Observabilidad del manejador de webhooks: registros, IDs de eventos, vista administrativa
Los webhooks fallan en silencio sin la visibilidad adecuada. Aprende la observabilidad de manejadores de webhook con verificaciones de firma registradas, IDs de eventos almacenados y una vista administrativa simple.
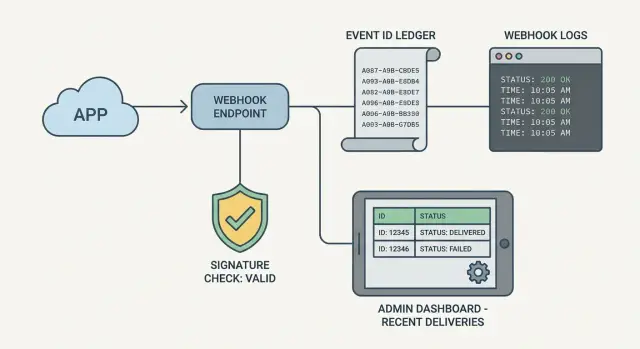
Por qué los manejadores de webhooks parecen invisibles cuando fallan
Los webhooks son más difíciles de depurar que las llamadas API normales porque no eres tú quien hace clic en el botón que envía la petición. Un proveedor envía un evento cuando quiere, desde una infraestructura que no controlas, y a menudo solo te enteras de que algo va mal cuando un cliente se queja.
Con un endpoint API típico, puedes reproducir la llamada, ver la respuesta y iterar. Con webhooks, el fallo puede ser silencioso: el proveedor reintenta en segundo plano, tu app devuelve un 500 genérico y te quedas con la duda de si la petición era auténtica, si tu código se ejecutó y dónde se detuvo.
La parte más frustrante es la brecha cuando empiezan los reintentos. Puedes ver un pico de tráfico y luego nada útil: ningún identificador claro de evento, ningún rastro de lo que pasó en cada intento y ningún registro de si ya lo procesaste. Ahí es donde cobras dos veces, pierdes una actualización de suscripción o creas registros duplicados.
La observabilidad del manejador de webhooks es simplemente poder responder unas pocas preguntas rápido, sin leer payloads crudos ni activar un modo debug ruidoso:
- ¿Quién envió esta petición y pasó la verificación de firma?
- ¿Qué evento fue (ID, tipo, timestamp) y ya lo habíamos visto antes?
- ¿Qué hizo nuestro handler y por qué falló (si falló)?
La buena observabilidad se mantiene pequeña, segura y fácil de mantener. No necesitas un sistema de monitorización complejo. Unos pocos registros estructurados, un ID de evento almacenado y una vista administrativa pequeña pueden convertir un webhook invisible en algo que entiendes en minutos.
Qué significa “observable” para un endpoint de webhook
"Observable" significa que cuando una entrega falla (o parece correcta pero produce un resultado equivocado), puedes responder qué pasó sin adivinar, re-enviar a ciegas o añadir prints puntuales.
Para cualquier entrega deberías poder responder:
- ¿Recibimos la petición y cuándo?
- ¿La verificación de firma pasó o falló, y por qué?
- ¿Cuál fue el evento (ID de evento) y ya lo procesamos?
- ¿Cuánto tardó el procesamiento y dónde se fue el tiempo?
- ¿Qué devolvimos al emisor (código de estado y tipo de error)?
Ese es el núcleo: una traza clara de "llegó" a "hecho", con contexto suficiente para depurar reintentos, duplicados y fallos parciales.
Una base sólida es capturar un pequeño conjunto de headers de la petición (no todos), el resultado de la verificación de firma (pasa/falla más una razón corta), un identificador de evento estable, timestamps (recibido/iniciado/terminado) y un resultado final (procesado, ignorado por duplicado, rechazado por inválido).
Ten cuidado con la privacidad. No registres secretos, firmas crudas, tokens de autenticación ni payloads completos por defecto. Si necesitas visibilidad del payload, almacena una instantánea mínima y redactada (por ejemplo: tipo de evento, hash de ID de cliente, importe) y guarda cualquier body crudo solo para debugging de corta duración en un lugar protegido.
