Limpieza de dependencias y cadena de suministro para prototipos rápidos
Limpieza de dependencias y cadena de suministro para prototipos rápidos: audita paquetes, elimina deps no usadas, parchea CVE y reduce fallos tipo left-pad.
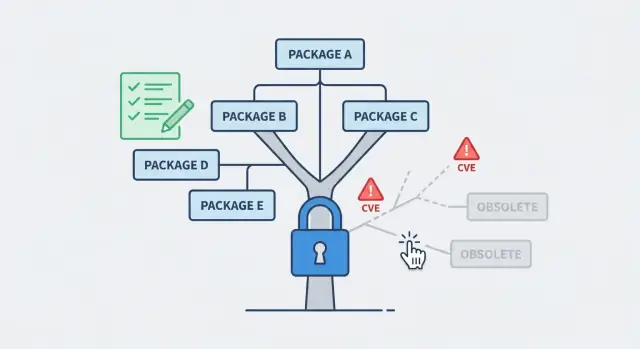
Por qué las dependencias de los prototipos se vuelven un problema
Los prototipos rápidos crecen agarrando el paquete más rápido que parece solucionar algo. Una librería de fechas aquí, un helper de auth allá, un kit de UI, un parser CSV, un “arreglo” copiado de un snippet. Tras unos días, nadie recuerda qué se añadió, por qué, o si todavía se usa.
Así es como la limpieza de dependencias y de la cadena de suministro se vuelve necesaria. El riesgo de la cadena de suministro es sencillo: tu app depende de código que no controlas. Si alguien publica una mala actualización, sufre un hack, retira un paquete o cambia el comportamiento, tu app puede romperse aunque no hayas cambiado nada.
Ayuda separar tres tipos de fallos distintos:
- Bugs: la lógica de tu app está mal (falla siempre de la misma forma).
- Vulnerabilidades: la app puede ser atacada (puede funcionar “bien” hasta que alguien la explote).
- Cortes/Outages: las instalaciones o builds fallan porque una dependencia cambió, desapareció o ya no encaja con tu entorno.
Los prototipos están especialmente expuestos porque a menudo usan rangos de versión flexibles y experimentos a medio terminar. Por ejemplo, un prototipo puede traer tres librerías solapadas para subidas, más una dependencia transitiva que luego se elimina del registro. Todo funciona en un portátil, y luego una instalación nueva falla en un servidor limpio.
Un objetivo realista no es “seguridad perfecta”. Es:
- menos dependencias que realmente uses
- versiones fijadas con lockfiles
- instalaciones repetibles entre máquinas y en CI
- una vía pequeña y controlada para aceptar actualizaciones
Equipos como FixMyMess suelen ver prototipos generados por IA donde esta es la razón principal por la que “ayer funcionaba” se convierte en “hoy no despliega”.
Qué recopilar antes de tocar nada
Antes de empezar la limpieza de dependencias y cadena de suministro, recoge unos elementos básicos para no “arreglar” y acabar con un build roto. El objetivo es simple: poder reproducir el comportamiento actual, medir cambios y revertir rápido si algo te sorprende.
Primero, consigue acceso completo al código y a dónde se ejecuta. Eso incluye el repo (ramas y tags), el lockfile (package-lock.json, pnpm-lock.yaml, yarn.lock, poetry.lock, Pipfile.lock o similar) y los comandos exactos usados para construir y arrancar la app. Si la app está desplegada, captura también el destino y la configuración del despliegue (proveedor de hosting, variables de entorno y cualquier paso de build que la plataforma ejecute por ti).
Decide también qué vas a limpiar. Las dependencias de runtime son las que se envían a usuarios y servidores. Las herramientas de desarrollo son para trabajo local (linters, runners de tests, TypeScript). Las herramientas sólo de CI viven sólo en la pipeline. Mezclarlas es una causa común de que “funcionaba en local” termine en “falla en producción”.
