Migrar SQLite a Postgres: un playbook de corte por fases
Un playbook práctico para migrar SQLite a Postgres en apps creadas por IA: mapeo de esquema, tipos de datos, cambios de índices, corte por fases y comprobaciones.
Por qué esta migración es arriesgada en apps creadas por IA
Los prototipos generados por IA a menudo “funcionan” porque SQLite es permisivo. Acepta valores extraños, tipos sueltos y te permite avanzar con una configuración mínima. Muchas herramientas de IA también usan SQLite por defecto porque no requiere configuración y es fácil de distribuir. El problema es que esos atajos tempranos se convierten en suposiciones ocultas en tu código.
Cuando migras SQLite a Postgres, las primeras roturas suelen parecer pequeñas pero se propagan rápido. Una consulta que funcionaba en SQLite puede fallar en Postgres por tipado más estricto, comportamiento diferente de fechas y booleanos, y comparaciones sensibles a mayúsculas. Las migraciones también pueden fallar porque SQLite te permitió añadir columnas o cambiar tablas de formas que no se traducen bien a Postgres.
Lo que suele fallar primero:
- Autenticación y sesiones (manejo de timestamps, constraints de unicidad, sensibilidad a mayúsculas)
- Consultas que “funcionaban en local” (casts implícitos, comportamiento laxo de GROUP BY)
- Jobs en segundo plano e importaciones (datos malos que SQLite toleró)
- Rendimiento (índices faltantes que SQLite no denunciaba)
- Scripts de despliegue (suposiciones sobre BD en fichero vs BD servidor)
Vale la pena migrar cuando necesitas concurrencia, backups reales, mejor planificación de consultas, controles de acceso más seguros, o cuando ya te quedas pequeño con un nodo único. No vale la pena si la app se tira cada semana, no tienes requisitos estables o el cuello de botella es el ajuste del producto, no la base de datos.
“Sin sorpresas de downtime” no significa sin riesgo. Significa que planificas los modos de fallo comunes, mides el progreso y tienes una ruta clara de rollback. En la práctica, apuntas a que no haya una interrupción visible para usuarios o a una ventana programada corta con una salida clara.
Este playbook sigue un arco simple: inventariar lo que realmente tienes, traducir el esquema con cuidado, convertir datos de forma segura, planear índices y rendimiento, ejecutar un corte por fases con sincronización, aplicar los cambios de app que se suelen olvidar y, finalmente, probar y ensayar el rollback. Si tu app fue generada por herramientas como Lovable, Bolt, v0, Cursor o Replit, equipos como FixMyMess suelen empezar con un diagnóstico rápido del código para detectar suposiciones específicas de SQLite antes de tocar datos de producción.
Qué inventariar antes de tocar la base de datos
Antes de migrar SQLite a Postgres, aclara qué es lo que realmente tienes. Las apps construidas por IA a menudo “funcionan” en una demo, pero ocultan sorpresas como coerción de tipos silenciosa, SQL ad-hoc y jobs en segundo plano que siguen escribiendo mientras intentas mover datos.
Empieza con un mapa tabla por tabla. Necesitas nombres, conteo de filas y qué tablas están creciendo rápido. Las tablas más grandes suelen marcar tu plan de corte porque tardan más en copiarse y son las más costosas de reindexar.
Si puedes, captura una instantánea rápida de tamaño y crecimiento:
-- SQLite: approximate quick checks
SELECT name FROM sqlite_master WHERE type='table';
SELECT COUNT(*) FROM your_big_table;
Después, comprende el tráfico. Una migración raramente se bloquea por lecturas; se bloquea por escrituras que olvidaste: webhooks, colas, tareas programadas y “scripts auxiliares” que alguien ejecuta manualmente.
Aquí tienes una lista de inventario simple que evita la mayoría de sorpresas de downtime:
- Tablas: conteo de filas, tablas más grandes y cualquier tabla “caliente” con actualizaciones frecuentes
- Flujo de datos: qué endpoints escriben, cuáles solo leen y qué jobs se ejecutan por horario
- Estilo de consultas: dónde usas un ORM frente a SQL en bruto dentro del código
- Peculiaridades de SQLite: lugares que dependen de tipado laxo, booleanos implícitos o manejo extraño de fechas
- Configuración: dónde se almacenan e inyectan cadenas de conexión, claves de API y secretos de BD
El SQL en bruto es la trampa clásica. Un ORM puede adaptar consultas para Postgres, pero un snippet copiado de una herramienta de chat podría usar sintaxis exclusiva de SQLite o asumir comportamiento de ordenación NULL.