Si los payloads pueden contener datos personales (nombres, correos, direcciones, datos de salud o financieros), trata los registros de webhooks como datos de usuario. Establece límites de retención, restringe el acceso y documenta quién puede verlos. Muchas veces esa diferencia distingue entre "registro útil" y un incidente de cumplimiento.
Registrar las verificaciones de firma sin filtrar secretos
La verificación de firma es la prueba de "¿eres realmente quien dices ser?" de tu webhook. Evita que llamadores aleatorios golpeen tu endpoint y se hagan pasar por tu proveedor de pagos, servicio de email u otro sistema.
Para observabilidad, quieres suficiente detalle para responder dos cosas rápido: ¿se ejecutó la verificación y por qué falló? El truco es registrar resultados y contexto, no material secreto.
Un patrón seguro es una entrada de verificación por petición, con campos útiles para soporte y debugging pero inocuos si se copian en un ticket.
Registra cosas como:
- Resultado:
verified=true/falsey unareasonclara comomissing_signature,bad_format,timestamp_out_of_windowomismatch - Qué esperabas: el nombre del algoritmo (por ejemplo
hmac-sha256) y qué header buscaste (solo el nombre del header) - Contexto temporal: timestamp del servidor, edad de la petición (segundos) y si se aplicó protección contra replays
- Identificadores: tu
request_idgenerado y, si está presente, el ID de evento del proveedor
No registres la clave secreta, el valor de la firma en bruto, el payload completo ni headers sin redactar.
Cuando la verificación falla, evita el logging de "volcar la petición". En su lugar, registra un resumen redactado pequeño: tamaño del payload, content-type y qué headers requeridos estaban presentes.
Añade contadores simples para que las fallas aparezcan aunque nadie esté mirando los logs. Como mínimo, lleva totales de verificados, fallidos y firmas faltantes (opcionalmente por proveedor). Si un deploy cambia por error el nombre esperado del header, tus logs deberían mostrar un pico en reason=missing_signature, en lugar de un 401 vago sin pista.
Almacenar IDs de eventos para deduplicar y trazar reintentos
La mayoría de proveedores reintentan el mismo evento si tu endpoint hace timeout, devuelve 500 o hay un problema de red. Si no almacenas un identificador estable del evento, puedes cobrar dos veces, aprovisionar dos veces o enviar emails duplicados. Guardar el ID de evento es la vía más sencilla a la idempotencia: el mismo evento puede llegarte 1 o 10 veces, pero solo aplicas sus efectos una vez.
Empieza por guardar un pequeño registro por cada webhook entrante, incluso si aún no haces nada más. Puedes mantenerlo en una tabla de base de datos, un store key-value o una cola más una tabla de auditoría pequeña.
Un registro mínimo suele incluir proveedor, ID de evento, timestamp de recepción, estado (received/processed/failed/ignored) y un mensaje de error corto opcional.
Luego, para cada petición, haz esto en orden: extrae el ID de evento, insértalo con una restricción única en (provider, event ID) y si ya existe, devuelve 200 rápido y omite la acción de negocio. Ese chequeo convierte los reintentos de suposiciones en una línea de tiempo confiable.
Algunos proveedores no envían un ID de evento claro, o tu handler no puede leerlo hasta después de la verificación de firma. En ese caso, deriva uno propio a partir de partes estables de la petición, como un hash de provider + ruta + un header estable + bytes del body crudo. Evita timestamps o cualquier cosa que cambie entre reintentos.
La retención importa porque los payloads de webhook suelen contener datos personales. Una regla práctica es mantener resúmenes más tiempo y datos crudos menos (o no mantenerlos). Conserva la fila de evento (provider, event ID, timestamps, estado) 30–90 días, guarda cualquier body crudo solo por una ventana corta (24–72 horas) si lo haces y limita la longitud de mensajes de error para reducir el riesgo de filtrar secretos.
Ejemplo: un proveedor de pagos reintenta el mismo evento invoice.paid tres veces. Con IDs de evento almacenados ves un registro marcado como procesado y luego entregas posteriores marcadas como duplicado, así sabes que el cliente no fue cobrado dos veces y por qué el proveedor siguió intentando.
