Migrar de un blob JSON a tablas normalizadas con backfills
Aprende a migrar de una columna JSON a tablas normalizadas con un plan por fases: nuevo esquema, backfills, escrituras duales, cutover seguro y opciones de rollback.
Por qué las columnas tipo JSON-blob dejan de funcionar cuando creces
Una columna JSON-blob es un solo campo de la base de datos que contiene un objeto entero como texto, por ejemplo {"status": "paid", "coupon": "NEW10", "notes": "..."}. Los equipos empiezan con esto porque parece rápido. Puedes añadir campos sin cambiar el esquema, y muchos generadores de código basados en IA lo usan por defecto cuando intentan avanzar rápido.
El problema aparece cuando la app tiene usuarios reales, volumen real de datos y preguntas reales que la base de datos debe responder. Lo que antes era una sola escritura fácil se convierte en lecturas lentas, informes desordenados y muchos casos especiales en el código.
Normalmente notarás el colapso del JSON-blob de formas previsibles:
- Las consultas se vuelven más lentas porque filtrar y ordenar dentro de JSON es más difícil de optimizar.
- Los campos derivan a formas inconsistentes (a veces
phone, a vecesphoneNumber, a veces falta). - Los informes se convierten en conjeturas porque no puedes fiarte de tipos, campos obligatorios o relaciones.
- Las correcciones de datos se vuelven arriesgadas porque editas grandes blobs en lugar de actualizar una columna clara.
- Los bugs se esconden durante meses porque los datos malos aún “encajan” dentro del JSON.
Los blobs JSON también ocultan problemas de calidad de datos hasta que son caros de arreglar. Un valor que debería ser numérico puede convertirse silenciosamente en una cadena. Un campo que debería ser obligatorio puede desaparecer. Más tarde, cuando necesites totales exactos, deduplicación o registros para cumplimiento, descubrirás que nunca aplicaste esas reglas.
“Tablas normalizadas” significa dividir ese blob en tablas y columnas separadas que representen cada cosa por separado, con tipos claros y relaciones. En lugar de un order.data blob, podrías tener orders, order_items, payments y addresses, con columnas que puedas indexar y validar.
Hay casos en los que deberías esperar. No migres todavía si el producto cambia a diario, el volumen de datos es minúsculo o no tienes una definición clara de lo que significan los campos. Decide primero qué debe permanecer estable.
Si heredaste una app creada por IA donde “todo está en JSON”, este patrón es común: funciona en demos y luego se desmorona en producción. La buena noticia es que puedes migrar de forma segura por fases con backfills, sin una reescritura total.
Mapea tus datos actuales antes de tocar nada
Antes de pasar de un blob JSON a tablas normalizadas, aclara cómo se utiliza el blob hoy. La mayoría de las migraciones fallidas empiezan con conjeturas sobre qué hay dentro del JSON y qué partes importan.
Apunta los flujos de lectura y escritura principales que tocan el blob, basándote en el comportamiento real: las páginas que cargan las personas, los formularios que envían, las llamadas API que sirves, los jobs que ejecutas y las exportaciones de las que depende tu equipo. En muchas apps, los primeros casos son previsibles: una carga de página para usuarios, una acción de guardado, al menos un job en segundo plano, una vista de administrador/informes que lee muchas filas y una o dos integraciones o webhooks que sólo tocan parte del blob.
Luego abre unas cuantas filas reales de producción y lista los campos que influyen en decisiones. Omite ruido como estado temporal de UI, flags antiguos que nunca se leen o claves aleatorias que aparecieron una vez y no volvieron.
Mientras listes campos, marca cada uno como obligatorio, opcional o desaprobado.
- Obligatorio: la app se rompe o las reglas de negocio fallan sin él.
- Opcional: útil, pero no siempre está presente.
- Desaprobado: se puede eliminar más adelante, después de confirmar que nadie lo lee.
Fíjate en datos duplicados en formas distintas. Un signo común es cuando un campo existe tanto como columna de primer nivel como dentro del JSON, o cuando dos claves JSON representan el mismo concepto (como userId vs customer_id). Estas duplicaciones confunden los backfills y hacen que los bugs sean difíciles de rastrear.
