Límites de concurrencia para workers en segundo plano que protegen tu base de datos
Los límites de concurrencia para workers en segundo plano mantienen la carga de la base de datos estable limitando jobs paralelos y la profundidad de cola. Aprende reglas simples, comprobaciones rápidas y un ejemplo.
Por qué los trabajadores en segundo plano pueden abrumar tu base de datos
Un "pico en la BD" suele aparecer como una reacción en cadena. Páginas que iban rápido comienzan a colgar. Los inicios de sesión fallan. Ves timeouts en tu API y una pila creciente de jobs fallidos o reintentados. Aunque solo una función se ejecute en segundo plano, puede hacer que toda la app parezca rota porque la base de datos es el cuello de botella compartido.
Los workers sobrecargan las bases de datos más rápido que el tráfico web porque están pensados para ser persistentes y paralelos. Una petición web está limitada por las acciones de los usuarios y por timeouts de petición. Los workers, en cambio, sacan job tras job y corren tan rápido como permitan tus CPUs. Si cada job hace unas pocas consultas, eso se convierte en cientos o miles de consultas por minuto sin pausas naturales.
Lo complicado es que puede parecer "consultas lentas" cuando el verdadero problema es el paralelismo. Cuando demasiados jobs golpean la BD a la vez, la base de datos se queda sin conexiones, empieza a encolar trabajo internamente y todo se ralentiza en conjunto.
Síntomas que suelen apuntar a la concurrencia como causa raíz:
- Muchas consultas diferentes se ralentizan al mismo tiempo (no solo un endpoint)
- Errores del pool de conexiones o mensajes de "too many connections"
- Reintentos de jobs que se disparan justo después de un despliegue o al iniciar una tarea programada
- La CPU de la BD sube mientras el throughput deja de mejorar
El objetivo de un límite de concurrencia no es hacer los jobs más lentos. Es mantener un throughput estable en lugar de a ráfagas: carga de BD constante, menos incidentes y latencia consistente para usuarios reales.
Ejemplo: un job nocturno de "reconstruir índice de búsqueda" lanza 20 workers. Cada worker lee filas, actualiza estado y escribe progreso. El sitio está tranquilo de noche, pero la BD se satura y por la mañana el tráfico encuentra el sistema agotado y con cola.
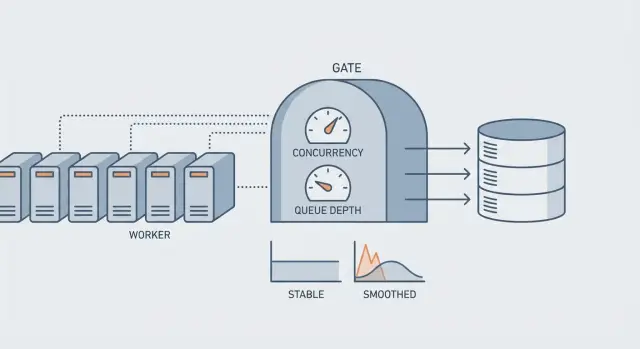
Concurrencia, tasa y profundidad de cola en términos simples
Cuando la gente dice "necesitamos más workers", suelen referirse a uno de tres controles. Cada uno resuelve un problema distinto, y tocar el equivocado puede sobrecargar tu base de datos.
Concurrencia es cuántos jobs se ejecutan al mismo tiempo. Si la concurrencia es 20, hasta 20 jobs pueden golpear tu BD en paralelo.
Tasa es la rapidez con la que arrancas jobs en el tiempo, como "5 jobs por segundo", incluso si podrías ejecutar más.
Profundidad de cola es cuántos jobs están esperando en la fila. La edad del backlog es cuánto tiempo lleva esperando el job más antiguo.
La profundidad de cola te dice volumen. La edad del backlog te dice dolor. Una cola puede ser muy profunda pero estar bien si se drena de forma constante. Una cola pequeña puede ser una crisis si los jobs están atascados y el más antiguo tiene horas de espera.
