Manejo de errores en Next.js con reintento para que el usuario pueda recuperarse
Aprende a crear error boundaries en Next.js con reintento que muestran un mensaje claro, capturan contexto para soporte y ayudan a los usuarios a recuperarse en lugar de ver una pantalla en blanco.
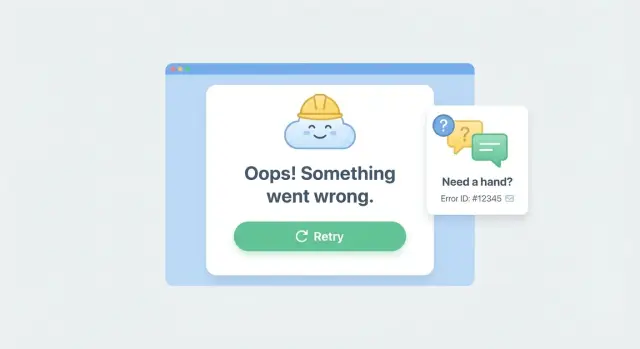
Por qué las pantallas en blanco hacen que los usuarios se vayan (y pierdan confianza)
Cuando una app se bloquea y muestra una pantalla en blanco, la mayoría de la gente asume que hizo algo mal. Pulsan atrás, recargan o cierran la pestaña, y normalmente no vuelven.
El daño real no es el error en sí. Es la incertidumbre: "¿Se guardó mi trabajo?", "¿Se rompió mi cuenta?", "¿Es seguro usar esto?" Un fallo silencioso enseña a los usuarios a dejar de confiar en cada botón.
Las pantallas en blanco también ocultan lo que más importa en ese momento: el siguiente paso. Si el checkout falla, el usuario necesita una forma de intentarlo de nuevo. Si una entrega de formulario falla, necesita saber si se envió y cómo evitar volver a escribir todo.
La recuperación importa más que la perfección del texto porque la gente intenta terminar una tarea, no leer una explicación. Una buena experiencia de error mantiene la app usable cuando es posible. Cuando no lo es, guía al usuario hacia la siguiente mejor acción.
Un objetivo práctico para la UI de fallback:
- Decir al usuario qué pasó en lenguaje claro
- Ofrecer una acción clara (Reintentar, Recargar, Volver)
- Proteger su trabajo (mantener el estado del formulario si puedes)
- Proveer una forma de obtener ayuda (con un código de referencia)
Por eso los error boundaries con una acción Reintentar son tan efectivos: convierten un callejón sin salida en un desvío. Incluso un botón básico de “Intentar de nuevo” puede salvar una sesión cuando el crash fue por un problema temporal de red o una API inestable.
A veces mostrar una pantalla de error útil es mejor que esconder fallos. Si tu app se rompe en producción, fingir que está bien solo hace perder tiempo a los usuarios. Una pantalla de recuperación clara convierte reportes vagos como “dejó de funcionar” en algo accionable.
Qué hacen realmente los error boundaries de React y Next.js
Un error boundary es una red de seguridad para tu UI. Cuando un componente falla al renderizar (o en un método de ciclo de vida), el boundary puede atrapar ese fallo y mostrar una pantalla de fallback en lugar de tumbar toda la página.
En términos sencillos, captura problemas que ocurren mientras React intenta dibujar la pantalla. No atrapa errores en manejadores de eventos (como un click), errores en código asíncrono que corre después (como una promesa fetch), ni problemas fuera de React (como una extensión del navegador que rompe cosas). Esos requieren su propio manejo.
En Next.js, también ayuda a separar fallos del cliente y del servidor.
Errores del cliente son fallos en código que se ejecuta en el navegador del usuario (un componente roto, estado inválido, forma de datos inesperada). Errores del servidor ocurren mientras Next.js construye la página en el servidor (una consulta a la base de datos falla, una API se agota, auth lanza).
Una buena UI de fallback debe ayudar a una persona real a dar el siguiente paso:
- Decir qué pasó con palabras simples (sin stack traces)
- Ofrecer una acción como Reintentar o Recargar
- Mantener el resto de la página usable cuando sea posible
- Proveer un pequeño código de soporte para que alguien pueda ayudar
La mayor ganancia es reducir el radio de daño. En vez de que un widget malo rompa el checkout, solo ese widget falla mientras el carrito, la navegación y los inputs siguen vivos.