Aquí está el conjunto mínimo de entradas que ahorra horas más tarde:
- El commit de trabajo actual o la versión exacta desplegada
- El lockfile y la versión del gestor de paquetes
- Un comando “golden” de build y uno de start
- Una copia de las variables de entorno actuales (manejando secretos de forma segura)
- Notas sobre dónde se ejecuta la app (versión de Node, versión de Python, SO)
Elige una línea base en la que confíes: el despliegue en producción actual, o el último build conocido bueno desde CI. Si no tienes uno, créalo ahora compilando desde cero en una máquina limpia.
Finalmente, define un plan de rollback antes de cambiar paquetes. Taggea la línea base, mantén un diff limpio y escribe cómo revertirás. Si heredaste un prototipo generado por IA con cambios desconocidos, equipos como FixMyMess suelen comenzar con una auditoría rápida para saber qué puede actualizarse con seguridad y qué requiere pruebas cuidadosas.
Mapea tu árbol de dependencias sin adivinar
Antes de borrar nada, obtén una imagen clara de lo que tu app realmente instala y usa. La limpieza de dependencias y de la cadena de suministro sale mal cuando la gente confía en la memoria, copia-pegando desde una plantilla o asume que un paquete no se usa porque no lo ve en el código.
Empieza identificando qué gestores de paquetes están en juego y si existen lockfiles. Un repo puede ocultar varios ecosistemas: una app web con npm más una API en Python con pip, o un monorepo con workspaces de pnpm. Los lockfiles importan porque te dicen las versiones exactas que tu despliegue descargará, no las versiones que quisieras que descargara.
Luego separa dependencias directas (las que elegiste) de las transitivas (traídas por otros paquetes). Las transitivas son a menudo donde viven riesgo y bloat, pero normalmente no debes editarlas directamente. En su lugar, cambia la dependencia directa que las trae o aplica una anulación soportada por tu herramienta.
Mientras mapeas, marca las áreas de alto riesgo donde un único paquete vulnerable o desactualizado puede convertirse en un incidente real: librerías de autenticación, utilidades criptográficas, manejo de subidas y procesamiento de imágenes, y drivers de base de datos. Estas áreas también son las más propensas a romperse si las versiones se desvían.
Una forma rápida de capturar la imagen completa es registrar:
- Gestores de paquetes y lockfiles presentes (y si están committeados)
- Principales dependencias directas por propósito (auth, DB, subidas, UI)
- Las mayores cadenas transitivas (qué trae a qué)
- De dónde vienen los paquetes: registro público, URLs git o rutas locales
- Cualquier script postinstall o pasos de build que traigan código extra
Ejemplo: un prototipo generado por IA apresurado podría instalar tres paquetes de auth, más un fork desde git para uno de ellos. Ese fork puede eludir las alertas normales de CVE, así que querrás marcarlo temprano antes de tocar cualquier otra cosa.
Eliminar dependencias no usadas con seguridad
Las dependencias no usadas no son inofensivas. Cada dependencia extra es más código que no controlas, más actualizaciones que seguir y más posibilidades de una rotura sorpresa. Si haces limpieza de dependencias y cadena de suministro, empieza por eliminar lo que no necesitas antes de parchear y fijar versiones.
Comienza con una comprobación de dependencias no usadas y luego confirma cada resultado con una búsqueda rápida en el código. Las herramientas ayudan, pero no entienden tus rutas de runtime. Un paquete puede parecer no usado y aun así ser requerido por un script, un archivo de config o un paso de despliegue.
Cuidado con los falsos positivos habituales
Antes de borrar nada, valida los avisos de “no usado” frente a casos que los escáneres suelen pasar por alto: importaciones dinámicas (por ejemplo, cargar un módulo por nombre), puntos de entrada CLI (paquetes usados vía un comando), tooling de build referenciado solo en config y código que solo se ejecuta en producción (o solo en tests). También revisa scripts de paquete como postinstall, build y migrate, ya que pueden invocar herramientas que no se importan en ningún lado.
Cuando elimines paquetes, hazlo en pequeños lotes, no todo de una vez. Así, cuando algo falle sabrás qué lo causó.
