Limpieza de datos tras un prototipo apresurado: dedupe y reparación de integridad
Limpieza de datos tras un prototipo apresurado: pasos para deduplicar, reparar filas huérfanas, aplicar restricciones y validar con scripts repetibles.
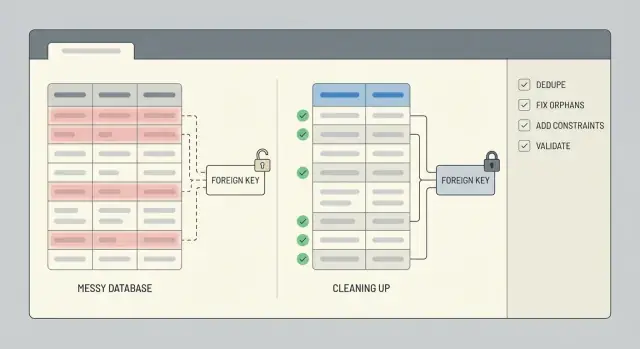
Qué suele romperse tras un prototipo apresurado
Un prototipo apresurado se construye para probar una idea, no para proteger tus datos. A menudo faltan reglas, los campos cambian de nombre a mitad del desarrollo y alguien acaba por "arreglarlo directamente en la base de datos" para superar un bloqueo. Si la app fue generada por una herramienta de AI, también verás patrones de copiar-pegar rápidos: tablas que se solapan, IDs almacenados como texto en un sitio y como números en otro, y lógica que guarda el mismo registro dos veces.
Los duplicados aparecen de formas aburridas y costosas: dos cuentas de usuario con el mismo email pero distinto uso de mayúsculas, varias suscripciones "activas" para un cliente, o la misma orden guardada una vez al hacer clic y otra al refrescar la página. A veces no son coincidencias exactas. Puedes ver casi-duplicados como "Acme, Inc" vs "ACME Inc." o dos contactos que comparten un número de teléfono.
Las relaciones rotas son igual de comunes. Encontrarás órdenes apuntando a un user_id que ya no existe, comentarios ligados a una publicación eliminada o filas que referencian 0 o una cadena vacía porque la app nunca validó la entrada. Esas filas huérfanas no siempre hacen que la app falle, pero silenciosamente rompen totales, dashboards y exportaciones.
La gente percibe datos malos como problemas de inicio de sesión, totales incorrectos (órdenes contadas doble, inventario inflado), historial faltante y pantallas de la UI que funcionan para unos registros pero no para otros.
Limpia ahora si vas a cobrar dinero, necesitas reportes fiables o el soporte pasa tiempo arreglando registros manualmente. Esperar lo hace más difícil porque cada nueva función escribe más datos encima del desorden.
Antes de tocar los datos: snapshot, alcance y rollback
La limpieza sale mal cuando empiezas a editar filas antes de saber qué importa y cómo deshacer cambios. Trata esto como una operación controlada, no como un arreglo rápido.
Empieza definiendo el alcance: las partes de la base de datos que afectan a personas reales y dinero. Lista las tablas y los flujos de usuario que soportan: registros, checkout, suscripciones, publicación de contenido. Si omites esto, puedes deduplicar una tabla y romper un flujo descendente que todavía espera la forma antigua.
Una nota sencilla de alcance suele ser suficiente: users, sesiones/tablas de auth, orders, payments, invoices, subscriptions y tablas de contenido núcleo (posts, comments, files). También anota la fuente de verdad para cada campo clave (por ejemplo, si confías más en un ID de proveedor de pagos que en un email).
A continuación, toma un snapshot seguro y define el rollback antes de ejecutar un solo UPDATE. El snapshot puede ser un backup de la base de datos, una restauración a un punto en el tiempo o una copia exportada de las tablas afectadas. Rollback no es "tendremos cuidado". Es un paso escrito: cómo restauras, cuánto tarda y quién puede hacerlo.
Siempre que puedas, ejecuta la limpieza en una copia primero. Un clon reciente de producción en staging es ideal porque contiene casos límite reales sin arriesgar datos en vivo. Solo mueve a producción cuando tus scripts sean repetibles y los resultados previsibles.
Por último, fija una ventana de tiempo. Si es posible, congela o bloquea escrituras riesgosas (nuevos registros, creación de órdenes, jobs de sincronización en segundo plano) durante la limpieza. Si no puedes congelar, registra una marca de tiempo de corte y limita tus cambios a registros creados antes de ese punto.