El patrón orientado a la recuperación: mensaje + acción + contexto
Un buen error boundary no es solo un capturador de crashes. Es una pantalla de recuperación que ayuda a alguien a terminar lo que vino a hacer. El objetivo es reducir el pánico, ofrecer un siguiente paso seguro y capturar suficiente detalle para arreglar la causa raíz.
Un fallback orientado a la recuperación tiene tres ingredientes: un mensaje claro, una acción segura que el usuario pueda tomar ahora mismo y un pequeño contexto que pueda compartir con soporte (por ejemplo, un ID de referencia).
Empieza por la acción, no por la disculpa. Si una sección de la página falla, permite al usuario reintentar solo esa sección. Si toda la ruta falló, ofrece Recargar página o Volver. Mantén las acciones de bajo riesgo: no deberían borrar datos ni repetir una compra por accidente.
Para el mensaje, di lo que el usuario necesita saber, no lo que sabe el código. Evita stack traces, nombres de componentes o "TypeError: undefined is not a function". Un mensaje mejor es: "No pudimos cargar tus proyectos. Tus cambios están guardados. Intenta de nuevo."
Luego añade contexto que convierta un reporte vago en algo depurable. Muestra un ID de referencia corto como ERR-7F3A2C y una marca temporal. Si registras ese mismo ID, soporte puede encontrar el error correspondiente rápido.
Planifica tus boundaries antes de escribir código
Los error boundaries funcionan mejor cuando los tratas como parte del diseño del producto, no como un parche de última hora. Antes de añadir componentes, decide qué significa "recuperación" para cada parte de la app.
Empieza mapeando dónde deben contenerse los fallos. Un boundary a nivel de página es útil cuando toda la ruta depende de una petición o un layout crítico. Boundaries más pequeños a nivel de componente funcionan mejor cuando puedes mantener el resto de la página usable (por ejemplo, la barra lateral carga pero el feed de actividad falla).
Una regla rápida de colocación:
- Pon un boundary a nivel de página o ruta para flujos críticos como checkout, inicio de sesión o guardar ajustes.
- Pon un boundary alrededor de widgets opcionales como recomendaciones, gráficas o comentarios.
- Añade un boundary alrededor de integraciones riesgosas como SDKs de terceros, editores embebidos y subidas de archivos.
- Evita envolver cada componente pequeño. Hace que los errores sean más difíciles de entender.
Después, define qué hace realmente Retry. Retry debe ser predecible: volver a renderizar el segmento, reobtener datos o resetear una porción específica del estado. Si Retry solo reproduce el mismo estado roto, los usuarios spammerán el botón y se quedarán atascados.
Haz el comportamiento explícito con una regla simple: "Retry reinicia X y reobtiene Y." Por ejemplo, si "Guardar perfil" falla, retry debería volver a ejecutar la petición de guardado y reactivar el formulario, no borrar lo que el usuario escribió.
Finalmente, decide qué contexto vas a capturar para soporte y qué nunca mostrarás. El contexto útil puede ser tan simple como nombre de ruta/pantalla, qué hizo el usuario, marca temporal y entorno (prod vs staging), y un código de error corto. Mantén líneas rojas estrictas: nunca incluyas secretos, tokens, cuerpos completos de petición o datos personales en la UI.
Paso a paso: añade error boundaries con Reintentar en Next.js
Un buen error boundary hace dos cosas: le dice al usuario qué pasó en palabras claras y le da un siguiente paso evidente (Reintentar o volver). Aquí tienes dos formas prácticas de añadir eso.
App Router: error.tsx + reset()
En App Router, añade un archivo error.tsx dentro del segmento de ruta que quieras proteger. Next.js lo renderizará cuando algo en ese segmento lance.
'use client'
export default function Error({
error,
reset,
}: {
error: Error & { digest?: string }
reset: () => void
}) {
return (
<div style={{ padding: 16 }}>
<h2>Something went wrong</h2>
<p>Try again. If it keeps happening, you can go back to a stable page.</p>
<div style={{ display: 'flex', gap: 8, marginTop: 12 }}>
<button onClick={() => reset()}>Retry</button>
<button onClick={() => (window.location.href = '/')}>Go to Home</button>
</div>
<p style={{ marginTop: 12, fontSize: 12, opacity: 0.8 }}>
Error code: {error.digest ?? 'unknown'}
</p>
</div>
)
}
Usa etiquetas amigables para el usuario. "Reintentar" es más claro que "Reset boundary", y "Ir al inicio" es más seguro que dejar a alguien atascado.