Registrar el ciclo de vida: de recibido a procesado a respondido
Un webhook puede parecer "bien" porque el remitente obtuvo un 200, mientras tu app falló después. Para que la observabilidad sea real, separa la recepción de la entrega (lo que devuelves al remitente) del procesamiento de negocio (lo que tu app realmente hizo).
Cuando sea posible, reconoce rápido y luego haz trabajo pesado en segundo plano. Incluso si procesas en línea, registra ambas partes como pasos distintos para poder saber si el problema es verificación, parsing, trabajo en la base de datos o un timeout.
Un modelo de ciclo de vida simple que puedes consultar
Elige un pequeño conjunto de estados y apégate a ellos. La idea no es el detalle perfecto, sino respuestas rápidas.
Registra una fila (o documento) por evento entrante con:
- Timestamps: received, verified, processing started, processing finished, responded
- Duraciones: tiempo de verificación, tiempo de procesamiento, tiempo total
- Estado: received, verified, processed, failed, ignored
- Respuesta: código de estado, versión del handler (opcional), clase de error (sin secretos)
- Correlación: ID de evento del proveedor más tu ID de correlación interno
Con esto, los patrones emergen rápido. Si la mayoría de fallos ocurren después de la verificación y duran 25 segundos, probablemente hay una llamada lenta a la DB, un worker de cola atascado o un índice faltante.
Los IDs de correlación conectan el webhook con el resto del sistema
Un webhook raramente termina en el endpoint. Crea un usuario, marca una factura como pagada, envía un recibo por email o actualiza accesos.
Guarda el ID de evento del proveedor y genera un ID de correlación que pases a los logs y trabajos downstream. Entonces una búsqueda muestra la cadena: petición recibida, firma verificada, trabajo encolado, pago marcado como pagado, email enviado.
Esto importa en bases de código donde el handler mezcla "responder al webhook" y "hacer todo el trabajo" en una función. Hacer explícito el ciclo de vida convierte un misterio en una línea de tiempo.
Paso a paso: añadir observabilidad a un handler existente
Cada petición de webhook debería dejar un rastro que puedas seguir después, incluso si falla a mitad de camino.
Un orden práctico que funciona en un endpoint existente:
- Añade logs estructurados con un conjunto consistente de campos en cada petición (provider, event ID, request ID, firma verificada, resultado, duración).
- Verifica la firma temprano y luego registra solo el resultado (pass/fail) y por qué falló. Nunca registres la clave secreta ni la firma en bruto.
- Persiste el ID de evento del proveedor tan pronto como lo tengas y deduplica por él. Si es un reintento, devuelve una respuesta segura y registra que fue dedupeado.
- Envuelve la lógica de negocio para que siempre captures estado, tipo de error y tiempos, incluso cuando se lance una excepción.
- Añade una vista administrativa mínima que muestre eventos recientes de webhook y los detalles necesarios para responder "¿qué pasó?"
Después del primer paso, mantén estable el esquema de logs. Cuando los campos cambian cada semana, buscar se vuelve conjetura. Si puedes, genera un request ID en el borde y llévalo por los logs y el registro de evento.
Para las verificaciones de firma, haz que los mensajes de fallo sean humanos. "Firma fallida: header X ausente" es accionable. "Firma inválida" no lo es. Aquí también los equipos filtran datos sensibles por accidente, así que sé estricto con lo que registras.
Para la vista administrativa no necesitas un panel completo. Una tabla con los últimos 50 eventos más una página de detalle es suficiente. La página de detalle debe mostrar hora de recepción, ID de evento, estado de procesamiento, código de respuesta, duración y clase de error más reciente (por ejemplo: ValidationError vs DatabaseError).
Una vista administrativa pequeña que responda “¿qué pasó?”
No necesitas un dashboard completo para depurar webhooks. La vista administrativa mínima útil es una pantalla con una tabla de eventos recientes y un panel de detalle. Cuando alguien pregunte por qué un pago, registro o envío no se actualizó, deberías poder responder en dos minutos.