Define el éxito en términos medibles antes de tocar el esquema. Consultas más rápidas en pantallas específicas. Informes que no requieran parsear JSON a medida. Menos errores de datos. Validación más simple. Menos cargas de soporte por problemas de “datos faltantes”. Si no puedes medir la mejora, es difícil saber cuándo la migración realmente ha terminado.
Diseña el esquema normalizado en porciones pequeñas y seguras
No intentes reemplazar toda la columna JSON de una vez. Elige una primera porción que importe claramente: una pantalla que sequeja, un informe lento o un endpoint API que sigue agotándose. Una pequeña victoria obliga a la claridad y mantiene el trabajo acotado.
Empieza por nombrar entidades reales. Si el blob mezcla “perfil de usuario”, “plan de suscripción”, “pagos” y “eventos de auditoría”, no son campos de una sola tabla. Son tablas separadas con relaciones. Una prueba simple: ¿puedes describir cada tabla en una frase sin mencionar “JSON”?
Elige identificadores que no vayan a cambiar. Si ya tienes una clave primaria para la fila padre (como account_id), mantenla y úsala como clave foránea en las nuevas tablas. Para registros hijos, añade IDs estables (payment_id, event_id) en lugar de confiar en posiciones de arrays dentro del JSON. Esto importa durante backfills y replays, porque necesitas una forma fiable de emparejar filas.
Aplica las restricciones que puedas respaldar hoy, no el conjunto perfecto que desearías. Para la primera porción, céntrate en:
NOT NULLen columnas imprescindibles (comouser_id,created_at).- Claves foráneas básicas donde confíes la tabla padre.
- Unicidad donde los duplicados romperían la función (por ejemplo, un plan activo por cuenta).
Si necesitas trazabilidad durante la transición, mantenla explícita y temporal. Una columna raw_json en la nueva tabla puede ayudarte a depurar mapeos, pero debe ser una elección consciente, no un nuevo vertedero.
Planifica los índices según tus consultas reales, no según la teoría. Si la app siempre busca “últimos eventos por cuenta” o “plan actual por usuario”, indexa esos filtros y patrones de ordenación exactos. Una porción pequeña con los índices adecuados supera a un esquema gigantesco que nadie puede consultar rápido.
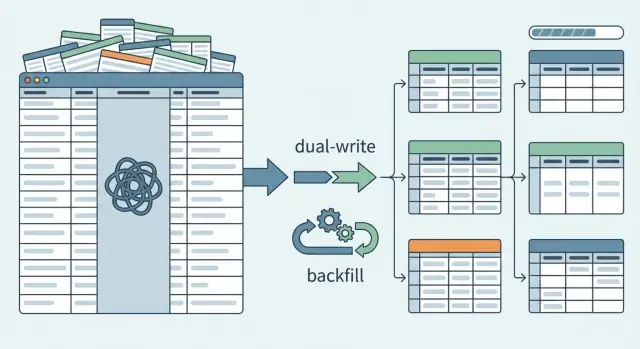
Establece una migración por fases con riesgo mínimo
El camino más seguro es añadir, no reemplazar. Crea primero las nuevas tablas y mantiene la columna JSON existente. La producción permanece estable mientras demuestras que la nueva ruta funciona.
Al principio, mantén el comportamiento antiguo como predeterminado. Las lecturas continúan viniendo del JSON incluso después de que las nuevas tablas existan. En segundo plano, puedes activar la nueva ruta de lectura para un conjunto pequeño de tráfico o unas cuentas internas.
Un feature flag ayuda aquí. Te permite conmutar lecturas entre la fuente antigua (JSON) y la nueva (tablas) sin apostar todo a un despliegue. También te da un rollback instantáneo si algo va mal.
Luego, empieza con escrituras duales. Cuando se crea o actualiza un registro, escríbelo tanto en la columna JSON como en las nuevas tablas normalizadas. Esto permite que los datos nuevos se acumulen en la nueva estructura mientras la app sigue confiando en la antigua.
Las escrituras duales pueden derivar si no pones salvaguardas simples. Un patrón práctico es almacenar una marca updated_at y una pequeña schema_version en ambos lugares. Cuando las versiones difieren, sabes que la fila está desactualizada y necesita atención antes de confiar en ella.
Una configuración mínima por fases que aguanta en producción suele ser:
- Añadir nuevas tablas e índices, pero no eliminar la columna JSON.