Ejemplo concreto: un prototipo generado en Replit podría guardar booleanos como "true"/"false" en una tabla, 0/1 en otra, y confiar en que SQLite acepta ambos. Postgres te obligará a elegir, y esa elección afecta consultas, índices y lógica de la app.
Si heredaste una app generada por IA y desordenada, un diagnóstico corto del código (como el que hace FixMyMess) puede descubrir escritores ocultos y supuestos específicos de SQLite antes de que se conviertan en un corte fallido.
Traducción de esquema sin sorpresas posteriores
Cuando migras SQLite a Postgres, el mayor riesgo no es copiar los datos. Es descubrir que tu app dependía de comportamientos de SQLite que nunca documentaste.
SQLite a menudo “acepta” un esquema vago: falta de claves foráneas, tipos de columna sueltos y reglas implícitas en el código de la app. Las apps generadas por IA empeoran esto porque el esquema pudo haberse creado rápido y luego parcheado en caliente.
Haz el esquema explícito (tablas, claves, relaciones)
Empieza escribiendo un mapa claro de cada tabla y cómo se conectan las filas. No te fíes de lo que crees que hace la app: confirma con el esquema real y datos reales.
Una forma práctica de traducir es trabajar con este orden:
- Define la clave primaria de cada tabla y si debe cambiar alguna vez.
- Decide cómo funcionan las relaciones (1:1, 1:muchas) y añade claves foráneas deliberadamente.
- Añade las restricciones que asumías implícitamente (NOT NULL, UNIQUE, CHECK).
- Maneja relaciones circulares creando tablas primero y luego agregando las foreign keys.
- Mantén nombres consistentes (columnas como userId vs user_id causan bugs silenciosos después).
IDs autoincrementales: elige la versión de Postgres ahora
En SQLite, INTEGER PRIMARY KEY es un caso especial que auto-incrementa. En Postgres deberías elegir GENERATED BY DEFAULT AS IDENTITY (o ALWAYS) en lugar del antiguo SERIAL, y documentarlo.
Ejemplo: un prototipo de IA podría insertar usuarios sin un id explícito y asumir que los ids nunca colisionan. Si rellenas datos y olvidas ajustar la secuencia de identidad, la siguiente inserción puede fallar o, peor, reutilizar ids.
Finalmente, haz que tu script de migración sea re-ejecutable. Postgres es más estricto, así que apunta a scripts idempotentes: crea objetos solo si faltan y añade constraints de forma controlada para que una ejecución parcial pueda reanudarse sin adivinar.
Desajustes de tipos y conversiones seguras
Cuando migras SQLite a Postgres, los bugs más temibles vienen de diferencias de tipo silenciosas. SQLite guarda con gusto "true" en una columna que pensabas era entera. Postgres no lo hará, y eso es bueno, pero significa que necesitas conversiones explícitas.
Los desajustes que causan fallos reales
Algunos patrones aparecen una y otra vez en apps generadas por IA:
- Booleanos: las apps SQLite usan 0/1, "true"/"false" o incluso cadena vacía. En Postgres usa
booleany convierte con reglas claras (por ejemplo: solo 1 y "true" -> true). - Enteros guardados como texto: IDs y contadores pueden guardarse como strings. Convierte solo si todos los valores están limpios; si no, mantén texto y añade una columna entera nueva que rellenes con seguridad.
- Nulls y defaults: SQLite puede comportarse holgadamente con valores faltantes. Postgres hará cumplir
NOT NULLy defaults. Si filas viejas contienen nulls, añade la restricción solo después de rellenarlas.
Datetime es otra trampa. Proyectos SQLite suelen guardar fechas como strings en hora local, formatos mixtos o segundos epoch. Elige un estándar: timestamptz en UTC suele ser lo más seguro. Convierte desde un formato conocido a la vez y registra filas que no se parsean. Si la app muestra “ayer” para usuarios en distintas zonas, a menudo es señal de mezclar hora local con UTC.
