Caché y paginación para páginas de lista lentas: patrones prácticos
Aprende caché y paginación para páginas de lista lentas con patrones prácticos de paginación por cursor, diseño de claves de caché y alternativas seguras a APIs que "devuelven todo".
Por qué las páginas de lista se ralentizan a medida que crecen tus datos
Una página de lista suele ir bien con 200 filas y de repente empieza a fallar con 20.000. Los usuarios notan desplazamiento lento, spinners que no paran y filtros que tardan segundos en responder. A veces la página muestra un estado vacío porque la petición caduca o el cliente se rinde y no renderiza nada.
El problema central es simple: cada registro extra hace que el sistema haga más trabajo. La base de datos tiene que encontrar las filas, ordenarlas y aplicar filtros. La API tiene que convertirlas a JSON. La red tiene que mover esos datos. Luego el navegador (o la app móvil) tiene que parsearlos, asignar memoria y renderizarlos.
Dónde se va el tiempo
A medida que tu conjunto de datos crece, las ralentizaciones suelen venir de una combinación de:
- Trabajo en la base de datos: escaneos grandes, joins costosos y ordenar resultados voluminosos.
- Tamaño del payload: devolver cientos o miles de filas por petición.
- Coste de renderizado: la UI intentando pintar demasiados elementos a la vez.
- Consultas repetidas: la misma lista solicitada una y otra vez sin caché.
Ordenar y filtrar tiene un coste oculto porque a menudo obliga a la base de datos a tocar mucha más información de la esperada. Por ejemplo, filtrar “status = open” es barato con el índice correcto, pero “buscar por nombre contiene” o “ordenar por última actividad” puede volverse caro rápidamente. Peor aún, añadir paginación por OFFSET (página 2000) puede hacer que la base de datos recorra miles de filas solo para llegar a la siguiente página.
El objetivo no es “hacerlo rápido una vez”. El objetivo es tiempo de respuesta predecible a medida que los datos escalan. Eso normalmente implica devolver menos registros por petición, usar paginación que no empeore en páginas profundas y cachear respuestas de lista para que las visitas repetidas no paguen todo el coste cada vez.
Evita endpoints de lista que "cargan todo"
Una razón común por la que las páginas de lista se vuelven lentas es una API que devuelve toda la tabla porque fue lo más rápido en la fase de prototipo. A menudo se parece a esto:
GET /api/orders
200 OK
[
{ "id": 1, "customer": "...", "notes": "...", "internalFlags": "...", ... },
{ "id": 2, ... }
]
Esto falla a escala porque multiplica el trabajo en tres sitios a la vez: la base de datos debe escanear y ordenar más filas, el servidor debe construir y enviar una respuesta JSON enorme, y el navegador debe parsearla y renderizar una lista larga. Incluso si más tarde añades caché y paginación para páginas lentas, un endpoint “devuélveme todo” sigue siendo caro de generar y de enviar.
Los móviles y las redes inestables lo notan primero. Una respuesta JSON de 5-10 MB puede funcionar en una Wi‑Fi de oficina, pero puede caducar en 4G, consumir batería y hacer que la app parezca rota. También hace que los errores sean más difíciles de recuperar: si una petición falla, el usuario pierde toda la página en lugar de solo la siguiente porción.
Aquí hay una regla simple para mantenerte honesto: envía solo lo que el usuario puede ver ahora. Eso suele significar una página pequeña (por ejemplo, 25-100 filas) y solo los campos necesarios para la vista de lista.
Cuando los equipos traen a FixMyMess un panel de administración generado por IA, a menudo encontramos endpoints de lista que devuelven registros completos (incluidos campos de texto grandes) sin límite. La mejora rápida es devolver una forma compacta de “elemento de lista” y pedir los detalles solo cuando alguien abre una fila. Ese cambio por sí solo puede reducir el tiempo de consulta, el tamaño de la respuesta y el tiempo de renderizado del cliente sin tocar el diseño de la UI.