Un ritmo simple que funciona bien:
- Elimina 1–3 paquetes relacionados (por ejemplo, librerías UI antiguas o plugins de lint no usados)
- Regenera lockfiles y luego instala desde cero
- Ejecuta tests, build y arranca la app localmente
- Prueba un flujo real de usuario (login, checkout, subida, etc.)
- Haz commit con un mensaje claro para revertir rápido
Si decides mantener una dependencia que parece no usarse, escribe por qué. Una nota de una línea en el README o un comentario cerca de la config es suficiente. “Mantenida porque el build de despliegue la llama” ahorra horas al siguiente que trabaje el repo.
Ejemplo: un prototipo generado por IA puede incluir tres librerías de fechas, dos clientes HTTP y un SDK de auth sin usar. Eliminar los extras por grupos a menudo reduce el tamaño de la instalación y el riesgo futuro sin cambiar el comportamiento del producto.
Encontrar y parchear CVE conocidos con el mínimo impacto
Empieza ejecutando un escaneo de vulnerabilidades y guarda la salida cruda en un lugar que puedas compartir. Quieres tres detalles por cada hallazgo: severidad, la ruta de dependencia (qué paquete lo introduce) y la primera versión segura. Sin la ruta, la gente suele actualizar lo equivocado y la alerta vuelve.
Si tu objetivo es la limpieza de dependencias y cadena de suministro, prioriza según la exposición real, no por miedo. Arregla primero lo alcanzable en producción (rutas servidor, auth, manejo de archivos, webhooks de pago). Luego maneja herramientas de dev de alto riesgo que pueden afectar builds o pasos de publicación. Problemas de baja severidad en paquetes sólo de test pueden esperar hasta que la app esté estable.
Parchea con el cambio compatible más pequeño. Prefiere actualizar una dependencia directa que traiga el paquete vulnerable, en vez de subir una docena de librerías no relacionadas. Si la solución requiere un salto de versión mayor, párate y pregunta: ¿se usa realmente esta librería? ¿hay una alternativa más segura? A veces la solución más limpia es eliminarla.
Después de las actualizaciones, vuelve a probar los flujos que atacantes apuntarían y los que sienten los usuarios.
- Registro, login, logout, restablecer contraseña
- Pagos o checkout (incluidos webhooks)
- Subidas y descargas de archivos
- Páginas de administración y comprobaciones de roles
- Cualquier formulario público que escriba en la base de datos
Mantén notas sobre lo que cambió, lo que queda y por qué. Ese rastro ayuda cuando un escaneo vuelve a marcar el mismo CVE la semana siguiente bajo otra ruta de dependencias.
Un ejemplo práctico: un prototipo generado por IA puede incluir un helper de auth antiguo más dos librerías de cookies distintas. El escaneo marca un issue crítico profundo en una dependencia transitiva. La solución menos arriesgada suele ser actualizar el helper de auth de primer nivel a una versión menor parcheada y borrar el paquete duplicado de cookies, luego confirmar que login y acceso de admin siguen funcionando.
Si heredas una base de código desordenada generada por IA, FixMyMess suele empezar con una auditoría rápida y después aplica el menor conjunto de actualizaciones seguras con verificación humana para que los fixes de seguridad no se conviertan en nuevos bugs.
Fijar versiones y controlar actualizaciones de ahora en adelante
Los prototipos rápidos fallan cuando las instalaciones no son repetibles. Una persona ejecuta npm install el lunes, otra el viernes, y obtienen versiones diferentes. Los lockfiles solucionan eso registrando las versiones exactas que funcionaron, de modo que cada instalación coincida con lo que probaste.
Trata el lockfile como un artefacto de primera clase: commítalo, revisa sus cambios y evita borrarlo “para arreglar cosas”. Si el lockfile cambia inesperadamente, es una señal de que estás trayendo código nuevo de Internet, aunque tu propio código no haya cambiado.