Decide qué es un duplicado (y qué conservarás)
Antes de borrar nada, sé específico sobre lo que "duplicado" significa para tu app. En un prototipo, dos filas pueden parecer idénticas para una persona pero representar usuarios o eventos distintos. Si te equivocas, la limpieza se convierte en pérdida de datos.
Empieza eligiendo una fuente de verdad por entidad. Para usuarios, puede ser el registro ligado a un login verificado, la cuenta más antigua o la referenciada por más órdenes. Para órdenes, podría ser la fila que realmente fue pagada, no la creada durante un checkout fallido.
Escribe reglas simples de fusión y síguelas. Decide cómo resolver conflictos y cómo tratar campos en blanco. Unas pocas reglas cubren la mayoría de casos:
- Si un registro tiene un valor y el otro es null, conserva el valor.
- Si ambos tienen valores, prefiere el verificado o el más recientemente actualizado.
- No sobrescribas campos de auditoría que te importen (
created_at,signup_sourcey campos similares).
Luego, decide la clave canónica que usarás para identificar duplicados. Opciones comunes son el email, un external_id de un proveedor de auth, número de teléfono o un compuesto como (workspace_id, normalized_email). Ten cuidado: los prototipos suelen guardar emails con distinto uso de mayúsculas, espacios extras o variaciones de plus-addressing.
Los casos límite son donde los equipos sufren. Buzones compartidos (team@), cuentas de prueba, CSVs importados con emails temporales y datos semilla generados por AI pueden crear repeticiones legítimas. Captura estas excepciones desde el inicio y mantén una lista corta de patrones que excluirás de la deduplicación.
Métodos para detectar duplicados
Empieza con la señal más simple: dos filas que comparten la misma clave. Incluso si tu prototipo nunca definió una clave verdadera, generalmente tienes algo cercano (email, external_id, order_number o una combinación natural como user_id más el día de creación).
Un primer pase rápido es un conteo por la clave sospechada, filtrado a claves que aparecen más de una vez:
SELECT email, COUNT(*) AS c
FROM users
GROUP BY email
HAVING COUNT(*) > 1
ORDER BY c DESC;
Después, busca casi-duplicados. Normaliza el campo en la consulta para ver colisiones que de otro modo perderías:
SELECT LOWER(TRIM(email)) AS email_norm, COUNT(*) AS c
FROM users
GROUP BY LOWER(TRIM(email))
HAVING COUNT(*) > 1;
También revisa duplicados creados por reintentos. Si tu app inserta el mismo evento dos veces tras un timeout, puedes ver múltiples filas con el mismo event_id, provider_charge_id, idempotency_key o (user_id + exact payload hash). Si no tienes esos campos, el patrón a menudo parece filas idénticas creadas con segundos de diferencia.
Antes de borrar o fusionar nada, construye una muestra pequeña para revisar. Elige los 20 grupos duplicados principales e inspecciónalos manualmente para saber qué significa "conservar". Extrae los conjuntos completos duplicados para revisión, compara timestamps, comprueba si filas hijas (órdenes, sesiones, facturas) apuntan a uno de los duplicados y escribe la regla que aplicarás. Guarda la consulta que produjo tu muestra para poder repetirla después de los cambios.
Dedupe sin perder historial importante
Si otras tablas apuntan a un registro, eliminarlo suele ser la forma más rápida de crear nuevos problemas. Un enfoque más seguro es fusionar duplicados y volver a apuntar todo al registro keeper para que el historial permanezca conectado.
Elige un keeper por cada grupo duplicado, mueve referencias de los IDs perdedores al keeper, luego archiva o marca inactivos los perdedores. Esto evita romper órdenes, facturas, mensajes y permisos que siguen necesitando estar ligados a la misma persona o cuenta.
Cuando los duplicados no concuerdan, decide de antemano cómo resolverás conflictos. Manténlo predecible: prefiere registros verificados sobre no verificados, estado pagado/activo sobre gratuito/inactivo, conserva los valores válidos más recientes cuando ambos parezcan razonables y nunca sobrescribas campos no vacíos con vacíos.
Mantén una pista de auditoría para que el trabajo sea reversible. Una tabla de mapeo pequeña como dedupe_map(old_id, new_id, merged_at, reason) te permite responder "¿qué pasó con este usuario?" meses después y acelera mucho la investigación.
