Inventario de PII para la base de datos de un prototipo: localizar y reducir datos
Inventario de PII para prototipo: localiza correos, nombres y tokens, reduce lo que recopilas y fija reglas claras de expiración.
Por qué necesitas un inventario de PII antes de que tu prototipo crezca
Los prototipos recopilan datos sensibles más rápido de lo que crees. Un formulario de registro simple añade correos y nombres. Un flujo de invitación crea más correos. El inicio de sesión añade tokens. Los logs de depuración los copian de nuevo. Antes de darte cuenta, tu "app de prueba" contiene datos de personas reales en lugares que nunca pensaste mantener.
El riesgo no es solo una brecha. También es confusión y rehacer trabajo. Si los correos y tokens quedan por ahí sin dueño, no puedes responder preguntas básicas: ¿Quién puede ver estos datos? ¿Cuánto tiempo los guardamos? ¿Podemos eliminarlos si alguien lo pide? Cuando el prototipo se convierte en un producto real, terminas haciendo una limpieza de emergencia mientras intentas lanzar nuevas funciones.
Un inventario de PII reduce ese riesgo rápidamente. No es papeleo. Es un mapa de por dónde pasan los datos personales, más un plan para recopilar menos y borrar a tiempo. Esa página cambia cómo construyes: dejas de añadir campos "por si acaso", detectas cuando los tokens se almacenan en texto plano y fijas una regla de retención antes de que la base de datos crezca.
Al final, quieres dos resultados: un mapa de datos claro (dónde se crean, almacenan, copian y envían correos, nombres y tokens) y un plan de retención (qué conservar, qué evitar recopilar y cuándo expirar o eliminar). En el proceso también terminarás con una lista corta de puntos de alto riesgo (logs, eventos de analytics, backups, vistas de administración, tablas olvidadas) y un responsable para cada almacén de datos.
Si heredaste un prototipo generado por IA (de herramientas como Bolt, v0, Cursor o Replit), esto importa aún más. Estas construcciones a menudo copian secretos en archivos de configuración, guardan tokens sin expiración o dispersan datos de usuario en varias tablas.
Qué cuenta como PII y datos sensibles en un prototipo
PII (información de identificación personal) es cualquier dato que pueda identificar a una persona real, ya sea por sí solo o combinado con otros campos. La parte de "combinado" es la que suele confundir a los equipos: un nombre de usuario más el nombre de la empresa, o una IP más una marca de tiempo, pueden apuntar a un usuario específico.
Empieza por los campos obvios del perfil de usuario y luego busca copias sombra fuera de tu tabla principal de usuarios.
PII común en prototipos incluye correos, nombres, números de teléfono, direcciones, nombres de usuario y alias, fecha de nacimiento, ubicación, fotos de perfil, metadatos relacionados con pagos (incluso si no guardas datos de tarjeta), direcciones IP e identificadores de dispositivo.
Algunos datos no siempre son PII, pero siguen siendo sensibles porque pueden desbloquear cuentas o sistemas. Trátalos como alto riesgo: tokens de autenticación, IDs de sesión, tokens de refresco, enlaces de restablecimiento de contraseña o códigos de un solo uso, claves API, secretos de clientes OAuth y secretos de firma de webhooks.
También incluye lugares que recopilan o duplican datos silenciosamente. Los prototipos suelen filtrar PII a logs (cuerpos de petición, trazas de error), eventos de analytics (por ejemplo, "invite_sent" con un correo), tickets de soporte (capturas de pantalla, tokens pegados) y CSV exportados compartidos en chat.
Un ejemplo sencillo: tu flujo de invitación guarda el correo del invitado en una tabla invites, registra la petición completa en caso de error y envía analytics con el mismo correo como propiedad. Eso son tres ubicaciones que hay que rastrear, expirar y eliminar.
Lista cada lugar donde tu app podría almacenar o copiar datos
Un inventario de PII comienza con una idea simple: los datos rara vez viven en un solo lugar. Los prototipos copian valores por conveniencia, y esas copias se convierten en lo más difícil de encontrar después.
Mapea la ruta completa de un dato de usuario (como un correo) desde el momento en que entra en tu app hasta todos los sitios donde podría acabar. Incluye lugares creados por tu framework, hosting y herramientas de terceros, no solo lo que programaste a propósito.