Donde la estabilidad importa más, fija versiones a propósito. Por ejemplo, mantén versiones exactas para auth, pagos, clientes de base de datos y herramientas de build. Para tooling menos crítico (linters, formatters), permitir actualizaciones menores puede estar bien si tienes checks rápidos.
Una política simple que previene sorpresas:
- Commita lockfiles y falla el CI si no están sincronizados.
- Fija paquetes críticos; permite rangos solo para herramientas de bajo riesgo.
- Agrupa actualizaciones (semanal o quincenal), no un goteo constante de pequeños bumps.
- Requiere una breve revisión más un smoke test antes de mergear actualizaciones.
- Mantén un plan de rollback (lockfile previo + tag) para recuperación rápida.
Los bots de actualización automatizada ayudan, pero solo si controlas el flujo. Define reglas para que las actualizaciones lleguen en PRs agrupados, ejecuten una suite mínima de tests y se desplieguen primero a staging. Incluso un smoke test de 5 minutos (login, una escritura a BD, carga de una página clave) detecta la mayoría de roturas.
Las dependencias privadas o forked necesitan propiedad. Mantenlas en un solo lugar, documenta quién las mantiene y sigue cambios con tags de versión claros. Si heredaste un prototipo generado por IA (algo que FixMyMess ve mucho), abundan los forks: nombrarlos claramente y fijarlos evita “actualizaciones misteriosas” después.
Este es el núcleo de la limpieza de dependencias y cadena de suministro: instalaciones repetibles hoy, cambios controlados mañana.
Un flujo práctico que puedes seguir paso a paso
Si quieres que la limpieza vaya bien, trátala como una pequeña migración, no como una limpieza rápida. El objetivo es simple: saber de qué dependes, cambiar una cosa a la vez y mantener siempre un build funcional que puedas enviar.
Empieza escribiendo qué no debe romperse. Para la mayoría de prototipos eso es login, pagos, subidas de archivos, jobs en background y cualquier cosa que toque datos de producción. Ejecuta la app y recorre esos caminos para detectar roturas rápido.
Aquí tienes un flujo que funciona bien en codebases apresurados:
- Inventario de lo que tienes. Exporta la lista de dependencias directas y las entradas del lockfile. Marca qué funcionalidades dependen de ellas (por ejemplo,
"auth","emails","database"). - Eliminar paquetes no usados en pequeños lotes. Borra 1–3 dependencias, reconstruye y ejecuta un smoke test rápido. Si algo falla, revierte ese lote y prueba con cortes más pequeños.
- Parchear vulnerabilidades por severidad. Arregla CVE de alta severidad primero, luego medias y bajas. Prefiere el menor aumento de versión seguro y vuelve a probar tus caminos críticos tras cada cambio.
- Hacer que los lockfiles sean obligatorios. Asegura que tanto la instalación local como la CI usen el lockfile y fallen si está ausente o desincronizado.
- Añadir una checklist de release mínima y rollback. Antes de desplegar: instala desde cero, build, ejecuta tests básicos y confirma que no se empaquetan secretos. Mantén un plan de rollback (último build bueno o tag) para recuperarte rápido.
Si es un prototipo generado por IA, espera sorpresas ocultas como librerías duplicadas, SDKs no usados o paquetes añadidos para una funcionalidad que nunca se lanzó. Equipos como FixMyMess suelen comenzar con una auditoría rápida para identificar qué cambios pueden agruparse con seguridad y cuáles necesitan verificación manual y cuidadosa.
Errores comunes que crean outages o nuevos bugs
La mayoría de las roturas en prototipos durante la limpieza de dependencias y cadena de suministro ocurren por razones previsibles: se hacen cambios más rápido de lo que la app puede comprobarse de extremo a extremo. El objetivo no es evitar actualizaciones, sino actualizarlas con pruebas.
Una trampa común es ejecutar un comando de auto-fix que actualiza silenciosamente versiones mayores. Parece progreso, pero los saltos mayores a menudo cambian defaults, eliminan opciones o alteran el output del build. Solo lo notas después del deploy, cuando los redirects de auth dejan de funcionar o las rutas servidor devuelven 404.