Paginación por cursor en lenguaje llano
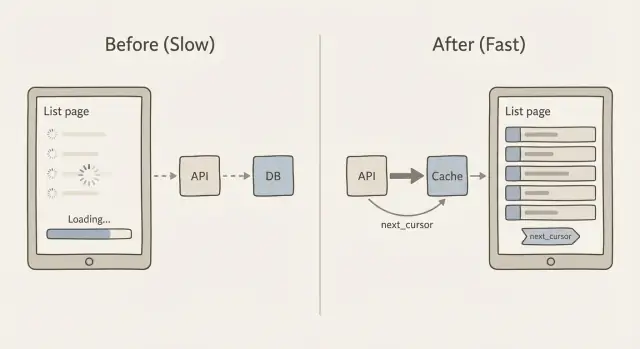
Muchos endpoints de lista empiezan con paginación por offset: “dame la página 3” significa “salta las primeras 40 filas y devuelve las siguientes 20”. Parece simple, pero se vuelve más lento a medida que la tabla crece porque la base de datos aún tiene que recorrer todas las filas saltadas.
La paginación por offset también se vuelve rara cuando los datos cambian mientras alguien está navegando. Si se insertan filas nuevas o se eliminan filas antiguas, la siguiente página puede mostrar duplicados o saltarse elementos. Pediste “página 3”, pero “página 3” no es algo estable.
La paginación por cursor lo arregla usando un marcador en lugar de un número de página. El cliente dice “dame los siguientes 20 elementos después de este último elemento que vi”. Ese valor de “después” es el cursor. Esta es la idea central detrás de caché y paginación para páginas de listas lentas: mantener cada petición pequeña, predecible y rápida.
Qué es realmente el cursor
Un cursor suele ser un pequeño paquete de valores del último registro en la respuesta actual. Para hacerlo estable, tu lista debe tener un orden consistente que nunca empata. Un patrón común es ordenar por created_at con id como desempate (por ejemplo: más recientes primero, y si dos filas comparten la misma marca temporal, ordenar por id).
Ese orden estable importa porque garantiza que “después de este elemento” siempre apunte a exactamente un lugar en la lista.
Cómo funciona next_cursor
Conceptualmente, el servidor devuelve:
- Los elementos de esta petición (por ejemplo, 20)
- Un
next_cursorque representa el último elemento en ese conjunto
Si no hay más elementos, next_cursor está vacío o ausente. El cliente lo almacena y lo envía de vuelta para obtener la siguiente porción. No hay conteo de páginas, no hay saltos enormes y hay muchas menos sorpresas cuando la lista cambia.
Paso a paso: implementar un endpoint API paginado por cursor
La paginación por cursor es el patrón de trabajo detrás de caché y paginación para páginas de listas lentas. Mantiene las páginas estables y rápidas, incluso cuando se añaden filas nuevas.
1) Elige un orden estable
Elige un orden que nunca cambie para una fila dada. Una elección común es created_at desc, id desc. El desempate por id importa cuando muchas filas comparten la misma marca temporal.
2) Define las formas de petición y respuesta
Mantén la petición pequeña y predecible: un limit, un cursor opcional y los filtros que ya soportes (status, owner, búsqueda).
Una forma de respuesta simple se ve así:
{
"items": [/* results */],
"next_cursor": "opaque-token",
"has_more": true
}
3) Codifica y decodifica el cursor de forma segura
No pongas SQL crudo ni un offset de base de datos en el cursor. Hazlo un token opaco que contenga solo lo necesario para reanudar la paginación, como el created_at y id del último elemento.
Un formato práctico es JSON codificado en base64, opcionalmente firmado (para que los clientes no lo manipulen). Ejemplo de payload dentro del token: { "created_at": "2026-01-10T12:34:56Z", "id": 123 }.
4) Consulta usando el cursor (y maneja inserciones)
Con created_at desc, id desc, la consulta para la siguiente página debería traer filas “antes” del cursor:
created_at < cursor_created_atOR (created_at = cursor_created_atANDid < cursor_id)
Esto mantiene la paginación estable incluso si se insertan nuevos elementos en la parte superior mientras el usuario navega.