Una buena tabla de eventos recientes muestra suficiente para detectar patrones como reintentos repetidos, una caída del proveedor o que tu handler devuelve 500s. Manténla consistente para que sea fácil de escanear.
Incluye:
- ID de evento (el ID del proveedor, más tu ID interno si lo tienes)
- Proveedor y tipo de evento, hora de recepción
- Estado (received, verified, processed, failed, ignored)
- Intentos y hora del último intento
- Último mensaje de error (corto, recortado)
En el panel de detalle, céntrate en lo que alguien necesita a continuación: ¿pasó la verificación de firma?, qué versión del handler se ejecutó, qué respuesta se envió, timestamps clave (received/verified/processed) y el ID de correlación que enlaza con tus logs.
Las acciones pueden ayudar, pero solo si son seguras: reprocesar (solo si el handler es idempotente), marcar como ignorado (para eventos de prueba o ruido conocido), añadir una nota interna y copiar un resumen para soporte (ID de evento, estado, último error).
Restringe esa vista solo a administradores y registra cada acción administrativa (quién lo hizo, cuándo y por qué).
Errores comunes que empeoran la depuración de webhooks
Un webhook puede estar "funcionando" y aun así ser imposible de entender cuando algo falla. El dolor suele venir de pequeñas decisiones que ocultan el fallo real o crean efectos secundarios ruidosos.
Un gran error es registrar payloads crudos completos. Muchos bodies incluyen correos, direcciones, tokens o secretos por accidente. En su lugar, registra un resumen seguro: tipo de evento, proveedor, ID de evento, timestamp de la petición y un hash corto del body. Si necesitas más detalle, almacena una copia cifrada con retención corta y acceso restringido.
Los reintentos también pueden ser autoinfligidos. Si un evento ya fue procesado, devolver una respuesta no-2xx suele provocar reintentos infinitos y acciones downstream duplicadas. Haz de "ya procesado" un resultado explícito y devuelve 2xx con una entrada de log clara diciendo que fue dedupeado.
Otra trampa común es mezclar fallos de verificación con fallos de procesamiento. Si la verificación falla, es una señal de seguridad. Si la lógica de negocio falla tras la verificación, es un bug de la app o un problema de datos. Si ambos aparecen como "error 500", pierdes la capacidad de actuar rápido.
Problemas operativos frecuentes:
- No aplicar timeouts a llamadas DB o APIs externas, de modo que el handler se queda colgado hasta que el proveedor abandona
- Errores registrados sin nombre del proveedor, tipo de evento, ID de evento y request ID interno
- Solo registrar excepciones, no la decisión tomada (ignored, queued, processed, deduped)
- Diferentes formatos de log entre entornos, que dificultan las comparaciones
Ejemplo: un proveedor de pagos reintenta un evento 12 veces. Tus logs muestran 12 líneas "500" pero sin pista de si la firma falló, la DB hizo timeout o el evento ya fue procesado. Con observabilidad, la primera entrada mostraría "verified ok", la siguiente "DB timeout after 3s" y los reintentos posteriores serían dedupeados cuando se almacena el evento.
Comprobaciones rápidas antes de darlo por terminado
Prueba la observabilidad de tus webhooks como una persona estresada, cansada y con prisa. Si no puedes responder preguntas básicas rápido, el futuro tú sufrirá cuando el proveedor reintente el mismo evento durante horas.
Empieza con un benchmark simple: elige un ID de evento real del proveedor y cronometra. Deberías poder encontrar ese evento (y su historial de entregas) en menos de 30 segundos, sin adivinar qué servidor lo manejó.
Una lista de comprobación corta atrapa la mayoría de brechas:
- La búsqueda funciona: pegar el ID de evento del proveedor devuelve un registro claro, no cinco casi-duplicados
- El estado de la firma es obvio: los logs muestran verificado sí/no y la razón cuando falla
- Los reintentos son visibles: conteo de intentos y hora del último intento son fáciles de encontrar
- El tipo de fallo es claro: puedes distinguir excepción vs timeout vs fallo de validación
- Los datos son seguros: secretos y datos personales están excluidos o redactados en logs y almacenamiento
Haz un simulacro realista. Genera un evento que sepas que fallará (por ejemplo, un payload sin un campo obligatorio). Confirma que puedes responder: ¿llegó?, ¿pasó la verificación?, ¿qué devolviste?, ¿fue lento? y ¿se reintentó?