Otra causa frecuente es borrar paquetes que parecen no usarse sin comprobar cómo arranca la app en cada entorno. Muchos prototipos generados por IA cambian comportamiento según flags de entorno (producción vs preview) o importaciones dinámicas. Un paquete puede parecer no usado en local pero ser requerido en un paso de build de producción.
Aquí errores que suelen causar outages o nuevos bugs:
- Aplicar actualizaciones masivas “fix all” que incluyen saltos de versión mayor sin testear flujos clave.
- Eliminar dependencias sin revisar puntos de entrada en runtime, scripts de build y rutas específicas por entorno.
- Ignorar dependencias transitivas (las deps que tus deps traen) que pueden introducir paquetes riesgosos aunque tu lista directa parezca limpia.
- Actualizar paquetes y mandar accidentalmente secretos expuestos o configuraciones permisivas (por ejemplo, modo debug activado, CORS abierto o un .env de ejemplo incluido).
- Suponer que herramientas sólo de dev no afectan producción: bundlers, linters y plugins de build pueden cambiar el output, tree-shaking o la inyección de variables de entorno.
Un ejemplo simple: un prototipo apresurado usa un plugin de build sólo en modo “production”. Lo borras porque la app corre en local, pero el build de producción ahora falla y el despliegue queda atascado.
Si heredas una base generada por IA, aquí es donde las pequeñas sorpresas se acumulan rápido. FixMyMess suele empezar con una auditoría para encontrar dependencias ocultas de build, riesgos transitivos y filtraciones de secretos antes de que cualquier cambio llegue a producción.
Lista rápida antes de desplegar
Justo antes de enviar, haz un pequeño pase de limpieza de dependencias y cadena de suministro. El objetivo no es la perfección. Es hacer el build repetible, reducir roturas sorpresa y saber qué riesgos aceptas.
Comprobaciones pre-despliegue (15–30 minutos)
- Haz una instalación limpia desde cero usando solo el lockfile (carpeta nueva o contenedor fresco). Si falla, arregla eso primero.
- Analiza tu manifiesto en busca de deps directas que ya no usas, elimínalas y vuelve a ejecutar tests. Mantén cambios pequeños para detectar qué rompió.
- Revisa alertas de seguridad y arregla las de alta severidad que puedas parchear sin grandes refactors. Si no puedes arreglar una hoy, escribe por qué la aceptas y cuándo la revisarás.
- Ejecuta un smoke test rápido en los caminos más importantes: signup/login, una acción principal “happy path” y cualquier flujo de pago o exportación de datos.
- Despliega con un plan de rollback claro (quién lo hace, cuánto tarda y qué significa “malo”).
Si trabajas con npm y pip, haz lo mismo en cada ecosistema: instalación limpia, eliminar extras, parchear lo posible y confirmar que la app se comporta igual.
Preparación para rollback
Un rollback es tu red de seguridad cuando una actualización de dependencia rompe producción.
- Mantén disponible el último artefacto de build conocido bueno o el release tag.
- Asegura que la config y los secretos sean compatibles con la versión previa.
- Verifica que los cambios en la base de datos sean reversibles (o aplázalos hasta después del deploy).
- Confirma que tu monitorización mostrará errores rápido (logs básicos y un health check).
Si es un prototipo generado por IA, este paso suele descubrir riesgos ocultos como librerías de auth no usadas o paquetes desactualizados. Equipos como FixMyMess normalmente empiezan aquí antes de reparaciones más profundas, porque evita repetir outages mientras arreglas problemas mayores.
Ejemplo: limpiar un prototipo generado por IA y hecho rápido
Un fundador lanza una demo construida con una herramienta de IA. Tras varias iteraciones de prompts, el repo ahora tiene una lista enorme de paquetes: un kit UI de React, tres librerías de fechas, dos SDKs de auth, helpers de servidor sin usar y una carpeta de scripts Python con paquetes de ML que nunca se ejecutan. Las instalaciones son lentas, las warnings ocupan páginas y nadie sabe qué dependencia es realmente necesaria.
