Plan de reconstrucción por fases: empezar por la ruta crítica
Aprende un plan de reconstrucción por fases que empieza por la ruta crítica, demuestra estabilidad y luego añade funciones secundarias sin romper producción.
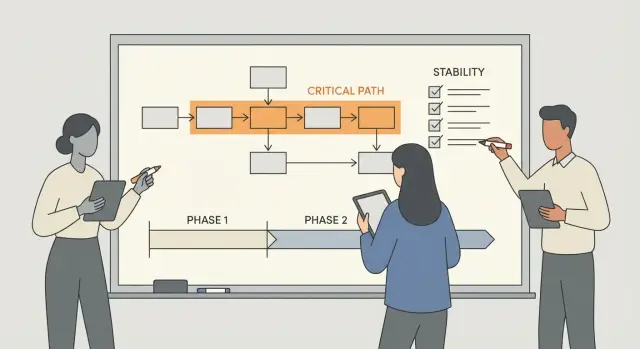
Qué es una reconstrucción por fases y por qué importa
Un plan de reconstrucción por fases significa rehacer tu app en pequeños bloques planificados en lugar de intentar arreglarlo todo a la vez. Empiezas por lo que debe funcionar para que el producto sea usable, y luego añades el resto solo después de que el núcleo esté estable.
Lanzar todas las funciones en un gran empujón suele fallar por una razón simple: no puedes saber qué cambio causó qué problema. Los bugs se multiplican, las fechas se retrasan y el equipo termina apagando incendios en lugar de avanzar.
Los prototipos generados por IA suben las apuestas. A menudo parecen completos, pero por dentro pueden estar desordenados: flujo de datos poco claro, lógica copiada, falta de manejo de errores y defaults riesgosos como secretos expuestos o autenticación débil. Si apilas nuevas funciones encima de eso, puedes acabar recontruyendo las mismas partes una y otra vez.
La idea clave es la ruta crítica. Es el conjunto más corto de pasos que un usuario real debe completar para obtener el valor principal de tu producto, sin soluciones alternativas.
Una forma simple de detectarla es describir la app en una frase y luego listar los pasos que un usuario primerizo realiza para alcanzar ese resultado. Para muchos productos, la ruta crítica incluye piezas previsibles: registrarse o iniciar sesión, realizar la acción central (crear una reserva, subir un archivo, hacer un pedido), completar el “momento de valor” (pagar, enviar, confirmar), luego ver el resultado y volver más tarde sin perder datos.
Todo lo demás es secundario hasta que este camino sea seguro y fiable. Si una app pequeña permite a los usuarios reservar una cita, la ruta crítica es acceso a la cuenta, horarios disponibles, creación de la reserva, confirmación y un registro guardado. Filtros avanzados, paneles de admin y plantillas de email pueden esperar hasta que el flujo de reservas funcione siempre.
Los equipos que reparan apps creadas por IA suelen descubrir que enfocarse primero en la ruta crítica reduce rehacer trabajo, simplifica las pruebas y convierte un prototipo roto en algo en lo que puedes confiar en producción.
Encuentra tu ruta crítica antes de tocar el código
Un plan por fases empieza con una pregunta simple: ¿cuál es el objetivo del usuario que debe funcionar siempre?
Escribe ese objetivo desde el punto de vista del usuario. Ejemplos: “Registrarme y crear mi primer proyecto”, “Reservar y pagar una cita” o “Importar un archivo y obtener un informe”. Elige el que impulsa el negocio. Todo lo demás es opcional hasta que este camino sea sólido.
A continuación, mapea los pasos mínimos desde el primer contacto hasta el éxito. Mantenlo aburrido y directo. No estás diseñando la experiencia perfecta todavía; estás eligiendo lo que no debe fallar. Típicamente eso significa: punto de entrada hasta la primera acción, creación de cuenta o inicio de sesión, la acción central, el paso irreversible (pago o escritura de datos) y luego la confirmación.
Luego lista las dependencias bajo esos pasos. Aquí es donde los prototipos creados por IA suelen esconder el riesgo real: auth pegada con marcadores, pagos en “modo test”, escrituras sin validación y correos que filtran secretos o nunca se envían.
Finalmente, acuerda qué queda fuera del alcance de la fase 1 y escríbelo. Para una app pequeña, eso puede significar login social, dashboards de admin, analítica, exportaciones, roles de equipo y onboarding avanzado.