La mayoría de los equipos encuentran datos personales en unos cuantos contenedores:
- Tablas y columnas de la base de datos: tablas de usuarios, tablas de invitaciones, tablas de auditoría, tablas temporales y cualquier cosa que almacene payloads crudos de peticiones.
- Proveedor de autenticación y almacén de perfiles de usuario: correos y nombres pueden vivir en la base de datos de la app y también en un sistema de auth separado, a menudo con metadatos extra (último inicio, IP, dispositivo).
- Subidas de archivos y almacenamiento de objetos: imágenes de perfil, importaciones CSV, adjuntos y exportaciones generadas. Los nombres de archivo y el contenido pueden contener PII.
- Jobs en segundo plano, colas y cachés: los payloads de jobs suelen incluir objetos de usuario completos; las cachés pueden mantenerlos más tiempo del esperado; los reintentos duplican datos.
- Informes de fallos, logs de peticiones y paneles de administración: los errores pueden capturar headers, cookies y cuerpos de petición; las pantallas de administración y las exportaciones CSV se convierten en otra copia.
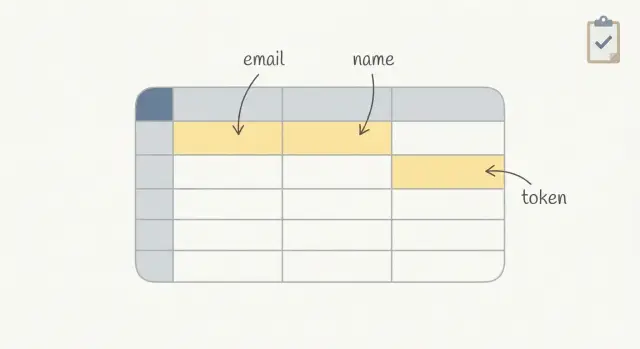
Para cada lugar, anota qué campos se almacenan (email, name, tokens), por qué se necesitan, quién puede acceder y cuánto tiempo permanecen por defecto. Si no puedes responder la pregunta de retención, asume "para siempre" hasta que fijes una expiración.
Un ejemplo rápido: un login con magic link podría guardar el correo en users, almacenar el token en login_tokens, copiar el correo en una cola de jobs para enviar el mensaje y luego filtrar el token en los logs de petición si lo incluyes en una URL.
Paso a paso: construye tu inventario de PII en una tarde
Empieza por los caminos reales que siguen las personas en tu app, no por tu esquema. Elige de 3 a 5 recorridos de usuario que ocurren hoy (o pasarán la próxima semana). Los comunes son registro, inicio de sesión, restablecimiento de contraseña, invitar a un compañero y checkout. Si solo documentas tablas, te perderás lo que se copia en logs, analytics y herramientas de soporte.
Para cada recorrido, anota cada campo que recoges y la razón simple por la que lo necesitas. Si no puedes explicar la razón en una frase, es buen candidato para eliminar o retrasar.
Luego traza cada campo de extremo a extremo: dónde entra (formulario o API), dónde se valida, dónde se almacena (tabla y columna) y dónde podría duplicarse (logs, jobs en segundo plano, trackers de errores, herramientas de correo).
Una hoja de trabajo simple (doc o spreadsheet) es suficiente. Usa una fila por campo y captura:
- Nombre del campo y un valor de ejemplo (para claridad)
- Propósito (por qué lo necesitas ahora)
- Etiqueta de tipo de dato: PII, sensible o no sensible
- Dónde fluye: petición, tabla/columna de BD, logs, terceros
- Quién puede acceder (pantalla admin, acceso directo a BD, herramientas de soporte)
Si tu prototipo fue generado por una herramienta de IA, añade una comprobación extra: busca logging de depuración y payloads de peticiones copiados. Esos son lugares comunes donde correos, nombres y tokens se almacenan por accidente.
Cómo localizar correos y nombres en tu base de datos
Empieza con un escaneo del esquema. La mayoría de los campos de correo y nombre no están ocultos; simplemente están dispersos. Abre la lista de tablas y busca lo obvio primero, luego las copias extra que se añadieron durante el prototipado rápido.
Revisa nombres de columna comunes en cada tabla, no solo users. Buscas tanto campos directos (email, first_name) como campos auxiliares (contact_email, displayName, invited_by).