No olvides los datos alrededor de la fila. Perfiles, settings, membresías, archivos subidos y notas suelen vivir en tablas separadas. Reapunta esas filas hijas primero y cuidado con choques de unicidad (por ejemplo, dos filas de configuración que deben convertirse en una sola).
Ejecuta la deduplicación por lotes (por ejemplo 100 a 1,000 grupos a la vez). Lotes más pequeños reducen el tiempo de bloqueo, hacen que fallos sean más fáciles de aislar y te dan oportunidad de inspeccionar resultados entre ejecuciones.
Encontrar y reparar filas huérfanas
Un huérfano es una fila que apunta a algo que no está ahí. Lo más común es una fila hija cuyo parent_id no coincide con ningún padre existente. Esto aparece mucho tras un prototipo apresurado, especialmente cuando la app omitió transacciones o eliminó registros sin limpiar las tablas relacionadas.
Empieza midiendo el problema. Un chequeo simple con left join te dice cuántas filas hijas no encuentran padre.
-- Ejemplo: orders deberían referenciar users
SELECT COUNT(*) AS orphan_orders
FROM orders o
LEFT JOIN users u ON u.id = o.user_id
WHERE u.id IS NULL;
-- Inspecciona una muestra para entender patrones
SELECT o.*
FROM orders o
LEFT JOIN users u ON u.id = o.user_id
WHERE u.id IS NULL
LIMIT 50;
Si usas borrados suaves (soft deletes), cuidado con los "huérfanos ocultos": el padre existe, pero está lógicamente eliminado (por ejemplo users.deleted_at IS NOT NULL). Decide si esos deben seguir contando como válidos.
Una vez que sabes con qué lidias, elige una ruta de reparación basada en lo que los datos significan:
- Recrear el padre faltante cuando realmente falló su guardado.
- Reasignar la fila hija a un padre real (común después de una dedupe de usuarios).
- Archivar o eliminar la hija si no se puede confiar en ella (datos de prueba, escrituras parciales).
- Crear un padre "Unknown" o "System" solo si la lógica del producto lo maneja de forma limpia.
Sea lo que sea que elijas, registra cada cambio para poder repetirlo de forma segura. Un patrón útil es: escribir cambios en una tabla de staging (o marcar filas con un batch ID), actualizar en pequeños lotes y registrar contadores antes y después.
Hacer cumplir la integridad con restricciones (y los índices correctos)
Después de la limpieza, las restricciones son lo que evita que el mismo desorden vuelva la próxima semana. Añádelas solo después de haber dedupeado y reparado relaciones rotas, o te bloquearás a ti mismo.
Empieza por las claves primarias. Asegúrate de que cada tabla tenga una, que sea realmente única y que nunca se vaya a reutilizar. Si tu prototipo usó IDs con significado (como un ID de usuario basado en hash de email), considera cambiar a una clave surrogate estable (un entero autoincremental o UUID) y tratar el valor con significado como un campo único separado.
Luego asegura los identificadores en los que el negocio realmente confía. Para muchas apps, eso significa una restricción única en email (a menudo insensible a mayúsculas) y en cualquier external_id que recibas de un proveedor de pagos, CRM o sistema de auth.
Las claves foráneas previenen filas huérfanas. Elige el comportamiento de borrado que refleje la realidad: a veces quieres bloquear eliminaciones, a veces quieres cascada y otras quieres conservar historial poniendo la FK a null. Ejemplo: si tu MVP permitía eliminar un usuario pero dejaba órdenes, puedes prevenir la eliminación cuando existan órdenes, o conservar órdenes y anonimizar al usuario.
Las check constraints atrapan valores malos temprano. Mantenlas simples: totales deben ser >= 0, status en un conjunto permitido, timestamps requeridos no nulos y cantidad > 0.
Finalmente, añade los índices correctos para que estas reglas no ralenticen todo. Las restricciones únicas y las claves foráneas usualmente necesitan índices de soporte, y vale la pena alinear índices con tus búsquedas más comunes (como órdenes por user_id).
Paso a paso: construir scripts de limpieza repetibles
Las correcciones de datos desordenados fallan cuando se hacen a mano, de forma ad hoc o sin un orden claro. Trata el trabajo como un pequeño release: aplica cambios en una secuencia que puedas repetir en staging y producción.