5) Añade guardarraíles
Establece un límite por defecto (como 25) y un máximo duro (como 100). Valida el cursor, el limit y los filtros. Si el cursor no es válido, devuelve un error 400 claro. En FixMyMess, estos guardarraíles a menudo faltan en endpoints generados por IA, y por eso las páginas de lista fallan bajo tráfico real.
Diseñar claves de caché para respuestas de lista
Cachear páginas de lista parece fácil hasta que recuerdas cuántas “listas diferentes” puede producir tu app. Un endpoint puede soportar búsqueda, filtros, opciones de orden, tamaños de página distintos y paginación por cursor. Si tu clave de caché ignora incluso una de esas entradas, corres el riesgo de mostrar resultados equivocados a la persona equivocada.
Una buena clave de caché es simplemente la huella única de la respuesta exacta de la lista. Incluye todo lo que cambia qué filas aparecen o en qué orden. Normalmente eso significa:
- Ámbito: público vs por usuario vs por organización (y el id real)
- Entradas de consulta: filtros, texto de búsqueda y orden
- Paginación: cursor (o marcador de “primera página”) y limit
- Versión: una etiqueta opcional de esquema o “list-v2” para cambiar formatos con seguridad
Mantén la clave legible. Un patrón simple que funciona bien es:
resource:scope:filters:sort:cursor:limit
Por ejemplo: tickets:org_42:status=open|q=refund:created_desc:cursor=abc123:limit=25. Normaliza las entradas para que diferentes ortografías no creen misses inútiles en la caché (recorta espacios, ordena los parámetros de filtro y usa un separador consistente).
Decide qué vas a cachear. Muchos equipos cachean solo la primera página porque es la más solicitada y se beneficia más de un TTL corto. Cachear cada página también ayuda, pero explota el número de claves y aumenta el trabajo de invalidación cuando los datos cambian.
No cachees cuando es más probable que esté equivocado que útil: listas muy personalizadas (como “recomendado para ti”), listas que cambian cada pocos segundos o listas que incluyen checks de permisos difíciles de codificar con seguridad en la clave.
Si trabajas en caché y paginación para páginas de listas lentas en una app generada por IA, vigila endpoints que tratan el “cursor” como opcional y vuelven a “devolver todo” como comportamiento por defecto. Ese es un fallo común que FixMyMess audita y corrige ajustando los valores por defecto de paginación y haciendo que las claves de caché incluyan el contexto completo de la consulta.
Mantener las listas cacheadas frescas sin complicarlo demasiado
La mayoría de las páginas de lista no necesitan frescura perfecta e instantánea. Necesitan sentirse rápidas y ser “lo suficientemente recientes” para la meta del usuario. Esa es la clave para hacer que la caché y la paginación para páginas de listas lentas funcionen sin convertir la invalidación de caché en un segundo producto.
TTL vs invalidación basada en eventos (en palabras sencillas)
Un TTL (time to live) es la opción más simple: cachea la lista por, digamos, 30-120 segundos y luego actualízala. Es fácil y fiable, pero puede mostrar datos ligeramente antiguos.
La invalidación basada en eventos intenta ser exacta: cuando un registro cambia, borras de inmediato las listas cacheadas afectadas. Puede ser muy fresca, pero se complica porque un cambio puede afectar a muchos filtros y órdenes.
Un término medio práctico es stale while revalidate: sirve la lista cacheada aunque esté un poco antigua y la refresca en segundo plano. Los usuarios obtienen páginas rápidas y la caché se recupera rápidamente tras los cambios.
Invalidación dirigida que siga siendo manejable
En vez de “borrar todo”, invalida solo lo que puedas describir claramente:
- Por usuario o inquilino (solo sus listas)
- Por tipo de recurso (orders vs customers)
- Por grupo de filtros (status=open, tag=vip)
- Por “versión de colección” (un contador que incrementas en escrituras)
Esa última opción suele ser la más simple: incluye collection_version en tu clave de caché. Cuando algo cambia, incrementas la versión y las entradas viejas dejan de usarse.