Los campos JSON requieren una elección deliberada. Si consultas dentro del JSON (filtrar por una clave, indexar), usa jsonb. Si solo guardas y recuperas blobs, text puede bastar, pero pierdes validación y capacidad de consulta.
Dinero y decimales no deben usar floats. Si un checkout generado por IA suma $19.989999, arréglalo usando numeric(12,2) (o la escala que necesites) y redondeando durante la conversión.
Un enfoque práctico es ejecutar una conversión en seco sobre una copia de datos de producción, contar fallos por columna y solo entonces fijar tipos y restricciones finales.
Índices y cambios de rendimiento a planear
Cuando migras SQLite a Postgres, la app puede “funcionar” pero ir más lenta. Una gran razón es que SQLite y Postgres eligen distinto cuándo y cómo usar índices.
SQLite puede arreglárselas con menos índices porque corre en proceso, con un planner simple y cargas más pequeñas. Postgres está diseñado para concurrencia y datos mayores, pero es estricto sobre estadísticas, selectividad de índices y forma de las consultas. Si una app generada por IA salió con escaneos de tabla completos accidentales, Postgres los ejecutará, solo que a un coste mayor y más visible.
Empieza por elegir índices a partir de consultas reales, no conjeturas. Extrae las consultas de lectura y escritura más frecuentes (login, listados, búsquedas, dashboards) y diseña en torno a ellas. Ejemplo rápido: si la app ejecuta frecuentemente WHERE org_id = ? AND created_at >= ? ORDER BY created_at DESC LIMIT 50, un índice compuesto en (org_id, created_at DESC) suele ser más útil que dos índices por columna.
Índices compuestos y unicidad
El orden importa en un índice compuesto de Postgres. Pon primero el filtro más selectivo (a menudo org_id o user_id), luego la columna usada para ordenar o para búsquedas por rango. Añade la dirección de orden cuando coincida con la consulta.
Además, separa la idea de “debe ser único” de “ayuda al rendimiento”. Una constraint UNIQUE hace cumplir una regla de negocio y crea un índice único. Un índice único independiente puede ser útil para casos parciales, pero si es una regla de negocio, modelala como constraint para que quede claro.
Qué revisar cuando las consultas se vuelven lentas
Después del movimiento, céntrate en:
- Falta de índices compuestos para patrones comunes de filtro + orden
- Tipos de datos erróneos que causan casts (que pueden impedir uso de índices)
- Estadísticas obsoletas (ejecuta ANALYZE tras cargas masivas)
- Escaneos secuenciales en tablas grandes donde esperabas índices
- Sobrecarga de escrituras por tener demasiados índices en tablas calientes
Si heredaste un esquema generado por IA con “indexar todo” o “no indexar nada”, aquí es donde una auditoría rápida (como la que hace FixMyMess) paga rápidamente.
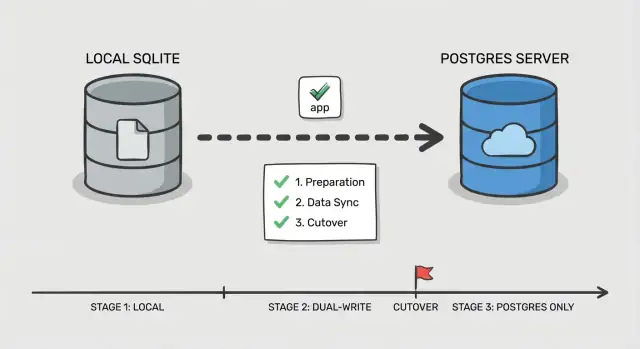
Plan de corte por fases paso a paso
Un corte seguro no es tanto un gran interruptor como probar que cada pieza funciona mientras los usuarios siguen usando la app. Esto importa aún más cuando migras SQLite a Postgres en una app creada por IA, donde las consultas ocultas y casos límite son comunes.
Fase 0: Decide cómo vas a cambiar
Elige un orden simple: cambiar lecturas primero, luego escrituras. Las lecturas son más fáciles de validar y revertir. Las escrituras cambian la fuente de verdad, así que trátalas como el paso final.
