeout claro y devuelve un mensaje por defecto simple.
El código heredado generado por IA puede complicar esto porque las llamadas a dependencias están enredadas en handlers y rutas. Un primer movimiento práctico es aislar cada proveedor detrás de una frontera limpia para poder añadir timeouts, breakers y fallbacks sin reescribir todo.
Las perillas que importan: timeouts, umbrales y ventanas de reinicio
Un circuit breaker solo es tan bueno como sus ajustes. Si es muy laxo, los usuarios aún sentirán la caída. Si es muy estricto, bloquearás tráfico sano.
Timeouts: decide cuánto tiempo estás dispuesto a esperar
Elige un timeout por petición según lo que esté haciendo el usuario. Para un botón “Guardar”, esperar 10 segundos se siente roto. Para sincronización en background, puedes tolerar más.
Una regla útil: el timeout debe ser más corto que el tiempo que tu app puede permitirse quedarse bloqueada. Si es demasiado alto, las solicitudes se acumulan, los workers se tapan y una pequeña ralentización del proveedor se convierte en una caída de la app.
Los reintentos ayudan solo cuando los fallos son breves y el proveedor no está sobrecargado. Reintentar después de timeouts suele empeorar las cosas porque duplicas el tráfico justo cuando la dependencia está luchando.
Umbrales y recuperación: cuándo abrir y cuándo probar
Necesitas tres números: cuándo abrir, cuánto esperar y cómo probar la recuperación.
Un punto de partida práctico:
- Abrir después de un pico claro, por ejemplo 5 fallos en las últimas 20 llamadas.
- Esperar 30 a 60 segundos antes de volver a probar.
- En semiabierto, permitir 1 a 3 llamadas de prueba, no un aluvión.
- Mantener reintentos en 0 o 1, y solo para peticiones seguras e idempotentes.
- Fijar timeouts por endpoint, a menudo 1 a 3 segundos para acciones orientadas al usuario.
Las probes en semiabierto son el “tocar el agua con el pie”. Tras la ventana de reinicio, dejas pasar un número pequeño y controlado de solicitudes. Si tienen éxito de forma consistente, cierras el circuito. Si fallan, lo vuelves a abrir.
Ejemplo: si un proveedor de correo envía códigos de login y empieza a hacer timeouts, usa un timeout corto para que la UI no se quede colgada, abre el breaker tras unos fallos y prueba cada minuto. Los usuarios obtienen un siguiente paso claro en vez de spinners sin fin.
Si heredaste una base de código generada por IA con bucles accidentales de “reintentar para siempre”, arreglar estos ajustes suele ser uno de los cambios de mayor apalancamiento.
Paso a paso: implementar un circuit breaker sin sobreingeniería
La forma más rápida de obtener valor es mantenerlo centralizado. No distribuyas comprobaciones por todos lados. Pon el comportamiento en un solo lugar para poder ajustarlo después sin buscar por docenas de archivos.
Un flujo simple que funciona en la mayoría de apps
Crea un “client” wrapper por cada dependencia externa (pagos, email, IA, auth, envíos). Todas las llamadas pasan por ahí. Ese wrapper administra timeouts, reintentos, estado del breaker y logs.
Una implementación sencilla suele verse así:
- Centraliza las llamadas en un módulo con una sola interfaz.
- Normaliza errores en un conjunto pequeño que tu app entienda (timeout, no disponible, bad request).
- Rastrea resultados recientes en una ventana rodante y abre el circuito cuando los fallos superen tu umbral.
- Cuando está abierto, falla rápido y devuelve un fallback seguro.
- Tras un cooldown, prueba con cuidado y solo cierras tras un éxito real.
Qué significa en la práctica un “fallback seguro”
Un fallback no debe fingir que todo funcionó. Debe mantener al usuario avanzando sin empeorar las cosas.
Si el email falla, acepta el envío del formulario, muestra confirmación y encola el correo para más tarde. Si una API de precios está caída, muestra precios en caché con una marca de tiempo y una nota clara si pueden estar desactualizados. Si una llamada está ligada a dinero o seguridad, sé explícito sobre la incertidumbre.