Pages Router: componente reutilizable ErrorBoundary
Si usas Pages Router (o quieres un wrapper que puedas colocar alrededor de un widget específico), usa un componente de clase de React.
import React from 'react'
type Props = { children: React.ReactNode; fallback?: React.ReactNode }
type State = { hasError: boolean }
export class ErrorBoundary extends React.Component<Props, State> {
state: State = { hasError: false }
static getDerivedStateFromError() {
return { hasError: true }
}
retry = () => this.setState({ hasError: false })
render() {
if (this.state.hasError) {
return (
this.props.fallback ?? (
<div style={{ padding: 16 }}>
<h2>We hit a problem</h2>
<p>You can retry, or go back to a stable page.</p>
<button onClick={this.retry}>Retry</button>{' '}
<button onClick={() => (window.location.href = '/')}>Go to Home</button>
</div>
)
)
}
return this.props.children
}
}
Coloca este boundary alrededor del área de mayor riesgo (un formulario complejo, un widget de pago, o un panel con muchos datos) para que el resto de la página siga usable.
Añade contexto de soporte sin exponer datos sensibles
Cuando algo falla, los usuarios no quieren un misterio. Dales una referencia simple que puedan compartir y captura suficiente contexto para reproducir el problema.
Empieza generando un ID de error (una cadena corta aleatoria o un UUID). Muéstralo en la UI de fallback como "Error ID: ABC123" y facilita copiarlo. Si el usuario pulsa Reintentar, conserva el mismo ID para poder conectar el primer fallo con el intento de reintento en tus logs.
Captura contexto ligero que responda: ¿dónde estaban?, ¿qué intentaban hacer?, y ¿cuándo pasó? Normalmente solo necesitas unos pocos campos:
- Ruta o página (por ejemplo, /settings/billing)
- Área funcional (Facturación, Checkout, Editor)
- Última acción del usuario (Pulsó "Guardar", Envió formulario)
- Marca temporal y zona horaria
- Versión/build de la app
Envía o guarda el error detallado de forma segura. Una buena regla: si no lo pegarías en un chat público, no lo recolectes automáticamente. Evita secretos (claves API, tokens), cuerpos completos de petición, contraseñas, detalles de pago y cookies crudas. Si registras server-side, prefiere redacción y listas blancas (registra solo los campos que esperas).
Si añades una opción "Reportar esto" o "Contactar soporte" en la UI de error, rellena previamente el ID de error y el contexto básico para que el usuario no tenga que explicarlo todo.
Diseñar una UI de fallback que los usuarios puedan usar
Una buena pantalla de error debe sentirse como un aterrizaje seguro, no como un callejón sin salida. Evita términos técnicos y no culpes al usuario. "Algo salió mal" está bien. "Token inesperado en JSON" es ruido.
Mantén la estructura de la página familiar para que siga pareciendo tu app. Conserva el header, la navegación y el espacio donde normalmente aparece contenido. Cuando el layout se mantiene, la gente tiene más probabilidades de intentar de nuevo en vez de irse.
Haz que el siguiente paso sea obvio. El botón primario debe ser el centro visual de la pantalla, no un enlace pequeño. Pon la acción principal primero y nómbrala en lenguaje llano.
Un conjunto simple de acciones que cubre la mayoría de casos:
- Reintentar
- Volver
- Recargar página
- Contactar soporte
Añade una frase corta que diga qué pasa si reintentan (por ejemplo, "Intentaremos cargar tus datos de nuevo"). Si hay posibilidad de pérdida de cambios, dilo claro y ofrece una opción más segura como "Copiar detalles" o "Guardar borrador" si la tienes.
La accesibilidad es importante. Cuando aparece el fallback, mueve el foco del teclado al encabezado o al botón primario para que usuarios de lector de pantalla y teclado sepan que algo cambió. Asegura contraste legible, objetivos táctiles grandes y que Enter y Space activen el botón principal.
Finalmente, incluye contexto pequeño y no sensible que ayude a soporte sin asustar a los usuarios: una marca temporal, un código de referencia corto y qué intentaban hacer ("Guardando ajustes").
Errores comunes (y cómo evitarlos)
Los error boundaries están pensados para proteger a los usuarios, no para ocultar problemas. Una pantalla amigable no ayuda si el mismo bug sigue ocurriendo. Solo mueve el dolor de la UI a soporte.
Los errores más habituales suelen ser sencillos.