Añade un punto de control en la app: un feature flag o un toggle de configuración que seleccione qué base de datos maneja lecturas y cuál escrituras. Mantenlo simple y explícito para poder cambiarlo rápido en caso de incidente.
Fases 1-5: Ejecuta el corte en pequeños movimientos
Antes de tocar tráfico, prepara Postgres (base de datos, usuarios, roles y acceso con privilegios mínimos). Asegúrate de que tu app pueda conectar en el mismo entorno donde corre hoy.
Luego sigue un flujo por fases:
- Copia masiva: toma un snapshot de SQLite y cárgalo en Postgres.
- Sincronización incremental: mantiene Postgres actualizado con cambios nuevos mientras la app sigue escribiendo en SQLite.
- Corte de lectura: dirige las lecturas a Postgres, mantén las escrituras en SQLite y vigila tasas de error y consultas lentas.
- Corte de escritura: dirige las escrituras a Postgres, mantén una ventana corta donde puedas volver atrás.
- Finalizar: para la sincronización, revoca credenciales antiguas y deja SQLite en modo solo lectura por un período definido.
Define el rollback antes de cambiar nada: qué toggle se revierte, qué datos podrías perder y cómo lo manejarías. Por ejemplo, si la app genera sesiones de usuario y reseteos de contraseña, decide si esas tablas necesitan tratamiento especial para que un rollback no rompa logins.
Si necesitas una segunda opinión, FixMyMess suele ayudar a equipos a ensayar este plan en bases de código generadas por IA antes del corte real.
Mantener datos sincronizados durante la transición
Cuando migras SQLite a Postgres con un corte por fases, lo difícil no es copiar la instantánea inicial. Es mantener los cambios consistentes mientras los usuarios reales siguen interactuando.
Dos patrones simples de sincronización (y cuándo usarlos)
Si la app tiene poco tráfico y los cambios son fáciles de reproducir, trabajos de backfill periódicos pueden funcionar: copia inicial, luego un job programado que copie filas cambiadas desde la última ejecución (usando updated_at o una tabla de eventos append-only). Es simple, pero aumenta el riesgo de diferencias de última hora justo antes del corte.
Si la app está en uso activo, escribir en doble (dual-write) es más seguro: cada escritura va a ambas bases durante un periodo. Es más trabajo, pero reduce la brecha y hace el corte menos estresante.
Mantener consistencia de IDs
Decide desde el principio qué sistema controla las claves primarias. La regla más simple: conserva los mismos IDs en Postgres y no los renumeres. Si SQLite usó IDs enteros, ajusta las secuencias de Postgres para empezar por encima del máximo actual y evitar colisiones. Si cambias a UUIDs, añade primero una columna UUID, rellenala y conserva el ID antiguo como referencia externa estable hasta que la app esté totalmente migrada.
Para evitar confusiones, define reglas de conflicto:
- Elige una sola fuente de verdad para escrituras (a menudo Postgres una vez que empieza el dual-write)
- En caso de mismatch, “gana el latest updated_at” solo si los relojes son fiables
- Para dinero, permisos y auth, prefiere reglas explícitas sobre timestamps
- Registra cada conflicto para revisión
Mantén ambos sistemas en paralelo el tiempo suficiente para cubrir el uso normal (a veces unos días, a veces un ciclo de negocio completo). Registra métricas para detectar deriva rápido: conteos por tabla, checksums de muestra para tablas calientes, fallos de escritura por endpoint y una pequeña auditoría de IDs cambiados. Aquí es donde equipos piden a FixMyMess verificar el comportamiento de dual-write y detectar deriva antes que los clientes.
Cambios a nivel de app que suelen pasarse por alto
El cambio de base de datos es solo la mitad del trabajo. Muchos equipos migran datos, apuntan la app a Postgres y luego pasan el día persiguiendo errores raros que nunca aparecieron en SQLite.
Configuración de conexiones y pooling
SQLite suele ser “un fichero, baja concurrencia”. Postgres es un servidor y aceptará demasiadas conexiones hasta que de repente no pueda más.
Si tu app usa un pool, establece un límite real y timeouts. Un patrón de fallo común tras migrar SQLite a Postgres es que jobs en segundo plano y la app web abran cada uno su propio pool, multiplicando conexiones y causando ralentizaciones que parecen “Postgres lento” cuando en realidad es “demasiadas conexiones”.