Por último, escanea por fugas accidentales. Los webhooks con frecuencia contienen correos, direcciones, tokens o metadatos de tarjetas. Los logs deben almacenar solo lo necesario para depurar: ID de evento, nombre del proveedor, timestamps, resultado de firma, estado y un mensaje de error corto.
Ejemplo: un webhook de pago fallido y cómo lo rastreas
Un ticket de soporte común: el proveedor de pagos envía un webhook invoice.paid, la tarjeta del cliente se carga, pero el cliente sigue sin acceso al plan de pago.
Con observabilidad, dejas de adivinar. Abres la vista administrativa y buscas por la ventana de tiempo. Encuentras la llamada exacta del webhook.
Las primeras preguntas se responden de inmediato: la verificación de firma está "pass", el ID de evento del proveedor está guardado (por ejemplo, evt_01H...) y el timestamp de la petición coincide con lo que muestra el proveedor. Sabes que es real y que llegó a tu servidor.
En el detalle del evento, el ciclo de vida muestra:
- Received: 2026-01-20 14:03:12
- Verified: pass
- Processing: failed
- Responded: 500
El campo de error apunta a la causa, por ejemplo "Cannot insert subscription row: missing user_id." Eso te indica que el bug está en tu código, no en el proveedor.
Ahora empiezan a llegar reintentos. Aquí es donde la idempotencia importa. Porque almacenas el ID de evento y lo tratas como único, el handler no otorga acceso dos veces. Entregas posteriores se registran como duplicados y se omiten, o se reejecutan de forma segura según tu diseño.
Después de arreglar el bug, puedes reprocesar el evento fallido desde la vista administrativa. El estado pasa a processed, la respuesta se vuelve 200 y el cliente obtiene acceso.
Para soporte, ahora tienes hechos limpios para compartir: el timestamp del evento original, el ID del evento y el estado actual (received, verified, processed, failed).
Siguientes pasos si tu código de webhook sigue siendo frágil
Si tu manejador de webhooks sigue siendo una caja negra, empieza por el cambio más pequeño que te dé señal: registra el resultado de la verificación de firma (pasa o falla) y almacena el ID de evento del proveedor. Eso suele convertir "no funcionó" en un camino claro hacia la solución sin tocar la lógica de negocio.
Mantén esos primeros logs aburridos y seguros. Registra resultados y tiempos, no secretos. Anota que la verificación falló, qué proveedor era y qué ID de evento se incluía, pero nunca registres headers crudos o valores de firmas.
Una vez captures IDs de evento y estados de forma fiable, añade una vista administrativa pequeña. No construyas un dashboard completo todavía. Una tabla simple que responda "¿lo recibimos?, ¿lo verificamos?, ¿lo procesamos?, ¿qué error ocurrió? y ¿qué devolvimos?" es suficiente.
Si el código del webhook fue generado por una IA y se siente poco fiable, planifica una pasada de limpieza. Señales comunes son suposiciones de autenticación rotas, comportamiento de reintentos desordenado (dobles cargos, emails duplicados) y secretos esparcidos en configuraciones o logs.
Un orden de trabajo práctico:
- Añadir logs estructurados para resultado de firma y request ID
- Guardar IDs de evento y deduplicar por ellos
- Registrar un ciclo de vida claro (received, verified, processed, failed)
- Añadir una vista administrativa pequeña para eventos recientes y errores
- Hacer un refactor focalizado en reintentos, idempotencia y manejo seguro de secretos
Si estás lidiando con un prototipo generado por IA y necesitas dejarlo listo para producción, FixMyMess (fixmymess.ai) se centra en diagnosticar y reparar código generado por IA, incluyendo manejadores de webhooks con auth frágil, bugs de reintento y logging inseguro.