Un enfoque rápido es buscar patrones en el esquema y luego confirmar con unas pocas filas de datos.
-- Postgres example: find likely PII columns
select table_name, column_name
from information_schema.columns
where column_name ilike '%email%'
or column_name ilike '%name%'
or column_name ilike '%contact%'
order by table_name, column_name;
Después de los campos obvios, busca lugares donde correos y nombres se ocultan dentro de texto libre o blobs. Las apps prototipo a menudo vuelcan la entrada del usuario en una columna metadata, notes, message o json y se olvidan de que existe.
Lugares comunes donde se esconden:
- Campos de texto libre y JSON (notes, message, metadata, profile, payload)
- Migraciones y scripts de seed que crearon usuarios de prueba con correos reales
- Tablas duplicadas (users más billing/customers más analytics/events)
- Colas y logs almacenados en la base de datos (jobs de correo, logs de invitaciones)
- Backups y snapshots (datos antiguos que pueden sobrevivir a las tablas principales)
Chequeo realista: si tu app tiene invitaciones, probablemente guardes correos en al menos dos lugares (el registro del usuario y la tabla de invitaciones). Anota dónde vive cada copia y cuál es la fuente de verdad.
Dónde viven los tokens y qué registrar sobre ellos
Los tokens suelen ser la vía más rápida para comprometer un prototipo. Actúan como llaves: si alguien copia uno, puede reutilizarlo para iniciar sesión, llamar APIs o restablecer una contraseña. Trata los tokens como datos sensibles aunque por sí solos no sean “personales”.
Tipos de token comunes: IDs de sesión, tokens de refresco, tokens de magic link, tokens de restablecimiento de contraseña y tokens API (para servicios de terceros o tus propios endpoints). El riesgo aumenta cuando los tokens son de larga duración, reutilizables o funcionan desde cualquier lugar sin comprobaciones adicionales.
Los tokens también aparecen en sitios donde nadie los espera:
- Tablas de la base de datos (sessions, auth_tokens, password_resets)
- Cookies del navegador (incluyendo "remember me")
- Local storage o session storage en el frontend
- Logs de aplicación y seguimiento de errores (headers de petición, query strings)
- Plantillas de correo y logs de correo saliente (magic links)
Para cada token, registra qué hace, dónde se guarda y cuánto tiempo permanece válido. Mantén las reglas simples: almacena lo mínimo, expira rápido, rota al usar y hashea tokens en almacenamiento cuando sea posible para que una fuga de la base de datos no dé acceso instantáneo.
Responde estas preguntas para cada token:
- ¿Qué acción permite este token (login, reset, acceso a la API)?
- ¿Dónde se almacena y copia (BD, cookie, logs, email)?
- ¿Cuál es su vida útil y puede reutilizarse?
- ¿Cómo se protege (hashed, encriptado, con ámbitos, ligado a dispositivo/IP)?
- ¿Qué ocurre al cerrar sesión, cambiar contraseña o cancelar una invitación?
Minimizar la recolección: conservar solo lo que tu prototipo necesita
Una base de prototipo se llena rápido porque es más fácil guardar todo que decidir qué importa. Ese hábito de "guardar todo" es cómo acabas con PII extra, tokens de larga duración y datos que no puedes explicar después.
Cuestiona cada campo con una pregunta: ¿qué se rompe si no guardamos esto? Si la respuesta es "nada, solo estaría bien", no lo recopiles todavía. Puedes añadir campos opcionales más tarde cuando estés seguro de que soportan una función real.
El perfilado progresivo ayuda a mantener simples las primeras inscripciones. Recopila lo mínimo para el primer paso (a menudo solo un correo), luego pide más solo cuando el usuario llegue a un punto donde sea necesario (facturación, invitaciones, soporte).
Recortes de alto impacto que funcionan en la mayoría de prototipos:
- Usa nombres para mostrar en vez de nombres legales completos a menos que haya una razón clara.
- No almacenes envíos de formularios crudos o payloads completos de peticiones para depuración. Registra el error y un ID de petición.
- Reduce campos de texto libre. Si debes tenerlos, añade una advertencia clara (no pegar secretos) y un límite de caracteres.
- Haz los campos "agradable tener" opcionales y muévelos a un paso posterior.
- Prefiere "país" sobre una dirección completa hasta que el envío lo requiera.