- Añadir un feature flag de lectura, con JSON como fuente por defecto.
- Implementar escrituras duales para creaciones y actualizaciones.
- Guardar
updated_aty unaschema_versionsimple para comparaciones. - Registrar desajustes y mantener un interruptor de rollback rápido.
Backfills: mover datos JSON existentes a las nuevas tablas
Un backfill es donde conviertes JSON desordenado en filas limpias. Trátalo como una canalización de datos real, no como un script puntual. Debes poder pararlo, reiniciarlo y ejecutarlo de nuevo sin duplicar datos ni corromper las tablas destino.
Haz el job idempotente y reiniciable. Un patrón común es: parsear JSON, mapear a nuevas columnas y luego upsertar en las tablas destino usando una clave natural estable (como user_id + nombre de campo) o un ID determinista generado. Guarda un checkpoint para saber siempre qué se procesó.
Para mantener el riesgo bajo, backfill por lotes pequeños y sigue el progreso. Rangos de ID funcionan bien cuando los IDs son densos. Ventanas de tiempo funcionan bien cuando tus datos son naturalmente basados en eventos. Una cola de claves primarias es más segura cuando los IDs son escasos. Muchos equipos también hacen pasadas de “cambiado desde la última ejecución” al final para atrapar lo que se movió durante el backfill.
La validación importa más que la velocidad. El JSON suele ocultar tipos malos y campos faltantes, así que sé explícito sobre reglas de parseo: valores por defecto, conversiones de tipo y qué significa “vacío”. Si ves "age": "", ¿guardas NULL, guardas 0 o lo rechazas? Decide la regla y mantenla consistente.
Asume que parte del JSON está roto y diseña para ello. No hagas que falle todo el job. Cuarentena y registra las fallas para que las arregles deliberadamente:
- Registra el ID de la fila fuente y la ruta JSON que falló.
- Guarda el fragmento JSON crudo que causó el error.
- Etiqueta la razón (JSON inválido, campo requerido faltante, incompatibilidad de tipo).
- Sigue procesando la siguiente fila.
Aquí es donde las migraciones suelen fallar en apps creadas por IA: casos límite a medias parseados, truncamientos silenciosos y conversiones “mejor intento” que parecen bien hasta que el reporting o la facturación dependen de ellos. Un registro estricto de lo que no pudo migrarse y por qué convierte sorpresas en una lista de tareas corta y accionable.
Verifica la corrección con comparaciones y guardarraíles
Lo más aterrador no es mover datos. Es confiar en el resultado. Necesitas comprobaciones simples que te digan, en términos claros, si las nuevas tablas coinciden con lo que la app solía leer del JSON.
Empieza con comparaciones que calculen el mismo valor de dos formas: (1) parsear la columna JSON como lo hacía el código antiguo y (2) leer desde las nuevas tablas. Haz esto primero para comportamientos visibles por el usuario: permisos, precios, límites de plan, flags de estado. Luego expande a campos más profundos.
Despliega con muestreo antes de intentar validar todo. Muestra un conjunto pequeño (por ejemplo, registros recientes por tenant o por día), revisa los desajustes, corrige tu mapeo y amplia cobertura hasta que te sientas cómodo ejecutando comprobaciones sobre el conjunto completo de datos.
Cuando rastrees desajustes, mantén categorías que sean fáciles de actuar:
- Missing: el valor existe en JSON pero no hay fila en las nuevas tablas.
- Different: ambos existen pero no coinciden tras la normalización (tipos, redondeo, mayúsculas/minúsculas).
- Invalid: el JSON no se puede parsear o falla validación.
- Unexpected: las nuevas tablas contienen valores que nunca existieron en JSON.
Decide la fuente de la verdad durante la transición y escríbela. Opciones comunes son “JSON es la verdad (las tablas nuevas son derivadas)” o “las tablas nuevas son la verdad (JSON es un espejo de compatibilidad)”. Elige una por fase. Si no, los ingenieros acabarán “arreglando” desajustes actualizando ambos lados de formas distintas.
Los guardarraíles hacen los errores más baratos: feature flags para lecturas, límites estrictos en cuántas filas puede cambiar un job de backfill por ejecución y alertas cuando la tasa de desajustes sube. Mantén cada fase reversible con un camino de rollback claro: un interruptor para volver a lecturas JSON, una forma de pausar escrituras y un plan de limpieza para datos migrados parcialmente.