Preguntas Frecuentes
¿Cuál es la forma más simple de hacer observable mi manejador de webhooks?
Comienza registrando tres cosas en cada petición: si la verificación de firma pasó, el ID de evento del proveedor y un resultado claro como processed, failed o deduped. Añade tiempos (llegada y fin) para detectar timeouts. Esa base pequeña suele convertir un 500 misterioso en algo sobre lo que puedes actuar rápido.
¿Por qué los errores de webhooks son tan difíciles de depurar comparados con llamadas API normales?
Los webhooks fallan en silencio porque no controlas cuándo ni desde dónde se envían, y los proveedores suelen reintentar en segundo plano. Sin IDs de evento almacenados y registros estructurados, cada reintento parece una petición nueva y no puedes saber si es duplicado, un problema de firma o un fallo real en el procesamiento.
¿Qué debo registrar para la verificación de firmas sin filtrar secretos?
Registra el resultado y la razón, no el material secreto. Un buen registro es verified=true/false más una razón corta como missing_signature o timestamp_out_of_window, junto con qué header verificaste y el nombre del algoritmo. No registres la clave de firma, la firma en bruto ni headers sin redactar.
¿Cómo evito que los reintentos provoquen cargos o registros duplicados?
Guarda el ID de evento del proveedor lo antes posible y aplica una restricción única en (provider, event_id). Si ya lo viste, responde rápido con 2xx y omite la acción de negocio, registrando que fue dedupeado. Esto evita dobles cargos, provisiones duplicadas y correos repetidos durante reintentos.
¿Qué hago si mi proveedor de webhooks no incluye un ID de evento fiable?
Derívalo de partes estables que no cambien entre reintentos, por ejemplo un hash de proveedor + ruta de petición + el cuerpo en bytes crudo, o un header estable más el cuerpo. Evita timestamps u otros valores que varíen en cada intento. Luego trátalo como un ID de evento normal para dedupe y trazabilidad.
¿Qué campos de ciclo de vida debo registrar para poder rastrear dónde falló?
Separa “recepción de entrega” de “procesamiento de negocio”. Registra cuándo llegó la petición, cuándo terminó la verificación, cuándo empezó y terminó el procesamiento y qué código de estado devolviste. Así queda claro si respondiste 200 pero el trabajo real falló después, o si el procesamiento lento provocó timeouts del proveedor.
¿Cómo registro datos de webhooks sin crear un problema de privacidad o cumplimiento?
Mantén resúmenes seguros por defecto: proveedor, ID de evento, tipo de evento, timestamps, estado y un mensaje de error corto que no contenga secretos ni datos personales. Si guardas cuerpos crudos, encríptalos, restringe el acceso y mantenlos por poco tiempo. Trata los registros de webhooks como datos de usuario por las posibles direcciones, emails o metadatos financieros.
¿Qué debe incluir una vista administrativa mínima para webhooks?
Una tabla de eventos recientes más una vista de detalle bastan. Muestra ID de evento, proveedor, tipo, hora de recepción, estado, intentos/último intento, resultado de firma, código de respuesta, duración y último tipo de error. Si añades reprocesar, asegúrate de que el manejador sea idempotente para que reejecutar no aplique efectos dos veces.
¿Cuáles son los errores más comunes que empeoran la depuración de webhooks?
No vuelques cuerpos crudos ni registres headers, tokens o firmas en bruto. No trates cada fallo como un 500 genérico: separa “firma falló” de “procesamiento falló”. Añade timeouts a llamadas externas y a la base de datos, y no olvides almacenar IDs de evento, porque sin ellos perderás la visión de duplicados y reintentos.
Mi código de webhook fue generado por una herramienta de IA y sigue fallando—¿qué debo hacer?
Si el manejador fue generado por IA y es poco fiable, empieza con una auditoría rápida de verificación de firmas, idempotencia, manejo de secretos y seguridad de registros. Si necesitas una reparación rápida, FixMyMess (fixmymess.ai) puede diagnosticar y reparar manejadores de webhooks generados por IA, endurecer la seguridad y hacer que los reintentos sean seguros, normalmente en 48–72 horas tras una auditoría de código gratuita.