Mantén las decisiones de fallback cerca del wrapper. El resto de la app debe llamar a sendEmail() o chargeCard() y recibir un resultado claro.
Un fallo común en prototipos heredados es que una API de terceros se llame desde múltiples rutas con distinto comportamiento de reintentos. Funciona en testing y luego se queda en timeout en producción y dispara reintentos por todas partes. Un wrapper con un timeout real, fallo rápido y cooldown detiene la acumulación y protege tu base de datos y colas.
Diseñar fallbacks con los que los usuarios puedan convivir
Los circuit breakers detienen la hemorragia. Los fallbacks mantienen a los usuarios en movimiento. Un buen fallback es honesto, seguro y fácil de explicar.
Empieza por nombrar el objetivo del usuario para cada llamada a dependencia. Si el objetivo es “ver mi saldo”, un fallback puede ser “mostrar el último saldo conocido con marca de tiempo”. Si el objetivo es “terminar checkout”, un fallback puede ser “guardar la solicitud de pedido y confirmar después”, no “fingir que se procesó”.
Tipos útiles de fallback incluyen datos en caché, trabajo en cola, UI degradada, revisión manual y proveedores alternativos (solo cuando son realmente equivalentes). La regla más importante: no mentir. La gente perdona “Lo confirmaremos en breve” mucho más que cargos dobles.
Decide cuándo mostrar un mensaje frente a degradar en silencio según el impacto. Si el usuario puede tomar una decisión equivocada (dinero, seguridad, plazos), muestra un mensaje claro y el siguiente paso. Si es cosmético, degradar en silencio puede estar bien.
Hazlo observable (para arreglarlo rápido)
Los fallbacks sin logs convierten incidentes en adivinanzas. Captura suficiente contexto para entender qué pasó:
- Qué intentó hacer el usuario (y entradas clave que puedas almacenar de forma segura)
- Estado del proveedor (timeout, 500, rate limit, circuito abierto)
- Un ID de correlación entre request, llamada a proveedor y ruta de fallback
- El resultado (enviado a cola, cacheado, revisado manualmente)
- El mensaje mostrado al usuario
Las apps generadas por IA a veces tienen fallbacks, pero nadie puede decir qué camino se ejecutó. La solución es simple: haz cada fallback explícito, rastreable y veraz.
Un ejemplo realista: el proveedor de pagos empieza a fallar al mediodía
Son las 12:10 pm un martes. Tu checkout está sano, pero depende de una API de pagos de terceros. El proveedor empieza a hacer timeouts. No falla duro, solo se queda colgado entre 10 y 20 segundos.
Sin protección, el problema se propaga. Cada petición de checkout espera, luego reintenta. Las solicitudes atascadas se acumulan, ocupando workers y conexiones de base de datos. Los clientes refrescan y hacen clic en “Pagar” otra vez. Algunas solicitudes pasan, otras no, y terminas con páginas lentas, intentos duplicados y una bandeja de soporte llena de “¿Me cobraron?”.
Con un circuit breaker, la historia cambia rápido. Tras una breve racha de timeouts, el breaker se abre para el cliente de pagos. El checkout deja de esperar 20 segundos para descubrir lo obvio. Falla rápido y muestra un mensaje claro como: “Los pagos están temporalmente no disponibles. Tu pedido está guardado. Intenta de nuevo en unos minutos.”
En lugar de disparar más llamadas de pago, la app registra la intención (carrito, total, usuario, ID de pedido pendiente). Si puedes, encola un intento de pago para más tarde u ofrece un método alternativo. La clave es que los usuarios obtienen un resultado rápido y honesto, y el sistema se mantiene responsivo.
Cuando el breaker se abre, también obtienes señales más limpias: “dependencia de pagos caída” en lugar de lentitud vaga por todas partes. La recuperación no es trabajo de héroe. Tras una ventana de reinicio, el circuito pasa a semiabierto, envía unas pocas probes y se cierra si el proveedor vuelve a estar sano.