Por qué "más workers" suele empeorar las cosas al principio: los workers compiten en los mismos puntos calientes. El cuello de botella oculto suele ser la base de datos, ya sea por límites del pool de conexiones, locks en filas o tablas, o transacciones largas. Al aumentar la concurrencia no solo haces más trabajo; aumentas la contención. Las peticiones esperan conexiones de BD, las transacciones permanecen abiertas más tiempo, los locks duran más y todo se ralentiza.
Un ejemplo rápido: 10 workers ejecutan cada uno un job que mantiene una transacción durante 300 ms. Parece poco. Pero si esos jobs tocan las mismas tablas, duplicar a 20 workers puede duplicar las esperas por locks y llevar el tiempo de transacción a segundos. Tus peticiones web entonces pelean con los workers por conexiones y la app entera parece caída aunque solo esté sobrecargada.
Qué suele romperse primero en la base de datos
Cuando los workers hacen un pico, la primera falla muchas veces no es "la base de datos está lenta". Es "la base de datos no puede aceptar más trabajo ahora mismo". Eso aparece como timeouts, una pila de consultas en espera y tasas de error que saltan aunque la CPU parezca aceptable.
1) Agotamiento del pool de conexiones
La mayoría de apps tienen un pool de conexiones fijo por proceso. Cada hilo o proceso worker necesita una conexión para cada consulta que ejecuta. Si arrancas más workers de los que el pool puede manejar, empiezan a esperar por conexiones. Los workers en espera siguen consumiendo memoria y reintentando, lo que añade presión en todas partes.
Un patrón común: tu app web necesita 20 conexiones para mantenerse saludable, pero los workers ocupan el resto del pool y el sitio empieza a fallar en logins o checkouts.
2) Locks por transacciones largas
El locking es la siguiente falla habitual. Aunque las consultas sean rápidas, las transacciones largas mantienen filas bloqueadas. Si muchos jobs tocan las mismas filas o tablas calientes (por ejemplo actualizando el mismo usuario, balance, o un campo "last_processed_at"), el trabajo se vuelve serial: solo un job puede avanzar a la vez y el resto espera.
Las esperas por locks pueden parecer lentitud aleatoria, pero la causa raíz es demasiada paralelización sobre los mismos datos.
3) Patrones de consulta caros en los jobs
Los jobs suelen hacer trabajo pequeño en bucles cerrados, lo que genera muchas consultas. Culpables comunes: patrones N+1, actualizaciones por item en vez de batch, recalcular los mismos agregados repetidamente, faltas de índices en filtros de jobs y traer mucho más dato del que realmente se necesita.
4) Llamadas externas dentro de una transacción
Si un job abre una transacción y luego llama a una API externa (email, pagos, AI, almacenamiento) antes de hacer commit, la conexión de BD y los locks se mantienen mientras el worker espera en la red. Multiplica eso por workers paralelos y obtienes saturación rápida de conexiones.
Los límites de concurrencia ayudan, pero funcionan mejor junto con transacciones cortas y costos de consulta previsibles.
Cómo elegir límites sensatos (sin adivinar)
Un buen límite no es un número que "te parezca bien". Es un número que tu base de datos puede manejar en un mal día, cuando el tráfico es alto y los cache misses suben. La meta es simple: mantener la BD dentro de rangos seguros de conexiones y tiempo de consulta mientras sigues avanzando de forma constante.
Empieza con una base conservadora ligada a la base de datos, no al servidor de aplicación. Mira el pool de conexiones de la BD (o max connections) y reserva margen para tráfico web, tareas admin y migraciones. Luego considera cuánto tiempo mantiene una conexión un job típico.
Una línea base práctica:
- Reserva 50–70% de las conexiones de BD para tráfico online y trabajo desconocido.
- Usa el 30–50% restante como presupuesto total para todos los workers combinados.
- Empieza con baja paralelización (a menudo 1–3 workers por cola) y sube solo si la latencia de la BD se mantiene plana.
- Revisa tras añadir funciones. Límites que funcionaron el mes pasado pueden fallar tras un cambio de consulta o la falta de un índice.