Una estructura simple de script
Usa migraciones ordenadas o scripts que sigan las mismas tres fases cada vez: setup, backfill, enforce. Mantén las consultas de solo lectura separadas de los pasos de escritura para que puedas revisar qué cambiará antes de actualizar nada.
Un flujo práctico que funciona en la mayoría de bases de datos:
- 01-detect.sql (solo lectura): lista duplicados, huérfanos y valores malos
- 02-setup.sql: añade tablas/columnas auxiliares (por ejemplo, una tabla de mapeo old_id -> kept_id)
- 03-backfill.sql: reasigna claves foráneas, fusiona filas, archiva lo que vas a eliminar
- 04-enforce.sql: añade restricciones únicas, claves foráneas e índices necesarios
- 05-validate.sql (solo lectura): comprobaciones que prueban que la limpieza funcionó
Haz que los scripts de escritura sean idempotentes (seguros de ejecutar dos veces). Usa guardas claras como WHERE NOT EXISTS (...), comprueba existencia de columnas/restricciones y prefiere upserts en tablas de mapeo. Envuelve updates riesgosos en una transacción cuando sea posible y falla rápido si no se cumplen precondiciones esperadas (por ejemplo, si un grupo duplicado tiene dos filas "activas").
Qué registrar en cada ejecución
Registra lo que cambias para poder explicar resultados y detectar regresiones más tarde. Como mínimo, anota contadores por paso: filas fusionadas, filas reasignadas, filas archivadas y filas no resueltas.
Un patrón útil es devolver contadores desde cada paso de escritura:
-- Ejemplo: reasignar filas hijas al padre conservado
UPDATE orders o
SET user_id = m.kept_user_id
FROM user_merge_map m
WHERE o.user_id = m.duplicate_user_id;
-- Ejemplo: archivar duplicados (con guardas)
INSERT INTO users_archived
SELECT u.*
FROM users u
JOIN user_merge_map m ON u.id = m.duplicate_user_id
WHERE NOT EXISTS (
SELECT 1 FROM users_archived a WHERE a.id = u.id
);
Almacena los scripts en control de versiones con un runbook corto (entradas, orden, tiempo estimado, notas de rollback).
Validar resultados con comprobaciones rápidas y tests repetibles
El trabajo no termina hasta que puedas demostrar que la base de datos es más segura que antes. Empieza escribiendo algunos números antes/después que puedas comparar cada vez que vuelvas a ejecutar la limpieza.
Mide métricas que muestren si el problema realmente disminuyó: filas totales, claves de negocio distintas, grupos duplicados y conteos de huérfanos. Guarda esos números en un archivo de texto pequeño o en una tabla para detectar regresiones más tarde.
Aquí hay algunas consultas que puedes volver a ejecutar después de cada arreglo:
-- Conteos de filas (sanity)
SELECT COUNT(*) AS users_total FROM users;
-- Claves distintas (¿funcionó la dedupe?)
SELECT COUNT(DISTINCT email) AS users_distinct_email FROM users;
-- Grupos duplicados (debería tender a 0)
SELECT email, COUNT(*)
FROM users
GROUP BY email
HAVING COUNT(*) > 1;
-- Huérfanos (filas hijas sin padre)
SELECT COUNT(*) AS orphan_orders
FROM orders o
LEFT JOIN users u ON u.id = o.user_id
WHERE u.id IS NULL;
Los números ayudan, pero no reemplazan el comportamiento real. Valida algunos flujos críticos de forma que coincidan con el uso de la app: ¿puede un usuario iniciar sesión?, ¿se carga una orden?, ¿sigue coincidiendo el total de una factura con sus items? Luego revisa al azar 10 a 20 registros reales de extremo a extremo.
Para evitar que esto vuelva a ocurrir, añade comprobaciones automatizadas ligeras que puedas ejecutar tras cada despliegue: un script que ejecute las métricas y falle si duplicados u huérfanos aumentan, una comprobación de restricciones (únicas, foráneas) en CI o una lista de verificación del release, y un job diario que reporte nuevas violaciones antes de que crezcan.
Si aún pueden entrar datos malos (trabajos de importación antiguos, validación laxa en la API), planifica limpieza continua: bloquea la fuente y mantén las comprobaciones activas.