Errores comunes que empeoran las caídas
Las caídas suelen empeorar porque la app sigue empujando, esperando y bloqueando hasta que todo se llena. Los circuit breakers ayudan, pero solo si evitas algunas trampas.
Los reintentos inmediatos e infinitos son un amplificador clásico. Si un proveedor tiene un tropiezo y miles de clientes reintentan a la vez, creas tu propio pico de tráfico y mantienes al proveedor abajo más tiempo.
Los timeouts faltantes son otro problema. Sin un timeout claro, las solicitudes quedan colgadas, las colas crecen, los servidores se ralentizan y pronto incluso las partes sanas de la app se sienten rotas.
También cuidado con el scope del breaker. Un breaker global compartido entre funciones no relacionadas es un arma de doble filo. Una caída de pagos no debería bloquear a los usuarios para iniciar sesión o leer sus propios datos. Limita los breakers a una sola dependencia y un solo tipo de llamada.
Cinco señales de alerta rápidas:
- Reintentos que se disparan instantánea y eternamente (sin backoff ni límite)
- Timeouts ausentes o tan largos que las solicitudes se acumulan
- Un breaker compartido entre muchas dependencias o endpoints
- Un fallback que informa “éxito” cuando la acción no ocurrió
- Un circuito que se abre pero nunca prueba la recuperación
Fallbacks que no mientan
El fallback más dañino oculta la falla. Si un usuario hace clic en “Pagar ahora”, el proveedor falla y la app muestra “Pago completado”, tendrás disputas y clientes enfadados.
Un fallback más seguro es honesto y específico: “No pudimos procesar el pago. Tu pedido está guardado. Intenta de nuevo en unos minutos.” Cuando sea posible, mantiene al usuario avanzando: guarda progreso, ofrece acceso de solo lectura u otro flujo alternativo.
Chequeos rápidos que puedes hacer hoy
Unos pocos chequeos rápidos pueden prevenir el día en que “un proveedor inestable lo derrite todo”.
Comienza con tus tres dependencias externas principales (pagos, auth, email/almacenamiento) e inspecciona las rutas de código que las llaman:
- Cada llamada saliente tiene un timeout real que elegiste a propósito.
- Los reintentos están limitados e intencionales. No reintentes nada que pueda causar cargos o escrituras duplicadas a menos que tengas idempotencia.
- Cada dependencia crítica tiene un plan B que el usuario pueda entender.
- Los cambios de estado del breaker son visibles en logs (y de preferencia en un dashboard).
- La recuperación es automática mediante probes semiaabiertos seguros.
Para probar rápido, simula una falla del proveedor durante cinco minutos en un entorno seguro. Haz que la llamada falle (red bloqueada, forzar 500), confirma que los usuarios obtienen un resultado predecible (mensaje, caché o trabajo en cola), confirma que el breaker se abre y luego restaura el proveedor para verificar que se recupera sin intervención manual.
Siguientes pasos: hacer que las fallas de dependencias sean aburridas, no catastróficas
Escribe tus dependencias principales y los flujos de usuario exactos que tocan: “Checkout”, “Iniciar sesión”, “Restablecer contraseña”, “Enviar invitación”. Luego decide qué es “suficientemente bueno” si cada una está caída. A veces la respuesta correcta es simplemente fallar rápido con un mensaje claro y reintentar de forma segura más tarde.
Después de eso, añade una capa wrapper por proveedor para que timeouts, reintentos, el patrón de circuit breaker y el logging vivan en un solo lugar. Si solo haces una cosa esta semana, elige la dependencia ligada a ingresos o acceso.
Si estás heredando una app generada por IA que se descompone bajo tráfico real, FixMyMess (fixmymess.ai) puede hacer una auditoría gratuita de código y señalar timeouts faltantes, bucles de reintentos riesgosos y manejo débil de fallos de dependencias. A menudo es posible estabilizar rápidamente las integraciones más problemáticas añadiendo wrappers limpios, valores por defecto sensatos y fallbacks honestos.
Preguntas Frecuentes
¿Qué es una falla en cascada, en términos sencillos?