No uses un solo número global para todos los jobs. Separa límites por cola según el impacto del negocio. Una cola crítica (restablecimiento de contraseñas, onboarding) debe seguir respondiendo aunque una cola masiva (backfills, imports) sea grande.
Algunos tipos de job son conocidos por “pelear” con la BD: exports, procesos de facturación, imports grandes, cualquier cosa que escanee tablas grandes. Pon topes por job en estos aunque el pool total de workers sea mayor. Por ejemplo, podrías permitir 10 workers en total pero solo 1 export a la vez.
También decide qué pasa cuando la cola crece. Si lo ignoras, a menudo obtienes picos sorpresa después cuando los workers intentan ponerse al día.
- Backpressure: ralentizar a los productores (reducir frecuencia, añadir delays, limitar encolados por minuto).
- Descartar trabajo: eliminar o fusionar jobs de bajo valor (coalescer duplicados, mantener solo el último).
- Diferir: mover tareas voluminosas a ventanas de poca carga con topes estrictos.
- Dividir: romper un job gigante en trozos más pequeños con un límite por trozo.
Paso a paso: establece límites de concurrencia y profundidad de cola
Empieza por nombrar tus tipos de job. Anota qué dispara cada job, con qué frecuencia corre y si lee o escribe muchas filas. Marca los que son costosos para la BD (imports, analytics backfills, "sincronizar todo", envíos de email que también actualizan estado). Esos son los primeros a controlar.
Después, fija un techo en cuántos jobs pueden correr a la vez y reparte ese techo entre colas. Una configuración común es tener una cola por defecto para trabajo normal y una cola "pesada" para jobs intensivos en BD. Esto evita que un tipo ruidoso robe todas las conexiones.
Una configuración práctica inicial:
- Límite global: mantiene el total de jobs concurrentes por debajo de tu presupuesto seguro de conexiones de BD.
- Límite por cola: da a los jobs pesados una porción menor que a los jobs rápidos.
- Límite por job (si se soporta): solo 1–2 del mismo job costoso a la vez.
- Prioridad: pon el trabajo orientado al usuario por delante del mantenimiento.
- Ventanas horarias: ejecuta colas pesadas en horas de baja actividad.
Luego limita la profundidad de cola. Decide qué ocurre cuando la cola está llena: pausar nuevos encolados, retrasarlos (con una hora programada) o rechazarlos con un error claro. Si tu cola pesada llega a 1.000 jobs, podrías dejar de aceptar nuevos imports masivos y pedir al usuario que lo intente más tarde.
Los reintentos también pueden crear picos. Añade jitter (pequeños retrasos aleatorios) para que los fallos no reintenten al mismo tiempo, y usa backoff que crezca rápido para errores de BD como timeouts.
Implementa cambios gradualmente. Reduce la concurrencia primero, observa la BD y luego sube límites en pasos pequeños. Si el tiempo de consulta sube o las conexiones se quedan pegadas en el máximo, retrocede antes de que los usuarios lo sientan.
Monitorización que te dice si los límites funcionan
Los límites funcionan cuando tu base de datos se mantiene estable aunque cambie el volumen de jobs. Deberías ver picos controlados, no caídas repentinas donde todo se ralentiza a la vez.
Señales de la base de datos que importan
Vigila un pequeño conjunto de métricas:
- Conexiones activas (y tiempo de espera del pool)
- Conteo de consultas lentas y p95 del tiempo de consulta
- Esperas por locks y deadlocks
- Uso de CPU y presión de memoria
- IOPS de disco y latencia de lectura/escritura
Si las conexiones están al máximo mientras la CPU está baja, probablemente tengas demasiadas consultas concurrentes esperando por locks o I/O. Si la CPU está al máximo y suben las consultas lentas, la BD está haciendo demasiado trabajo por consulta.
Señales de los workers que muestran si el throttling ayuda
Mide jobs en ejecución, jobs en cola, duración de jobs (p50 y p95), tasa de reintentos y dead letters. Un sistema sano tiene una cola que sube y baja, pero la edad del backlog se mantiene más o menos estable.