Consultas que dependían de la permisividad de SQLite
SQLite a menudo devuelve resultados incluso cuando el SQL está algo sucio. Postgres es más estricto, y esa severidad suele ser positiva.
Vigila comparaciones entre tipos (texto contra números), casts implícitos y uso laxo de GROUP BY. Revisa también la coincidencia de cadenas y reglas de mayúsculas, porque una búsqueda que “funcionaba” en SQLite puede comportarse distinto si dependías de insensibilidad a mayúsculas.
Las transacciones y supuestos de bloqueo también pueden cambiar. Código que iba bien con “escribe cuando sea” puede ahora chocar con deadlocks o contención si envuelve lecturas y escrituras pesadas en una transacción larga.
Auth y almacenamiento de sesiones es otra trampa silenciosa. Si tus sesiones, tokens de reseteo o refresh tokens viven en la BD, pequeñas diferencias (timestamps, constraints de unicidad o jobs de limpieza) pueden provocar cierres de sesión masivos o flujos de login rotos.
Aquí tienes una lista rápida de comprobaciones del lado de la app que detectan la mayoría de sorpresas:
- Confirma que cada proceso de la app (web, workers, cron) lee la misma config de BD y límites de pool.
- Sustituye SQL exclusivo de SQLite (quirks en upserts, funciones de fecha o manejo de booleanos).
- Audita SQL en bruto por diferencias en comillas y estilo de parámetros.
- Revisa límites de transacción y asegura que jobs largos no retengan locks más de lo necesario.
- Verifica tablas de sesiones y tokens, lógica de expiración y constraints de unicidad.
Ejemplo: un prototipo generado por IA puede guardar sesiones en una tabla con columna "createdAt" como texto y compararla con "now" como string. Eso puede aparentar funcionar en SQLite, pero romper las comprobaciones de expiración en Postgres a menos que la conviertas a timestamp real.
Si heredaste una base de código de herramientas como Replit o Cursor, servicios como FixMyMess tienden a encontrar aquí los puntos de ruptura ocultos: los datos están bien, pero la lógica de la app asumió el comportamiento de SQLite.
Pruebas, monitorización y ensayo de rollback
La mayoría de sorpresas de downtime ocurren porque el corte se trata como un evento único y no como un procedimiento ensayado. Las apps creadas por IA son especialmente riesgosas porque suelen tener validación débil, consultas inconsistentes y casos límite que solo aparecen con datos reales.
Empieza con un smoke test repetible que puedas ejecutar en minutos en ambas BDs. Manténlo pequeño y centrado en rutas de usuario reales, no en todas las características.
- Registro/login/logout (incluyendo reseteo de contraseña si existe)
- Crea un registro central (por ejemplo: proyecto, pedido o nota)
- Edita ese registro y verifica que el cambio sea visible donde deba
- Elimínalo (o soft-delete) y confirma que los permisos sigan funcionando
- Ejecuta una pantalla admin/reporte que haga joins entre varias tablas
Después, haz una prueba de lectura en paralelo. Para una porción del tráfico o un cron, lee desde Postgres y SQLite al mismo tiempo y compara resultados. Registra discrepancias con contexto suficiente para debug (id de usuario, inputs de consulta y las claves primarias devueltas). Esto detecta diferencias sutiles como orden distinto, manejo de NULL, sensibilidad a mayúsculas y conversiones de zona horaria.
Carga las endpoints que tocan tus tablas más ocupadas, no toda la app. Un caso común al migrar SQLite a Postgres es que una consulta que “iba bien” necesite un índice faltante o un join mejor. Observa la latencia p95 y la saturación del pool de conexiones.
Finalmente, ensaya el rollback una vez y cronometra. Anota los pasos exactos, quién los ejecuta y qué significa “parar el mundo” (flip de feature flag, modo solo lectura o drenado de tráfico). Define métricas de éxito antes de empezar: tasa de error aceptable, techo de latencia p95 y un conteo de discrepancias que debe llegar a cero (o una lista de excepciones justificada).