Cambia gradualmente las lecturas sin romper a los usuarios
Una vez que las nuevas tablas están pobladas y se mantienen actualizadas, cambia cómo lees datos en pasos pequeños. Trata cada ruta de lectura como una release independiente, no como un gran interruptor.
Pon la nueva lectura detrás de un feature flag. Despliégala a una porción muy pequeña de tráfico primero (o sólo a cuentas internas) y luego expande. Esto mantiene los fallos contenidos y facilita el rollback.
Una secuencia práctica que funciona para la mayoría de apps:
- Cambia una pantalla o endpoint API a la vez.
- Mantén la lectura desde JSON como fallback para ese endpoint.
- Compara resultados en segundo plano y registra desajustes.
- Aumenta la exposición gradualmente (1%, 10%, 50%, 100%).
- Elimina el fallback sólo después de que los resultados coincidan durante un tiempo.
Después de cada cambio, observa lo que sienten los usuarios primero: tasas de error, timeouts y consultas lentas. Las lecturas normalizadas pueden convertir accidentalmente una consulta en muchas pequeñas, y un índice faltante puede volver lenta una página que antes era rápida. Añade alertas antes del despliegue, no después.
Mantén las escrituras duales hasta confiar en las nuevas lecturas bajo carga real. Si dejas de escribir en el blob demasiado pronto, un rollback se convierte en un incidente de pérdida de datos. La escritura dual es un seguro. Elimínala sólo cuando estés seguro de que no necesitarás volver atrás.
Mientras migras, haz explícitas las dependencias sólo-blob. Si una función sigue dependiendo de una clave sólo en JSON, decide si pasa a una columna/tabla real o se elimina. Dejarlo vago es cómo los equipos terminan leyendo de ambos modelos para siempre.
Errores comunes que causan pérdida de datos o tiempo de inactividad
La mayoría de los outages en una migración de JSON a tablas ocurren porque el trabajo se trata como un único interruptor. En realidad, vas a ejecutar dos modelos de datos simultáneamente por un tiempo, y la superposición es donde ocurren los fallos.
Un fallo común es activar escrituras duales sin decidir qué pasa cuando las dos escrituras discrepan. Incluso si ambas actualizaciones ocurren en la misma petición, necesitas una política de conflictos (qué lado gana) y una forma de detectar y reproducir escrituras faltantes.
Los backfills también causan problemas cuando no pueden reanudarse. Los jobs largos se interrumpirán: despliegues, timeouts, filas bloqueadas o una fila mala. Si el job vuelve a empezar desde el inicio, arriesgas duplicados, actualizaciones parciales o una carga pesada que parece un denial of service a tu propia base de datos.
La deriva silenciosa de datos es otro gran problema. Los equipos “limpian” el significado de un campo durante la migración (como cambiar valores de estado o formatos de fecha) y olvidan documentar el mapeo. Todo parece bien hasta que informes, correos o facturación se comportan distinto.
Los errores que aparecen con más frecuencia:
- No tener política clara de conflictos para escrituras duales y no tener un rastro de auditoría para detectar desajustes.
- Backfills que no son idempotentes (seguro ejecutarlos dos veces) y no usan checkpoints.
- Cambiar el significado de campos a mitad de la migración sin un mapeo versionado y pruebas.
- Olvidar lectores downstream: consultas analíticas, exportaciones, webhooks y jobs en segundo plano.
- Eliminar la columna JSON demasiado pronto, antes de que las lecturas estén totalmente movidas y verificadas.
Un ejemplo real: una app guarda “perfil de usuario”, “suscripción” y “permisos” en un JSON. Un backfill copia datos a tablas nuevas, pero un job nocturno sigue leyendo JSON y sobreescribe las tablas normalizadas, borrando cambios recientes. La solución suele ser reglas claras: backfills reanudables, mapeos estrictos y conservar la columna antigua hasta que pruebes que el nuevo modelo coincide con la realidad.
Lista rápida antes del cutover
El día del cutover debería sentirse aburrido. Si todavía parece una apuesta, probablemente necesites un ensayo más.