Alertas accionables:
- Edad del backlog subiendo durante 10–15 minutos
- Tasa de reintentos subiendo junto a timeouts de BD
- Conexiones de BD pegadas cerca del máximo durante varios minutos
- Duración de jobs incrementándose (especialmente p95)
Cómo decidir qué cambiar: si reducir la concurrencia calma las métricas de BD y mejora la duración de jobs, necesitabas límites más estrictos. Si bajar la concurrencia casi no ayuda pero las consultas lentas y esperas por locks siguen altas, necesitas consultas más rápidas o mejores índices, no solo throttling.
Ejemplo: si un job nocturno de emails causa reintentos y saltos en esperas por locks, el límite podría estar bien, pero la consulta que selecciona destinatarios quizá necesita tamaños de lote más pequeños o un índice mejor.
Errores comunes que aún provocan picos
Muchos equipos añaden límites y aun así sufren picos. Normalmente el límite se fijó según la capacidad del worker, no de lo que la base de datos puede manejar. Poner la concurrencia igual a los núcleos CPU puede parecer razonable, pero ignora el tamaño del pool de conexiones, la contención por locks y consultas lentas. Una BD puede colapsar mucho antes de que el host worker esté "ocupado".
El comportamiento de reintentos es otro generador silencioso de picos. Reintentos ilimitados, o reintentos que se disparan todos a la vez (como "reintentar en 30 segundos" para cada fallo), pueden crear una tormenta de reintentos. Un breve fallo se convierte en otro fallo cuando miles de jobs se despiertan y golpean las mismas tablas.
El diseño de la cola puede amplificar el problema. Si usas una sola cola para todo, el trabajo masivo puede dejar sin recursos al trabajo crítico. Un backfill enorme retrasa tareas orientadas al usuario, y alguien aumenta la concurrencia para ponerse al día, lo que golpea aún más la BD.
Durante incidentes, un error común es subir los límites para "limpiar la cola". Eso suele convertir una cola manejable en saturación del pool de conexiones. Puedes vaciar la cola más rápido, pero también aumentas timeouts, esperas por locks y deadlocks, de modo que la cola vuelve.
Guardarraíles que previenen fallos habituales:
- Basa la concurrencia en conexiones de BD y costo de consulta, no en núcleos de CPU.
- Añade jitter y backoff exponencial a los reintentos, con un máximo duro.
- Separa colas para trabajo crítico vs masivo.
- Considera subir límites solo como último recurso y hacerlo en pasos pequeños.
- Define una política clara de retraso, descarte o rechazo cuando la cola esté llena.
Lista rápida antes de ponerlo en producción
Antes de soltar workers en producción, asume el peor caso: un despliegue, un reinicio o una recuperación tras un fallo donde todos los workers se despiertan a la vez. Tu base de datos no distingue que los jobs están "en segundo plano"; solo ve una ola súbita de conexiones y consultas.
Checklist:
- Matemática de conexiones pico escrita. Suma servidores web + procesos workers x hilos de worker + scripts admin. Compáralo con el límite de conexiones de tu BD (y deja margen).
- Jobs pesados separados y capados. Pon los tipos más caros (imports, backfills, grandes envíos de email, sincronizaciones) en su propia cola con menor concurrencia que los jobs normales.
- Profundidad de cola con techo y vigilancia de edad del backlog. Un largo máximo evita acumulaciones infinitas y una alerta sobre el job más antiguo detecta ralentizaciones temprano.
- Los reintentos no crean tormentas. Espacia los reintentos, deténlos tras una ventana razonable y evita reintentos inmediatos en errores de BD relacionados con carga.
- Tienes una perilla de emergencia segura. Sabe cómo cortar la concurrencia de workers rápido (y cómo pausar solo la cola pesada) sin redeploy.
Un ejemplo práctico: si un job nocturno de reportes toca muchas filas, dale su propia cola con concurrencia 1–2, limita la profundidad de esa cola y alerta si el job más antiguo tiene más de 15 minutos.
Ejemplo: evitar que un job nocturno tumbe tu app
Imagínate una SaaS donde los usuarios están activos hasta tarde y a la 1:00 AM arranca un import nocturno. El import lee un CSV grande, enriquece cada fila y escribe actualizaciones en las mismas tablas que usa la app para inicios de sesión, dashboards y facturación.