Errores comunes y cómo evitarlos
SQLite es permisivo. Postgres es estricto. Muchos equipos se queman porque la app funcionó “de alguna manera” en SQLite y luego falla al migrar a Postgres.
Una trampa común es suponer que los tipos de datos “simplemente funcionarán”. SQLite guarda texto en una columna que parece entera o fechas como cadenas aleatorias. Postgres no. Antes de mover datos, escanea columnas con valores mixtos ("", "N/A" o "0000-00-00") y decide cuál debe ser el tipo real.
Los índices son otra tarea clásica pospuesta que se vuelve un incendio en producción. SQLite puede sentirse rápido en datasets pequeños incluso sin índices. Postgres puede ralentizarse en cuanto llega tráfico real si olvidas índices para foreign keys, filtros comunes y columnas de orden.
Los cortes fallan cuando las escrituras se cambian demasiado pronto. Si empiezas a escribir en Postgres antes de poder detectar deriva, no sabrás cuál BD es “la correcta” cuando algo vaya mal. Añade comprobaciones de deriva (conteos, rangos de updated-at, checksums en tablas clave) antes de confiar en el nuevo sistema.
También vigila una ruta de fichero SQLite escondida. Las apps generadas por IA suelen tener un valor por defecto como ./db.sqlite embebido en una variable de entorno o imagen Docker. Todo parece bien en staging y en producción siguen escribiendo al fichero antiguo.
Las migraciones largas son el asesino silencioso en tablas grandes. Un único ALTER TABLE o backfill puede bloquear escrituras lo suficiente para causar timeouts.
Evita esto con una lista de verificación pre-flight:
- Audita columnas “desordenadas” y normaliza valores antes de castear tipos.
- Crea índices en Postgres antes de que termine la carga completa.
- Mantén dual-write o change capture apagado hasta que las comprobaciones de deriva funcionen.
- Busca en configs y containers rutas SQLite residuales.
- Divide backfills grandes en lotes con límites de tiempo.
Si heredaste una base de código generada por IA, equipos como FixMyMess suelen empezar con una auditoría rápida para sacar a la luz estos riesgos antes de la ventana de corte.
Lista rápida y siguientes pasos
Si solo recuerdas una cosa al migrar SQLite a Postgres, que sea esta: la mayoría de sorpresas de downtime vienen de pequeñas brechas entre tu plan y lo que la app realmente hace en producción.
Pre-corte (prepárate)
Haz esto antes de tocar tráfico de producción. Si hay alguna incertidumbre, pausa y confirma con una prueba rápida.
- Confirma que los backups se restauran limpiamente (no solo que existen) y captura el estado exacto para la ventana de corte.
- Valida que el esquema traducido coincide con el uso real: constraints, defaults y comportamiento de timestamps.
- Asegura que la ruta de sincronización ya corre y es estable (dual writes o change capture), con responsabilidad clara sobre fallos.
- Ejecuta una prueba de carga corta en Postgres en condiciones parecidas a producción y verifica las páginas o endpoints más importantes.
Corte (cambia con seguridad)
El objetivo es un cambio rápido y aburrido con señales claras y una salida definida.
- Usa un toggle único y explícito (env var, flag de config o switch en el router) y define quién lo acciona.
- Pon monitorización visible antes del cambio: tasa de errores, latencia, conexiones BD y lag de replicación/sync.
- Ten listo y practicado el rollback: cómo apuntar la app de vuelta y cómo manejar escrituras durante el corte.
Tras el cambio, verifica primero la corrección y después la velocidad. Compara conteos de filas y checksums para tablas clave, ejecuta consultas críticas de extremo a extremo (login, checkout, flujos de crear/editar) y revisa logs por errores nuevos como violaciones de constraints o sorpresas de zona horaria.
Luego, aborda el rendimiento con enfoque. Extrae las consultas más lentas que veas en producción, confirma que usan índices como esperas y arregla las pocas que causan la mayor molestia a usuarios.
Si tu app fue generada por herramientas como Lovable, Bolt, v0, Cursor o Replit, la capa de datos suele ocultar suposiciones inconsistentes (fechas como strings, constraints faltantes, consultas inseguras). FixMyMess ofrece una auditoría de código gratuita para detectar esos riesgos de migración temprano, antes de que te comprometas con un plan de corte.