Ejemplo: un flujo de invitación suele tentar a los equipos a guardar nombre del invitador, nombre del invitado, nota personal e historial completo de emails. Para un prototipo, puede que solo necesites inviter user ID, invitee email, estado de la invitación y una marca de expiración.
Crea un plan de expiración y eliminación que puedas seguir realmente
Un inventario de PII solo es útil si termina con una regla simple: ¿cuándo expira cada cosa y cómo se borra?
Establece ventanas de retención por tipo de dato y escríbelas junto a cada tabla o campo en tu inventario, aunque aún no las estés aplicando:
- Inscripciones no verificadas: eliminar después de 7 días
- Cuentas abandonadas (sin inicio, sin actividad): eliminar después de 30–90 días
- Correos de soporte o formularios de contacto: eliminar después de 90 días
- Logs de auditoría (evita PII si es posible): conservar 30–180 días
- Backups: mantener la ventana más corta posible (para prototipos, 7–30 días suele ser suficiente)
Los tokens merecen su propia regla porque son fáciles de usar mal y difíciles de detectar después. Expira tokens de sesión y de restablecimiento rápidamente y asegúrate de poder invalidarlos pronto. Una línea base razonable es: tokens de acceso en minutos, tokens de refresco en días, y revocar todos los tokens al cambiar contraseña.
La eliminación automática es lo que hace real el plan. Añade un job de limpieza programado que se ejecute diariamente: elimina usuarios no verificados pasados de la fecha límite, borra registros de invitación tras aceptarse o tras una ventana corta, y limpia tokens antiguos.
Las solicitudes de eliminación por parte del usuario deben ser previsibles. Define el alcance para no perder copias ocultas:
- Eliminar el perfil de usuario y los registros de autenticación
- Eliminar o anonimizar contenido relacionado (comentarios, proyectos, archivos)
- Eliminar tokens, sesiones y claves API
- Quitar de exportaciones y herramientas de terceros de ahora en adelante
- Registrar un log mínimo de la eliminación (sin PII extra)
Los backups y exportaciones son la parte difícil. Puede que hoy no puedas borrar quirúrgicamente backups antiguos, pero puedes planificar a futuro: acorta la retención de backups, deja de exportar PII crudo por defecto y rota exportaciones antiguas según un calendario.
Controles de acceso y registros sin complicarlo
No necesitas una solución empresarial para proteger un prototipo. Necesitas roles claros, menos claves flotando y suficiente registro para responder a una pregunta más adelante: ¿quién miró o cambió datos sensibles?
Anota los únicos roles que realmente tienes hoy. La mayoría de prototipos encajan en un conjunto pequeño: fundador/admin (acceso total), soporte (solo lectura a registros de usuario), contratista (acceso solo a la parte que construye) y una cuenta admin de emergencia usada raramente. La meta es evitar que "todo el mundo puede verlo todo" se convierta en permanente.
Un plan de acceso sencillo que funcione:
- Da a cada persona su propio login. No usuarios compartidos de base de datos ni contraseñas admin compartidas.
- Limita el acceso directo a la base de datos a 1–2 personas. El resto usa la pantalla admin de la app.
- Usa acceso de solo lectura para soporte cuando sea posible y limita en el tiempo el acceso de contratistas.
- Revisa el acceso mensualmente y elimina cuentas que ya no se necesitan.
- Mantén una cuenta admin de emergencia, guardada de forma segura y usada solo cuando haga falta.
Los registros (logs) pueden mantenerse ligeros. Registra las acciones admin que tocan PII: ver un perfil de usuario, exportar usuarios, restablecer contraseñas, cambiar correos, generar enlaces de invitación. Incluso un log básico con timestamp, usuario admin, acción y registro objetivo es suficiente para detectar errores y responder preguntas.
Enmascara PII siempre que puedas. En pantallas de administración muestra solo lo necesario (por ejemplo, correo parcial como j***@domain.com). En logs, evita almacenar correos completos, nombres o tokens. Registra IDs en su lugar.
Por último, mantén secretos fuera del código y fuera de la base de datos. Claves API, secretos de firma JWT y sales de tokens de restablecimiento deben vivir en almacenamiento de secretos adecuado, no en un archivo de configuración o en una tabla de settings.