Sin límites, el sistema de workers intenta acabar cuanto antes ejecutando tantos jobs como puede. En minutos, las conexiones a la BD tocan techo. Consultas de 50 ms pasan a tardar segundos. Las peticiones web hacen timeout. Luego empiezan los reintentos y tienes una segunda ola de trabajo encolado peleando por la misma BD.
Un plan simple cambia la historia:
- Pon los imports en su propia cola, separada de trabajo crítico (emails, webhooks, pagos).
- Limita la concurrencia de imports a un número pequeño según la capacidad de la BD (por ejemplo 3–5 workers).
- Añade un límite de profundidad de cola para que dejes de encolar nuevo trabajo cuando el backlog ya sea grande.
- Añade limitación de tasa alrededor de las operaciones más pesadas en BD (como upserts) para suavizar ráfagas.
Ahora el import tarda más, pero es predecible. Las peticiones de usuario mantienen una porción estable de conexiones. Si el import genera más trabajo del que el sistema puede manejar, espera en la cola en vez de formar un atasco.
El trade-off es simple: un job por lotes algo más lento a cambio de una app estable. La mayoría de equipos prefiere que el import termine más tarde si eso evita tickets de soporte y rollbacks de emergencia.
Cuando los límites no bastan (y qué cambiar después)
Los límites de concurrencia son una barandilla, no una cura. Si alcanzas los límites cada día y la cola nunca se pone al día, el problema suele ser el job en sí, no el número de workers.
Escala workers cuando el job ya es eficiente y solo tienes más volumen. Arregla la lógica del job cuando cada job es más pesado de lo necesario (demasiadas consultas, trabajo repetido o bloqueo de filas demasiado largo).
Reduce la carga en BD antes de añadir más workers
La mayoría de incidentes vienen de jobs que hacen muchas idas y vueltas a la BD en paralelo. Cambios que suelen dar resultado:
- Trabajo por lotes: update/insert en chunks en vez de fila por fila.
- Haz jobs idempotentes: seguros para reintentar sin duplicar efectos.
- Reduce viajes: trae lo necesario una sola vez y opera en memoria.
- Añade índices adecuados: los scans lentos se multiplican con paralelismo.
- Acorta transacciones: haz menos trabajo mientras mantienes locks.
Ejemplo: un job nocturno de "recalcular estadísticas" que carga 10,000 usuarios y hace 10 consultas por usuario derretirá tu BD aunque la concurrencia sea baja. Replantearlo para calcular por lotes (o con una consulta agregada) puede convertir una tormenta de consultas en unas pocas consultas previsibles.
Separación lectura/escritura: ayuda, pero no es mágica
Enviar trabajo solo de lectura a réplicas ayuda si el job realmente solo lee y las réplicas aguantan. No sirve cuando el problema son escrituras, locks o una tabla caliente que todos los jobs tocan. Vigila también el lag de réplicas: un job que lee réplicas y escribe en el primario puede tomar decisiones con datos obsoletos.
Si dependes del throttling para siempre, fija una meta concreta (por ejemplo reducir a la mitad las consultas por job o mantener runtime por job bajo 30 segundos) y revisa límites tras arreglar la carga de trabajo.
Próximos pasos para codebases generadas por IA
Las apps generadas por IA a menudo salen con valores peligrosos por defecto porque el objetivo suele ser "hacer que funcione" en vez de "que sobreviva en producción". Así acabas con colas sin límite, workers que lanzan tantas tareas como permite la máquina y sin backpressure cuando la base de datos empieza a degradarse.
Un patrón común: un job en segundo plano lee 50,000 filas y luego hace un write por registro sin batching. Aunque cada write sea rápido, la carga combinada puede saturar conexiones, crear acumulación de locks y convertir peticiones normales en timeouts. En ese escenario, poner límites sensatos ayuda, pero solo es parte de la solución.