Los stampedes de caché ocurren cuando muchas peticiones fallan en caché a la vez y todas la reconstruyen. Dos protecciones sencillas ayudan:
- Añadir jitter al TTL (aleatorio +/- 10-20%)
- Coalescencia de peticiones (uno construye, los demás esperan)
- Servir datos stale durante una ventana corta de gracia
Finalmente, decide qué consistencia necesitas realmente. Para la mayoría de páginas de administración y feeds, “las actualizaciones aparecen en 1-2 minutos” está bien. Para movimientos de dinero o permisos, no cachees la lista o mantén un TTL muy corto y valida en la página de detalle.
Patrones de paginación del lado del cliente que se mantienen rápidos
La mayoría de pantallas de lista tienen un patrón de tráfico claro: la gente llega a la página 1 mucho más que a cualquier otra página. Cachea la primera página en el cliente (memoria o local storage) con un TTL corto y muéstrala inmediatamente mientras la refrescas en segundo plano. Esto sola arregla la sensación de “pantalla en blanco” que hace que una lista parezca lenta.
Cuando uses paginación por cursor, trata al cursor como parte de la identidad de la página. Mantén un pequeño mapa como cursor -> rows para que volver atrás no dispare nuevas peticiones y tu UI siga respondiendo incluso con redes inestables.
Prefetch de la siguiente página ayuda, pero solo si se hace con cuidado. Un enfoque seguro es prefetch cuando el usuario está cerca del final (o después de que pause el desplazamiento) y cancelar la petición si cambian filtros u orden.
- Prefetch solo una página adelante
- Debounce del trigger (por ejemplo, 200-400ms)
- Bloquear prefetch mientras ya hay una petición en vuelo
- No prefetch para filtros costosos (como búsqueda de texto completo)
- Detener el prefetch cuando la pestaña está oculta
Los estados de carga importan más de lo que la gente piensa. Usa un indicador de carga “suave” (mantén las filas existentes visibles) y un botón de reintento claro para fallos. En el reintento, añade resultados solo después de confirmar que pertenecen a la misma consulta (mismos filtros, orden y cursor), de lo contrario obtendrás filas duplicadas o mezcladas.
La desduplicación en el cliente es tu red de seguridad. Siempre combina filas por un ID estable (como id), no por índice de array o timestamp. Si recibes la misma fila dos veces, reemplázala en su lugar para que la lista no salte.
El infinite scroll no siempre es mejor. Puede ser peor para pantallas de administración donde la gente necesita saltar, ordenar y comparar. Si los usuarios suelen decir “estaba en la página 7”, usa navegación paginada con tamaño de página claro y reserva el infinite scroll para feeds donde la posición exacta no importa. Esta es una corrección común que aplicamos al reparar UIs generadas por IA que accidentalmente saturan la API y se sienten lentas.
Fundamentos de base de datos y payload que mejoran la caché
La caché ayuda, pero no borra las consultas lentas. Una respuesta de lista cacheada aún tiene que generarse al menos una vez, y los misses de caché ocurren más de lo que la gente espera (nuevos filtros, nuevos usuarios, claves expiradas, despliegues). Si la consulta a la base de datos es inestable, todo el sistema se siente poco fiable.
Los índices son el primer lugar a revisar. Para páginas de lista, el patrón ganador es simple: tu índice debe coincidir con cómo filtras y cómo ordenas. Si tu endpoint hace WHERE status = 'open' y ORDER BY created_at DESC, la base de datos debería tener un camino que soporte ambos.
Una regla práctica para consultas de lista:
- Indexa las columnas que usas en
WHEREmás a menudo. - Incluye la columna por la que ordenas (
ORDER BY) en el mismo índice cuando sea posible. - Si siempre filtras por un tenant o usuario, esa columna suele ir primero.
- Prefiere claves de orden estables (tiempo de creación, id) para que la paginación y la caché sean previsibles.
- Revisa los índices después de añadir filtros nuevos, no meses después.