Ejemplo: inventario rápido de PII para un prototipo de signup e invitación
Imagina un prototipo generado por IA: los usuarios se registran con correo, crean un workspace e invitan a compañeros por correo. Funciona en pruebas, pero nadie ha documentado qué datos personales se almacenan dónde.
Recorre el flujo completo una vez (registro, invitación, restablecimiento de contraseña) y luego busca dónde aterrizan los datos y dónde se copian. En una configuración típica encontrarás PII en más de un sitio:
- Tablas de base de datos:
users(email, name),invites(invitee email, inviter id),audit_logs(a veces almacena payloads crudos) - Logs de la app: cuerpos de petición, logs de error, logs de jobs en segundo plano
- Proveedor de correo: plantillas, webhooks de eventos, logs de entrega que incluyen direcciones de destinatario
- Analytics/monitoring: identificadores de usuario, a veces correos completos si alguien los registró por error
- Cachés y colas: payloads de invitación o eventos de autenticación guardados más tiempo del esperado
Un hallazgo de riesgo común es el manejo de tokens. Por ejemplo, el prototipo podría almacenar un token de restablecimiento de contraseña en texto plano en una tabla password_resets, sin expiración (o con un valor por defecto de 30 días). Si alguien obtiene acceso de lectura a la base de datos, puede usar ese token para tomar cuentas. Registra si los tokens están hasheados, cuánto viven y si pueden usarse más de una vez.
Luego decide qué dejar de recopilar ahora y qué guardar para más adelante. Muchos prototipos no necesitan nombres completos en el registro, y las invitaciones normalmente no necesitan conservar el correo del invitado para siempre una vez que aceptan o la invitación expira.
Aquí tienes una tabla de retención simple que puedes pegar en un doc y asignar un responsable:
| Data type | Where it lives | Purpose | Owner | Expiry |
|---|---|---|---|---|
| Email (user) | users.email | Login + notifications | Product | Keep while account active; delete 30 days after closure |
| Name (optional) | users.name | Display only | Product | Collect later; if collected, delete with account |
| Invitee email | invites.email | Send invite | Engineering | Delete 7 days after invite accepted/expired |
| Reset token | password_resets.token | Password reset | Engineering | Store hashed; expire in 30 minutes; one-time use |
Errores comunes que mantienen PII y tokens dando vueltas
La mayoría de los prototipos no filtran datos por un gran fallo. Filtran porque pequeñas decisiones se acumulan y nadie vuelve a limpiarlas.
Una trampa común es tratar los datos de prueba como inofensivos. Los equipos pegan correos reales, nombres y teléfonos en archivos seed, pantallas admin y importaciones CSV. Una semana después, esa misma base de datos se copia al portátil de un compañero o a un servidor de staging. Ahora la PII real está en tres lugares y nadie recuerda de dónde vino.
Otra fuga silenciosa es registrar demasiado. Los logs de depuración que almacenan cuerpos de petición o headers a menudo capturan tokens de sesión, tokens de restablecimiento, enlaces de invitación o claves API. Esos logs viven más tiempo que los tokens y se comparten en tickets y chats.
Los tokens también se convierten en “datos para siempre” si mantienes tokens de refresco, tokens de magic link o tokens de invitación sin expiración (o sin job de limpieza). Eso crea una lista larga de credenciales aún válidas.
Copiar PII por conveniencia empeora todo: duplicar un correo en varias tablas, cachearlo en eventos de analytics o volver a guardarlo en una tabla de búsqueda. Tu inventario debe marcar cada copia para que puedas eliminar y expirar datos desde el lugar correcto.
Por último, escribe las decisiones. Sin una nota breve como "nunca registramos cabeceras Authorization", un arreglo rápido futuro volverá a traer el problema.
Checklist rápido y siguientes pasos
Haz esta pasada antes de compartir el prototipo con más usuarios. El objetivo es encontrar copias y asegurarte de que los datos no vivan para siempre.
Comprobaciones rápidas que detectan la mayoría de los problemas:
- Correos y nombres: busca en tablas, columnas JSON, eventos de analytics y volcados de depuración campos como
email,name,firstName,lastName,profile,invitee. - Tokens: anota dónde aparecen tokens de sesión, claves API y enlaces de restablecimiento (BD, cookies, localStorage, logs del servidor, herramientas de terceros).