Una falla en cascada ocurre cuando una dependencia lenta o con errores hace que tu app espere, y esas solicitudes esperando se acumulan hasta que las partes sanas se quedan sin hilos, conexiones o capacidad de cola. La solución es dejar de esperar indefinidamente y dejar de llamar repetidamente al servicio con problemas para que el resto de la app siga respondiendo.
¿En qué se diferencia un circuit breaker de simplemente añadir timeouts y reintentos?
Un circuit breaker es una regla alrededor de una llamada externa que evita que las peticiones sigan golpeando a una dependencia cuando está claramente enferma. En vez de quedarse colgada, tu app falla rápido y devuelve un resultado controlado (por ejemplo datos en caché o “intenta de nuevo más tarde”), lo que evita que tus servidores se atasquen.
¿Cómo elijo un timeout sensato para una petición orientada al usuario?
Empieza por la tolerancia del usuario: para un clic de botón o carga de página, apunta a un timeout corto que mantenga la UI ágil (a menudo un par de segundos, no 20). Si la llamada es opcional, el timeout puede ser aún más corto y degradar con gracia; si es realmente crítica, es mejor fallar rápido con un mensaje claro en lugar de dejar que las solicitudes se acumulen.
¿Cuándo debo evitar reintentos y cuándo son seguros?
Evita reintentos por defecto para cualquier cosa que pueda generar efectos secundarios duplicados, como cobros, envíos o escrituras. Los reintentos son seguros para lecturas idempotentes, y aun así conviene añadir backoff y limitar el tiempo total para no amplificar una caída.
¿Dónde debo añadir circuit breakers primero para el mayor impacto?
Pon breakers alrededor de llamadas sincrónicas en la ruta crítica: autenticación/login, checkout/pagos, email/SMS para códigos y cualquier API que las pantallas principales necesiten para renderizarse. Obtendrás el mayor impacto donde una dependencia puede bloquear muchas solicitudes y agotar recursos compartidos como pools de conexiones.
¿Qué significan realmente los estados closed, open y half-open?
“Closed” significa que las llamadas fluyen normalmente mientras rastreas fallos. “Open” significa que bloqueas temporalmente las llamadas y devuelves una respuesta controlada. “Half-open” significa que, tras un enfriamiento, permites unas pocas llamadas de prueba para comprobar si la dependencia se recuperó antes de cerrar el circuito por completo.
¿Cuál es un buen fallback cuando un proveedor está caído?
Un buen fallback mantiene al usuario avanzando sin fingir que todo funcionó. Por ejemplo, si el envío de correo falla, acepta el registro y encola el correo; si una API de precios falla, muestra el último valor conocido con la hora y una nota de posible desactualización. Para dinero o seguridad, sé explícito sobre lo que sí y no ocurrió.
¿Debo usar un único circuit breaker global para todo?
Haz que el scope del breaker coincida con la dependencia y el tipo de llamada, no con toda la app. Una caída de pagos no debería bloquear la lectura del perfil, y una falla de email no debería romper el login. Si scopeas demasiado, un proveedor inestable puede deshabilitar funciones no relacionadas innecesariamente.
¿Cómo puedo probar circuit breakers sin causar una caída real?
Simula la dependencia fallando durante unos minutos en un entorno seguro y verifica tres cosas: las peticiones fallan rápido, los usuarios ven un resultado predecible y el sistema se mantiene responsivo bajo carga. Luego restaura la dependencia y confirma que el circuito pasa por probes half-open y se recupera automáticamente sin intervención manual.
¿Por qué las apps generadas por IA fallan tanto con proveedores inestables y qué puede hacer FixMyMess?
El código generado por IA suele asumir solo el camino feliz: timeouts largos o inexistentes, bucles de reintentos agresivos y llamadas a proveedores repartidas por routes. Si heredaste un prototipo que se rompe con tráfico real, FixMyMess puede hacer una auditoría gratuita de código y estabilizar las integraciones más problemáticas añadiendo wrappers limpios, timeouts sensatos y fallbacks honestos, a menudo en 48–72 horas.