Errores que empeoran las cosas en silencio
- Atrapar demasiado: Un único boundary para toda la app puede convertir un pequeño "el widget de perfil falló" en un fallo de página completa. Pon boundaries alrededor de las características para que el resto de la página siga funcionando.
- Retry sin salida: Si Retry sigue fallando, los usuarios se sienten atrapados. Después de 1–2 reintentos, ofrece otro camino (volver, recargar o contactar soporte).
- Mostrar texto de error crudo: Stack traces y mensajes de la base de datos asustan y pueden filtrar detalles. Muestra un mensaje simple y guarda la info técnica en logs.
- Sin ID de error: Si soporte no puede emparejar lo que vio el usuario con lo que registraste, el triage es conjetura.
- Fallback único para todo: "Algo salió mal" en todas partes entrena a los usuarios a abandonar la app. Adapta el fallback a la funcionalidad: guardado, carga, auth, pagos.
Cómo evitarlos (reglas simples)
Trata el retry como una herramienta de recuperación, no como un botón de reinicio. Desactiva el botón Retry mientras se está ejecutando y cambia el mensaje si falla otra vez.
Incluye contexto de soporte que ayude a depurar sin exponer secretos: ID de error, hora, nombre de página o funcionalidad y la última acción. Mantén tokens, emails y payloads completos fuera de la UI.
Prueba la ruta de fallo a propósito. Apaga la red, fuerza un 500 y confirma que la UI da un siguiente paso claro y algo rastreable para soporte.
Lista de verificación rápida antes de lanzar
Antes de lanzar boundaries con reintento, haz una pasada enfocada en la recuperación real del usuario. Quieres demostrar dos cosas: el fallback aparece cuando debe, y el usuario tiene una forma clara de volver a lo que hacía.
Provoca un error controlado a propósito (por ejemplo, lanza dentro de un componente que normalmente carga datos). Luego comprueba:
- El fallback se renderiza con un mensaje claro (sin stack traces).
- Retry o bien recupera por completo o falla de nuevo con una UI calmada y consistente.
- Se muestra un ID de error al usuario y aparece en los logs.
- La UI y los logs no incluyen secretos ni datos personales (tokens, emails, consultas completas, headers de petición).
- El flujo funciona en móvil y con conexiones lentas. Los botones deben ser fáciles de pulsar, y Retry no debe spamear peticiones.
Asegúrate de que Retry reinicie cualquier estado de carga atascado, se desactive mientras corre y muestre un estado corto como "Reintentando...". Si Retry no puede funcionar (offline, permisos faltantes), dilo y ofrece una acción segura alternativa.
Un ejemplo realista: "Guardado falló" sin perder al usuario
Un usuario edita su dirección de facturación y pulsa Guardar. La petición choca con un backend inestable, devuelve un 500 y una parte de la UI lanza un error. Sin boundary, la página puede estrellarse en una pantalla en blanco. El usuario queda atrapado, sin saber si sus cambios se guardaron, y probablemente abandone el flujo.
Con una configuración orientada a la recuperación, el error boundary atrapa el crash y muestra un fallback que mantiene al usuario orientado. El formulario permanece en pantalla si es posible (o se re-renderiza con los últimos valores escritos), y el mensaje es claro: "No pudimos guardar tus cambios." Ofrece un siguiente paso obvio: Reintentar. Si Retry falla otra vez, el usuario todavía tiene una salida segura como "Volver al panel" o "Cancelar cambios".
Lo que hace esto usable es el contexto extra que viaja con el error, sin exponer datos sensibles:
- El usuario ve un mensaje corto, un botón Reintentar y una forma clara de salir de la página.
- El usuario ve un ID de error que puede copiar (ejemplo: FM-8K2Q) al contactar soporte.
- Soporte ve el ID de error más contexto básico: ruta, marca temporal, versión de la app, navegador y la última acción.
- Soporte puede reproducir más rápido porque sabe qué petición falló y en qué estado estaba la UI, sin pedirle todo al usuario.
Siguientes pasos: implantarlo con seguridad y pedir ayuda si está hecho un lío
Trata los error boundaries como cualquier otra funcionalidad visible para el usuario: haz despliegues pequeños, observa qué pasa y luego expande.
Empieza con un flujo frágil donde un crash duela más, como checkout, login o Guardar. Añade un boundary, asegúrate de que el fallback explique en palabras llanas qué pasó y confirma que Retry hace realmente algo útil (no solo vuelve a desencadenar el mismo crash).