Por qué los duplicados y huérfanos siguen regresando
Los duplicados y las filas huérfanas rara vez son un accidente puntual. Si tu app sigue creándolos, limpiar solo compra tiempo a menos que arregles las causas en el código y el flujo de trabajo.
Un disparador común son los reintentos. Un job en segundo plano hace timeout, reintenta e inserta la misma creación de "orden" o "invitación" porque no tiene una clave de idempotencia. El job hizo lo que se le indicó: lo hizo dos veces.
Los flujos asíncronos también pueden competir entre sí. Por ejemplo, un flujo de registro crea un usuario en una petición y crea un perfil en otra. Si la petición del perfil corre primero o el insert del usuario falla, obtienes un perfil huérfano. La falta de transacciones agrava esto porque el trabajo a medio hacer puede quedar comprometido.
Las acciones humanas importan también. Ediciones rápidas de admins o "arreglarlo en la base de datos" pueden saltarse las validaciones que la app aplica normalmente, especialmente cuando no hay restricciones que impidan escrituras malas. Las importaciones introducen otra vía: el CSV tiene emails con distinta capitalización, teléfonos con caracteres extra o external IDs inconsistentes, así que la misma persona llega como múltiples registros.
Guardarraíles que evitan la recaída
Apunta a unos cuantos cambios que bloqueen datos malos en origen:
- Haz las operaciones de creación idempotentes (almacena una request o event key e ignora repeticiones).
- Envuelve escrituras multi-paso en una transacción para que todo falle o todo pase.
- Normaliza identificadores antes de escribir (emails en minúsculas, formato de teléfono, IDs recortados).
- Restringe rutas de admin para usar la misma validación que la app, no actualizaciones directas.
- Añade restricciones + monitorización para que las fallas sean visibles y se corrijan rápido.
Si heredaste un MVP construido por AI, estos problemas son comunes. La base de datos suele no ser la causa raíz. Son las rutas de escritura laxas.
Ejemplo: limpiar usuarios y órdenes tras un MVP generado por AI
Un caso común es un flujo de signup generado por AI que crea una nueva fila de usuario en cada reintento. Si la misma persona toca "Sign up" tres veces, puedes acabar con tres cuentas que comparten un email pero tienen distintos IDs y datos de perfil parciales.
Ahora añade un segundo problema: tras un cambio de esquema, algunos usuarios fueron eliminados (o fusionados) sin actualizar tablas relacionadas. Las órdenes siguen apuntando al user_id viejo, así que tienes órdenes huérfanas que ya no coinciden con un usuario real.
Una forma práctica de arreglarlo sin adivinar:
- Elige un usuario canónico por email (por ejemplo, el que tenga
verified = trueo elcreated_atmás antiguo). - Crea una tabla de mapeo de IDs que registre
old_user_id -> canonical_user_id. - Actualiza órdenes uniendo a través de la tabla de mapeo para que cada orden apunte al
user_idcanónico. - Solo entonces elimina (o archiva) las filas de usuario extra.
- Añade protecciones para que el desorden no vuelva.
Tu tabla de mapeo puede ser tan simple como (old_user_id, canonical_user_id), poblada desde una consulta que agrupe por email y elija al ganador. Después de la actualización, ejecuta comprobaciones rápidas: cuenta usuarios por email, cuenta órdenes sin usuario y revisa manualmente algunos clientes de alto valor.
Finalmente, fija la integridad. Añade una restricción única en email y una clave foránea desde orders.user_id a users.id. Si te preocupa romper escrituras, añádelas después de la limpieza y prueba primero en una copia de producción.
Lista rápida y siguientes pasos
Al final, importan dos cosas: que los datos actuales sean correctos y que sea difícil que el mismo desorden vuelva. Mantén notas mientras trabajas para que otra persona pueda repetir el proceso.
Checklist para la limpieza en sí:
- Existe un snapshot reciente y sabes cómo restaurarlo.
- Las reglas de duplicado están escritas (campos de coincidencia, criterios de desempate, qué conservar).
- Se ejecutaron y guardaron consultas de detección con timestamps y contadores.
- Los cambios están registrados (IDs antes/después, fusiones, eliminaciones y decisiones manuales).
- Los scripts de limpieza pueden ejecutarse en una copia de producción y producir los mismos resultados.
Después de que los datos se vean bien, fíjalos para que permanezcan así:
- Se añadieron (o planearon) claves foráneas y restricciones únicas respaldadas por índices adecuados.