- Secretos: escanea variables de entorno, archivos
.env, artefactos de build y páginas admin temporales en busca de claves codificadas. - Expiración: escribe qué debe expirar (invitaciones, restablecimientos, sesiones), la ventana exacta y qué job o código lo elimina.
- Acceso: lista quién puede ver datos de producción hoy (fundadores, contratistas, agencia, bandeja de entrada de soporte, dashboards de BD).
Una vez tengas respuestas, conviértelas en un pequeño conjunto de arreglos que puedas terminar esta semana. Limítalo a 3–5 items para que realmente se hagan.
Si tu prototipo fue generado por IA y empieza a fallar con usuarios reales, un diagnóstico dirigido del código puede ayudar a encontrar dónde se filtran PII, tokens y secretos. FixMyMess (fixmymess.ai) se centra en tomar prototipos generados por IA y dejarlos listos para producción; su auditoría de código gratuita es una forma práctica de obtener una lista clara de problemas antes de comprometerte con una reconstrucción mayor.
Preguntas Frecuentes
When should I create a PII inventory for my prototype?
Empieza tan pronto como personas reales puedan registrarse, iniciar sesión o ser invitadas. Incluso una app “de prueba” guarda rápidamente correos, tokens y entradas de registro que permanecen más tiempo del que imaginas.
What is a PII inventory, in plain terms?
Trátalo como un mapa de una página sobre los datos personales y sensibles: qué recoges, dónde se almacena o copia, quién puede acceder y cuándo caduca o se borra. Si no puedes responder “¿dónde más aparece este valor?”, el inventario aún no está completo.
What data should I treat as PII or sensitive in a prototype?
Correos, nombres, teléfonos, direcciones, nombres de usuario, direcciones IP, identificadores de dispositivo, localización, fotos de perfil y cualquier cosa que pueda identificar a alguien al combinarse con otros campos. También incluye datos “no exactamente PII pero peligrosos” como tokens de autenticación y claves API, porque permiten acceder a cuentas.
Where does PII usually hide outside the main database tables?
Los lugares habituales son logs, eventos de analytics, jobs en segundo plano, cachés, exportaciones (CSV), paneles de administración y herramientas de terceros como proveedores de correo o trackers de errores. Los prototipos suelen duplicar el mismo correo o token en varios de estos sitios sin que nadie lo note.
How do I build a PII inventory quickly without getting stuck?
Elige de 3 a 5 recorridos reales de usuario como registro, inicio de sesión, restablecimiento de contraseña e invitaciones. Para cada campo, anota dónde entra, dónde se almacena, dónde se copia, quién puede verlo y cuánto tiempo vive por defecto.
How can I find emails and names scattered across my database?
Escanea tu esquema buscando patrones comunes de nombres de columna y luego verifica con algunas filas de ejemplo. No te quedes en users; invites, audit logs, events y campos JSON de “metadata” suelen contener copias extra que olvidaste.
What should I record about session tokens and reset tokens?
Los tokens son sensibles porque funcionan como llaves. Para cada token, registra qué permite, dónde se guarda (BD, cookies, localStorage, logs, email), si caduca y si puede reutilizarse. Trata los tokens como datos críticos incluso si no identifican directamente a una persona.
How do I decide what PII to stop collecting in my prototype?
Por defecto, recoge lo mínimo necesario para la funcionalidad actual. Si no puedes explicar en una frase por qué hace falta un campo, aplázalo, hazlo opcional o elimínalo hasta que realmente lo necesites.
What’s a practical retention and deletion plan for a prototype?
Define reglas simples de retención por tipo de dato y hazlas reales con un job de limpieza diario. Empieza con ventanas cortas para inscripciones no verificadas, invitaciones, tokens de restablecimiento y logs; son los sitios donde los datos se acumulan con más facilidad y riesgo.
How do I handle PII issues in an AI-generated prototype that I inherited?
Haz un diagnóstico del código centrado en secretos, logging de depuración, almacenamiento de tokens y datos de usuario duplicados. Si heredaste un prototipo generado por IA de herramientas como Bolt, v0, Cursor o Replit y necesitas dejarlo listo para producción rápido, FixMyMess (fixmymess.ai) puede realizar una auditoría de código gratuita y ayudarte a corregir las filtraciones o a reconstruirlo limpio.