Antes de poner boundaries por todas partes, decide la propiedad. Alguien debe revisar el copy de error, las acciones (Reintentar, Volver, Contactar soporte) y el contexto de soporte para que siga siendo útil y seguro.
Si lo estás implementando en una base de código generada por herramientas de IA, espera sorpresas: estado enredado, flujos de guardado frágiles, auth rota, secretos expuestos o consultas inseguras que hacen imposible que "Retry" funcione. Si necesitas un diagnóstico rápido y un plan práctico de arreglo, FixMyMess (fixmymess.ai) se centra en convertir prototipos generados por IA en software listo para producción, incluyendo diagnóstico de la base de código, reparación de lógica, endurecimiento de seguridad y preparación para despliegue.
Preguntas Frecuentes
¿Por qué las pantallas en blanco hacen que los usuarios se vayan tan rápido?
Una pantalla en blanco crea incertidumbre. Los usuarios no saben si su trabajo se guardó, si su cuenta está rota o qué hacer a continuación, así que se van.
Un fallback simple que explique lo ocurrido y ofrezca un siguiente paso seguro mantiene a las personas en la tarea en vez de abandonar.
¿Qué problemas captura (y no captura) un error boundary de React?
Un boundary de error captura los fallos que ocurren al renderizar componentes de React y muestra una UI de fallback en lugar de romper toda la página.
No captura errores en manejadores de eventos (como un click), rechazos de promesas asíncronas que ocurren después, ni problemas fuera de React, así que todavía necesitas try/catch normales y manejo de errores en las peticiones.
¿Cuándo debo usar `error.tsx` vs un componente ErrorBoundary reutilizable?
Usa error.tsx en App Router cuando quieras que Next.js renderice automáticamente una UI de recuperación para un segmento de ruta cuando algo lance.
Usa un componente ErrorBoundary reutilizable cuando quieras proteger un widget o una parte específica de una página para que el resto de la UI siga usable.
¿Qué debe decir y hacer una buena UI de fallback?
Un valor práctico por defecto es: un mensaje claro, una acción primaria (por lo general Reintentar) y una salida (Volver o Inicio).
Si puedes, añade tranquilidad sobre el estado como “Tus cambios están guardados” o “Puede que necesites reintentar”, pero dilo solo cuando estés seguro.
¿Qué debe hacer realmente el botón Retry?
Retry debe reiniciar la parte rota de la UI y volver a ejecutar exactamente lo que falló, como reobtener datos o reintentar un guardado.
Si Retry solo vuelve a renderizar el mismo estado malo, los usuarios se quedarán bloqueados, así que haz que Retry cambie algo significativo (resetear una porción de estado, limpiar caché o pedir datos de nuevo).
¿Cómo evito atrapar a los usuarios en un bucle infinito de Retry?
Después de uno o dos reintentos fallidos, cambia la UI de “Intenta de nuevo” a ofrecer una salida como Volver, Recargar página o Contactar soporte.
Esto evita que los usuarios presionen botones sin parar y les da una forma clara de continuar su trabajo en otro lugar estable.
¿Qué contexto de soporte debería mostrar a los usuarios cuando algo falla?
Muestra una referencia corta como un Error ID junto a una marca temporal, y registra el mismo ID en tu lado.
Mantenlo ligero y no sensible para que el usuario pueda copiarlo a un mensaje de soporte sin exponer datos privados.
¿Qué datos nunca deberían aparecer en la pantalla de error?
No muestres stack traces, tokens, cookies, cuerpos completos de petición, datos de pago ni nada que no quieras que se pegue en un chat público.
Una regla segura es mostrar solo un código de error corto y contexto básico como “Guardando ajustes”, mientras los detalles técnicos se quedan en logs protegidos con redacción.
¿Dónde debería colocar boundaries en una app Next.js?
Coloca boundaries alrededor de las áreas de mayor riesgo para que un widget que falle no tumbe el checkout o toda la página.
Usa boundaries a nivel de página o ruta para flujos críticos como inicio de sesión y pagos, y boundaries de componente para paneles opcionales como gráficas, comentarios o embeds de terceros.
¿Cómo puedo probar los error boundaries antes de lanzar?
Forza fallos a propósito: lanza una excepción dentro de un componente, simula una respuesta 500 o prueba en modo offline para ver qué experimenta el usuario.
Confirma que el fallback aparece, que Retry no spamea peticiones y que el ID de error coincide con lo que registras, sin filtrar secretos.