Aquí tienes una secuencia de limpieza que mantiene bajo el riesgo mientras reduces el desorden.
Primero, haz inventario. Captura el estado exacto de la instalación (lockfiles incluidos), registra versiones de runtime (Node, Python) y ejecuta la app una vez para confirmar el comportamiento actual. Luego mapea lo que realmente se usa: busca imports, revisa el output del build y compáralo con lo listado en los manifiestos.
Después, elimina peso muerto en pequeños lotes. En lugar de borrar la mitad de dependencias, elige duplicados obvios (como dos clientes HTTP), quita uno, reinstala y corre un smoke test básico. Repite hasta que la lista de dependencias coincida con lo que la app realmente utiliza.
Luego parchea vulnerabilidades con el menor impacto:
- Ejecuta la auditoría de paquetes y exporta resultados
- Parchea dependencias directas primero y luego reevalúa las transitivas
- Para upgrades riesgosos, prueba sólo las áreas que toca la dependencia (auth, subidas, pagos)
- Si debes posponer un parche, escribe por qué y pon una fecha recordatoria
Un fallo realista al estilo “left-pad”: el build de repente falla porque un paquete transitivo pequeño se retira o se re-publica con un cambio rompedor. Si dependes de versiones flotantes, tu próxima instalación puede traer un árbol distinto aunque tu código no cambiara. Fijar versiones con lockfiles reduce ese impacto porque las instalaciones permanecen consistentes entre máquinas y días.
El estado final es fácil de percibir: instalaciones más rápidas, menos warnings y una lista de dependencias más corta que puedes explicar. Para equipos que heredaron un prototipo generado por IA, FixMyMess suele empezar con esta limpieza exacta para que la base sea estable antes de trabajo más profundo como arreglar auth o endurecer seguridad.
Próximos pasos para mantener tu prototipo estable
El trabajo de dependencias sólo se mantiene si alguien lo posee. Elige un responsable para la limpieza de dependencias y cadena de suministro: el fundador en apps pequeñas, la agencia si aún hacen cambios, o un mantenedor nombrado si la app avanza hacia producción. “Todos” suele significar “nadie”, y así los paquetes viejos y las actualizaciones transitivas riesgosas vuelven a colarse.
Establece un ritmo simple que puedas mantener. Semanalmente, haz un escaneo rápido para detectar avisos urgentes y actualizaciones sorpresa. Mensualmente, haz una revisión más profunda donde decidas qué actualizar, qué fijar y qué eliminar. Si esperas hasta “después del lanzamiento”, lo harás durante un outage.
Una cadencia práctica que funciona para muchos equipos:
- Semanal (15 minutos): ejecuta la auditoría de seguridad y verifica cambios de versiones inesperados
- Mensual (60–90 minutos): actualiza un pequeño lote de paquetes, vuelve a correr tests y refresca lockfiles
- Trimestral: revisa paquetes de alto riesgo (auth, crypto, uploads, drivers de BD) y reemplaza si hace falta
Si tu base fue generada rápido (especialmente con herramientas de IA), la inestabilidad suele venir de una mezcla de dependencias frágiles, snippets copiados y scripts de auth o despliegue medio configurados. En ese caso, no “actualices todo”. Haz una auditoría focalizada primero y repara los caminos críticos (login, pagos, acceso a BD, pipeline de build) para que las actualizaciones dejen de romper la app.
Una buena señal de que necesitas ayuda externa: parcheas un CVE y se rompen tres cosas más, o no puedes explicar por qué un paquete está instalado.
Si estás en ese punto, FixMyMess puede ejecutar una auditoría de código gratuita y luego remediar problemas rápido (la mayoría de proyectos toman 48–72 horas), incluyendo limpieza de dependencias, endurecimiento de seguridad y dejar el prototipo listo para producción.
Antes de cada release, mantén una regla corta: si no puedes reconstruir desde cero en una máquina limpia usando tus lockfiles, estás a una mala actualización de tiempo de inactividad.