A continuación: deja de enviar datos extra. Muchas páginas de lista lentas son lentas porque mueven demasiado JSON, no porque la base de datos esté muriendo. Evita SELECT *. Elige los campos que realmente muestras en la tabla. Si la UI solo necesita id, name, status y updated_at, devuelve solo esos. Obtienes consultas más rápidas, payloads más pequeños y mayores tasas de acierto en caché porque las respuestas son más baratas de almacenar y servir.
Ten cuidado con ordenar por campos calculados, como "full_name" (first + last), "last_activity" desde un subquery o "relevance" de una fórmula personalizada. Estos a menudo fuerzan escaneos, planes con muchos joins o ordenar grandes conjuntos en memoria. Cuando puedas, precalcula el valor en una columna real o ordena por un campo más simple y calcula el valor complejo en la UI.
Antes de afinar más, mide dos números:
- Tiempo de consulta (p50 y p95, no solo una ejecución).
- Tamaño del payload para una sola página.
- Filas examinadas vs filas devueltas.
- Tasa de acierto de caché para el endpoint de lista.
- El filtro+orden más lento que realmente usa la gente.
Esto es especialmente común en apps generadas por IA que vemos en FixMyMess: los endpoints de lista “funcionan” en una demo, pero una vez llegan datos reales, la falta de índices y los payloads sobredimensionados hacen que las cachés parezcan “no funcionar”. Arregla lo básico primero y luego la caché será un multiplicador en lugar de un parche.
Ejemplo: arreglar una página de administración lenta en una app en crecimiento
Una historia común: un dashboard de administración empezó como un prototipo generado por IA. Funcionaba con 200 filas. Seis meses después tiene 200.000 y la lista de “Users” caduca o tarda 10-20 segundos en cargar. La gente refresca, los filtros se sienten aleatorios y la CPU de la base de datos se dispara.
La versión mala suele ser así: el cliente llama a un endpoint que devuelve todo (o usa paginación por offset con offsets enormes), la respuesta incluye campos pesados (perfiles, settings, historial de auditoría) y cada scroll dispara otra consulta costosa. No hay caché, así que la misma primera página se recalcula para cada administrador.
Aquí hay una solución práctica para caché y paginación para páginas de listas lentas que mantiene el comportamiento predecible.
Qué cambiamos
Mantenemos la UI igual, pero cambiamos el contrato de la API:
- Usar paginación por cursor: devolver
items,nextCursory pedir siempre conlimit. - Ordenar por una clave estable (por ejemplo,
created_atmásid) para que los cursores no salten ni repitan. - Cachear solo la primera página para vistas comunes (como “All users, newest first”), porque esa página es la más solicitada.
- Restringir filtros a campos seguros e indexados (status, role, fecha de creación). Rechazar búsquedas "contains" en columnas de texto grandes a menos que tengas soporte de búsqueda.
- Reducir el payload: la lista devuelve solo lo que la tabla necesita. Los detalles cargan en la página de usuario.
Una forma de respuesta simple:
{ "items": [{"id": "u_1", "email": "[email protected]", "createdAt": "..."}], "nextCursor": "createdAt:id" }
Qué notaron los admins
La primera pantalla aparece rápido y el desplazamiento se mantiene estable porque cada petición está acotada. Refrescar la lista deja de golpear la base de datos porque la primera página viene de caché. Los filtros se sienten consistentes porque el orden y las reglas de cursor son claros.
Para desplegarlo de forma segura, publica el nuevo endpoint detrás de un feature flag para admins internos primero, compara resultados lado a lado y registra errores de cursor (duplicados, filas faltantes). Si heredaste un prototipo roto de herramientas como Bolt o Replit, equipos como FixMyMess suelen empezar con una auditoría rápida para encontrar los endpoints “devuelven todo” y las consultas que hay que arreglar primero.
Errores comunes y trampas a vigilar
La mayoría de las soluciones para páginas lentas fallan por razones sencillas: la paginación es poco fiable, la caché es insegura o el endpoint puede ser abusado. Si trabajas en caché y paginación para páginas de listas lentas, estos son los tropiezos que causan más problemas luego.