- Las tablas y releases son seguras para desplegar: las nuevas tablas existen en producción, las migraciones se pueden volver a ejecutar de forma segura y has verificado los índices y restricciones que importan.
- El backfill es visible y repetible: puedes ver progreso, totales de errores y checkpoints, y puedes re-ejecutar sin duplicar filas.
- La escritura dual está activada y las reglas de conflicto están por escrito: sabes qué fuente gana (por ejemplo, gana la marca de tiempo más reciente) y registras conflictos.
- Los switches de lectura están protegidos: las lecturas se pueden alternar por endpoint o tenant usando feature flags, y puedes revertir rápido.
- La tasa de desajustes es aceptable y el rollback está probado: comparas totales clave, revisas registros y has practicado rollback en datos similares a producción.
Escenario de ejemplo: limpiar una app creada por IA que guardaba todo en JSON
Un fundador lanza en fin de semana un prototipo CRM generado por IA. Funciona para demos, pero cada perfil de cliente se guarda como un blob JSON en una sola columna. Un perfil puede incluir nombre, email, estado, last_contacted, notas y campos personalizados.
Tres meses después aparece el dolor. Los informes son lentos porque la base de datos tiene que escanear y parsear JSON para cada gráfico. Peor aún, el campo status es un caos: "Active", "active", "ACTIV", "In progress", "In-Progress" y "inprogress" significan más o menos lo mismo. Los filtros pierden registros, los dashboards discrepan y las notas de ventas acaban asociadas a la etapa equivocada.
Una primera porción segura es normalizar solo lo que impulsa el dashboard: clientes y estados.
Esa porción puede ser:
- Una tabla
customerscon columnas estables (id,name,email,created_at). - Una tabla de lookup
statuses(id,canonical_name) con un conjunto permitido. - Una forma de conectarlas (o
customers.status_ido una tablacustomer_statusseparada, según necesidades históricas).
Luego backfill desde el JSON existente:
- Parsear cada blob de perfil e insertar o actualizar la fila de customer.
- Mapear cadenas de estado desordenadas a estados canónicos, con una categoría clara de “desconocido”.
- Registrar todo lo que falle parseo para arreglar datos en lugar de adivinar.
El cutover permanece escalonado. Primero, cambia solo las lecturas del dashboard a las nuevas tablas. Mantén las lecturas JSON para el resto de la app mientras comparas recuentos y totales. Cuando el dashboard esté correcto y rápido, mueve las pantallas restantes una por una.
Próximos pasos: terminar la migración y mantenerla limpia
Una vez que tus lecturas estén totalmente en las nuevas tablas y hayas tenido un periodo estable sin sorpresas, decide qué hacer con la columna JSON antigua. La mayoría de equipos la congelan (no más escrituras, mantenerla por una ventana de seguridad) o la eliminan después de copias de seguridad y aprobación.
Si pospusiste características de seguridad para moverte rápido, añádelas ahora. Las tablas normalizadas rinden frutos a largo plazo cuando previenen datos malos, no solo cuando almacenan datos.
Fija el nuevo contrato
Escribe las reglas de las que ahora depende la app: qué campos son obligatorios, qué significa “válido” y dónde vive cada dato. Esto se convierte en el contrato de datos para futuras funciones y ayuda a nuevos miembros a no reintroducir un blob “por ahora”.
Una página es suficiente: nombres de tablas, columnas clave, ownership (quién escribe qué) y un ejemplo corto de un registro válido.
Evita volver a los blobs
Después de la migración, el mayor riesgo es la deriva: nuevas funciones empiezan silenciosamente a meter campos en una columna JSON de propósito general.
Congela o elimina la columna JSON tras una ventana de estabilidad definida. Añade las restricciones e índices que pospusiste (foreign keys, unique constraints, NOT NULL y los índices que tus consultas principales necesitan). Si mantienes un campo JSON para metadatos realmente “misceláneos”, añade una verificación ligera para que no aparezcan claves nuevas sin un plan.
Si heredaste un codebase generado por IA que usa mucho blobs JSON y necesitas que aguante en producción, FixMyMess (fixmymess.ai) se centra en diagnosticar y reparar este tipo de arquitecturas generadas por IA, incluyendo migraciones por fases, correcciones de lógica y hardening de seguridad, con verificación humana antes de que los cambios se desplieguen.