- Las comprobaciones de validación pasan (conteos de filas, integridad referencial, unicidad de claves, totales críticos).
- El rollback fue probado de punta a punta en una copia de staging.
- La monitorización tiene un responsable claro (alertas, informe semanal o una puerta de lanzamiento).
Si heredaste un prototipo roto generado por AI y necesitas un camino rápido y seguro a producción, FixMyMess (fixmymess.ai) se centra en diagnosticar la base de código, reparar lógica e integridad de datos y endurecer la app para que los mismos problemas no reaparezcan.
Preguntas Frecuentes
¿Cuándo debo dejar de agregar funciones y limpiar la base de datos?
Si tu app está a punto de cobrar dinero, si necesitas reportes fiables o si el soporte está corrigiendo registros manualmente, limpia ahora. Cuanto más esperes, más funciones nuevas y reintentos escribirán datos desordenados encima, haciendo que las fusiones y reparaciones sean más difíciles.
¿Cuál es el primer paso más seguro antes de ejecutar UPDATEs?
Empieza con un snapshot que puedas restaurar rápidamente y escribe el alcance y el plan de rollback antes de cualquier UPDATE. Si es posible, ejecuta la limpieza completa en una copia reciente de producción en staging para ver casos reales sin arriesgar datos en vivo.
¿Cómo decido qué cuenta como usuario duplicado?
Define duplicados usando una clave de negocio clara y una regla para elegir el registro que conservarás. Un criterio común es “el mismo email normalizado corresponde a un solo usuario”; guarda el registro verificado o el que esté referenciado por el historial importante, como órdenes pagadas.
¿Cómo encuentro casi-duplicados como diferencias en mayúsculas o espacios extra?
Normaliza el campo en tus consultas de detección —por ejemplo, recorta espacios y convierte el email a minúsculas— para atrapar colisiones que de otro modo perderías. Luego revisa manualmente una pequeña muestra de los grupos duplicados más grandes para confirmar que tus reglas coinciden con el comportamiento real.
¿Es mejor eliminar duplicados o fusionarlos?
No borres primero si otras tablas referencian la fila, porque así rompes el historial. Fusiona eligiendo un ID “keeper”, reapunta todas las claves foráneas al keeper y solo entonces archiva o desactiva las filas duplicadas.
¿Qué es una fila huérfana y por qué importa?
Un huérfano es una fila hija que apunta a un padre inexistente, por ejemplo una orden cuyo usuario falta. Puede que no haga fallar la app, pero rompe totales, exportaciones y genera casos de soporte —“¿por qué este registro está mal?”—.
¿Cómo arreglo órdenes o comentarios huérfanos sin adivinar?
Mide primero con una comprobación LEFT JOIN para contar y muestrear huérfanos; luego elige una ruta de reparación que tenga sentido. La mayoría de equipos reasigna la fila hija al padre correcto tras la deduplicación, o archiva/elimina filas que son datos de prueba o escrituras parciales.
¿Qué restricciones debería añadir para evitar que esto vuelva a pasar?
Añade restricciones después de la limpieza, no antes, para no bloquear tu propio trabajo. Una base sensata incluye restricciones únicas en identificadores reales (email normalizado o IDs de proveedores) y claves foráneas para relaciones que no deben romperse.
¿Cómo hago que mis scripts de limpieza sean seguros para ejecutarse varias veces?
Separa la detección de las escrituras y añade guardas para que volver a ejecutar no doble fusione ni archive de más. Registrar contadores y mantener una tabla simple de mapeo de IDs antiguos a los conservados facilita la investigación y la reversión.
¿Cómo valido que la limpieza funcionó y que la app no regresará al estado anterior?
Compara números antes y después para duplicados y huérfanos, luego valida flujos críticos de extremo a extremo como inicio de sesión y pago. Si heredaste un prototipo generado por AI y quieres remediación rápida y segura, FixMyMess se enfoca en diagnosticar el código y arreglar lógica, seguridad e integridad de datos con verificación humana.
¿Qué pasos finales aseguran que la base de datos se mantendrá limpia?
Define métricas antes y después (filas totales, claves distintas, grupos duplicados, huérfanos), ejecuta consultas de validación, y prueba flujos reales con muestreos. Además, añade comprobaciones automatizadas que se ejecuten tras cada despliegue y alerten si los problemas reaparecen.