La paginación por offset es la trampa clásica. Parece bien con datos pequeños, pero si ordenas por un campo no único (como created_at), las filas nuevas pueden colarse en la mitad mientras un usuario navega. Eso crea duplicados, elementos faltantes o una página que “brinca”. La paginación por cursor evita esto, pero solo si tu orden es estable (por ejemplo: created_at más un id único como desempate).
Los propios cursores pueden ser un problema de seguridad y corrección. Si pones IDs crudos, fragmentos SQL o expresiones de filtro dentro del cursor, arriesgas que usuarios adivinen valores, rompan la decodificación o forcen consultas costosas. Un patrón más seguro es: codifica solo los últimos valores de orden vistos y luego valídelos en el servidor antes de consultar.
La caché introduce otra clase de errores. El más grande es olvidar el scope. Si tu clave de caché no incluye usuario, tenant, rol y filtros, puedes filtrar datos entre cuentas. También vigila la historia de “frescura”: los cambios de estado y las eliminaciones son lo primero que los usuarios notan cuando las listas cacheadas se quedan atrás.
Un ejemplo rápido: una página admin “Orders” muestra órdenes pagadas y pendientes. Si la clave de caché ignora el filtro status=pending, un admin puede ver una lista mezclada que parece incorrecta, y la caché incluso puede compartirse con vistas no-admin.
Aquí hay cinco guardarraíles que previenen la mayoría de incidentes:
- Siempre añade un max
limity hazlo cumplir en el servidor. - Usa un orden estable con desempate único.
- Haz los cursores opacos y valida los valores decodificados.
- Construye claves de caché a partir de scope de usuario + filtros + orden + tamaño de página.
- Decide cuánto dato stale es aceptable y luego invalida o acorta el TTL para listas de alta frecuencia de cambio.
Si heredaste una app generada por IA con paginación inestable, claves de caché inseguras o endpoints de lista sin límite, FixMyMess puede auditar la ruta de código y señalar los modos de fallo exactos antes de que los despliegues los expongan.
Lista rápida de verificación y próximos pasos
Usa esto como repaso final cuando mejores caché y paginación para páginas de listas lentas. Los pequeños detalles deciden si tu lista se mantiene rápida en 1.000 filas y en 10 millones.
Construirlo de forma segura (API y caché)
- Fija un tope máximo (y un valor por defecto sensato) para que nadie solicite 50.000 filas por accidente.
- Usa un orden estable (por ejemplo, created_at + id) para que la paginación no reordene los elementos entre peticiones.
- Mantén el cursor opaco. Trátalo como un token, no como algo que el cliente edite.
- Confirma que la consulta usa índices que coincidan con tus filtros y orden.
- Scopea las claves de caché a lo que cambia la respuesta: usuario o tenant, filtros, orden, tamaño de página y cursor.
La caché funciona mejor cuando la primera página es fácil de reutilizar, así que empieza por ahí. Escoge un TTL que coincida con la frecuencia de cambio real de la lista y añade protección básica contra stampedes (lock, coalescencia de peticiones o servir stale mientras revalida) para que picos de tráfico no fundan tu base de datos.
Probar que funciona (tests y operaciones)
- Crea items nuevos mientras navegas y confirma que no ves duplicados ni filas faltantes.
- Cambia filtros en medio del scroll y confirma que el cliente reinicia el estado en lugar de mezclar páginas viejas y nuevas.
- Simula una red lenta y verifica que el cliente desduplica resultados e ignora respuestas fuera de orden.
- Monitoriza tiempo de consulta, tasa de acierto de caché, tasa de errores y tamaño del payload tras el lanzamiento.
- Registra los endpoints de lista más lentos con sus filtros para que puedas atacar a los verdaderos culpables.
Próximos pasos: si tu prototipo generado por IA tiene endpoints de lista lentos o rotos, FixMyMess puede hacer una auditoría de código gratuita para localizar problemas de paginación, caché y seguridad antes de que los lances.