Si heredaste un prototipo generado por IA de herramientas como Lovable, Bolt, v0, Cursor o Replit y ya muestra comportamiento de picos, FixMyMess (fixmymess.ai) puede empezar con una auditoría de código gratuita para localizar la fuente exacta de presión en la BD y recomendar ajustes seguros de workers y colas antes de que lo lances.
Preguntas Frecuentes
¿Por qué los workers en segundo plano saturan la base de datos más rápido que el tráfico web normal?
Los workers en segundo plano pueden ejecutarse de forma continua y paralela, por lo que generan una presión sostenida sobre la base de datos sin pausas naturales. Si cada job hace aunque sea unas pocas consultas, una alta concurrencia desemboca rápidamente en esperas del pool de conexiones, contención por locks y timeouts que afectan a toda la aplicación.
¿Cómo puedo saber si el problema es la concurrencia y no una consulta lenta?
Si muchas consultas no relacionadas se vuelven más lentas al mismo tiempo, eso suele indicar contención y no una sola consulta deficiente. Errores del pool de conexiones, aumentos de reintentos justo después de una tarea programada y subida de CPU en la BD sin mayor throughput también son señales claras de exceso de paralelismo.
¿Cuál es la diferencia entre concurrencia, limitación de tasa y profundidad de cola?
La concurrencia es cuántos jobs se ejecutan a la vez. El rate limiting (o tasa) es la velocidad a la que inicias jobs en el tiempo. La profundidad de la cola es cuántos jobs están en espera; la edad del backlog dice cuánto tiempo lleva esperando el job más antiguo. Subir la concurrencia cuando la BD es el cuello de botella suele empeorar la situación antes de mejorarla.
¿Qué se rompe primero en la base de datos durante un pico de workers?
Lo que suele romperse primero es el agotamiento del pool de conexiones: workers y peticiones web compiten por un número limitado de conexiones. Después vienen las transacciones largas y los locks en filas/tablas, que hacen que el trabajo se vuelva efectivamente serial y que más workers signifiquen más espera.
¿Por qué es peligroso llamar a APIs externas dentro de una transacción de BD?
Mantén las transacciones cortas y evita llamadas de red mientras la transacción está abierta. Si un job hace una llamada a una API externa dentro de una transacción, la conexión y los locks se mantienen mientras el worker espera, por lo que una pequeña latencia multiplicada por varios workers causa saturación de conexiones.
¿Cómo elijo un límite de concurrencia seguro sin adivinar?
Empieza por presupuestar conexiones de BD: reserva la mayor parte para el tráfico web y trabajo desconocido, y asigna el resto como presupuesto total para workers. Comienza con concurrencias bajas por cola y sube solo si la latencia de la BD y las esperas por locks se mantienen estables bajo carga.
¿Debería usar una sola cola para todo o separar colas?
Separa jobs por impacto y costo en BD para que el trabajo masivo no pueda dejar sin recursos a tareas críticas. Da a las colas pesadas menor concurrencia y considera topes por job para los «devoradores» de BD conocidos como exports, backfills e imports grandes.
¿Cómo debo limitar la profundidad de cola y qué debe pasar cuando está llena?
Fija un tope rígido y decide el comportamiento cuando se alcance: retrasar, pausar a los productores o rechazar trabajos masivos con un mensaje claro. Un límite de profundidad evita acumulaciones infinitas y te obliga a manejar la sobrecarga de forma deliberada en vez de dejar que la BD colapse.
¿Cómo prevengo que los reintentos creen un segundo pico?
Usa jitter más backoff exponencial con un máximo fijo, especialmente para timeouts de BD. Sin jitter, muchos jobs reintentan al mismo tiempo y generan una tormenta de reintentos que convierte una pequeña degradación en un segundo apagón.
¿Qué métricas me dicen si mis límites funcionan y qué debería cambiar después?
Vigila conexiones de BD y tiempos de espera del pool, p95 de consultas, esperas por locks/deadlocks y la edad del backlog junto al ratio de reintentos. Si bajar la concurrencia estabiliza métricas de BD y mejora la duración de jobs, entonces el límite era demasiado alto; si no, probablemente haya que optimizar consultas o añadir índices.