Ejemplo concreto: si el valor principal de tu app es “los usuarios pagan y luego generan un documento”, la ruta crítica no es “hacer el dashboard bonito”. Es pago, generación del documento y guardar el resultado. Si eso está estable, las funciones de la fase 2 tienen un lugar seguro donde aterrizar.
Establece una línea base de estabilidad que puedas medir
Antes de reconstruir nada, anota qué significa “roto” hoy. Si omites esto, la fase 1 puede parecer mejor mientras sigue fallando en los mismos puntos.
Empieza por listar las fallas que ya ves en uso real. Las comunes en apps creadas por IA son inicios de sesión que fallan al azar, crashes con ciertas entradas, pagos que no se completan, datos que desaparecen tras un refresh y páginas que tardan tanto que los usuarios se rinden.
A continuación, captura el dolor del usuario en lenguaje llano. Busca los momentos donde la gente abandona: la pantalla que dejan, la acción que reintentan o el paso donde se acumulan las solicitudes de soporte. Un enfoque rápido es recopilar 10–20 mensajes o reportes recientes y etiquetar cada uno por dónde ocurrió (registro, checkout, subida, dashboard).
Ahora define “estable” usando un pequeño conjunto de señales que puedas comprobar a diario. Manténlo en 3–5 y hazlas medibles. Por ejemplo: tasa de éxito de inicio de sesión, sesiones sin crashes, integridad de datos en acciones clave, rendimiento en pantallas críticas y carga de soporte ligada a fallos del núcleo.
Elige una ventana de tiempo corta para medir la línea base, normalmente 3–7 días. Lo bastante larga para evitar la ilusión de “buen día”, lo bastante corta para no bloquearte.
Alcance de la Fase 1: haz que el núcleo sea seguro y fiable
La Fase 1 no se trata de impresionar. Se trata de hacer el núcleo confiable. Si tu plan empieza puliendo pantallas secundarias, puedes acabar con una app más bonita que sigue fallando cuando los usuarios reales inician sesión, pagan o guardan datos.
Una buena regla: elige el conjunto más pequeño de funciones que el negocio necesita para funcionar y haz que ese camino sea seguro. Todo lo demás espera.
Qué pertenece a la Fase 1
Empieza por los básicos de seguridad que pueden romperlo todo silenciosamente más adelante. Elimina secretos expuestos, refuerza la autenticación y valida cada entrada controlada por el usuario antes de que llegue a tu base de datos o APIs. Muchos prototipos generados por IA filtran claves, omiten comprobaciones o aceptan entradas inseguras.
A continuación, estabiliza el modelo de datos y los flujos que más lo tocan. Si la app no puede crear, leer, actualizar y borrar los registros clave de forma fiable, añadir funciones solo suma confusión. Mantén reglas simples y consistentes para que la misma acción siempre produzca el mismo resultado.
Haz los problemas visibles. Añade logs claros para la ruta crítica y captura errores con suficiente detalle para reproducirlos. Sin esto, seguirás adivinando cuando algo se rompa.
Finalmente, haz que el envío sea aburrido. Quieres un modo claro de desplegar, con los mismos pasos cada vez, para que los arreglos no se pierdan entre máquinas o entornos.
Lista rápida de la Fase 1
“Seguro y fiable” normalmente significa:
- Los secretos se han sacado del código y se rotan cuando es necesario
- La autenticación es correcta para los roles principales y las sesiones se comportan de forma predecible
- Las entradas críticas están validadas y las rutas comunes de inyección están bloqueadas
- Los flujos core pasan pruebas repetibles y son fáciles de observar en logs
- Los despliegues son repetibles y producen el mismo resultado cada vez
Paso a paso: reconstruye la ruta crítica
Reconstruye el flujo principal del usuario como un único camino simple de inicio a fin. Esto evita que tu plan por fases se trague con funciones que no son necesarias.
1) Recrea el flujo de extremo a extremo (la versión más simple)
Elige un resultado de éxito y construye solo lo que necesita. Si una pantalla, ajuste o integración no es necesaria para ese resultado, déjala fuera por ahora.
Escribe el flujo en 5–8 pasos en lenguaje llano (qué hace el usuario, qué guarda el sistema, qué ven después). Implementa la versión mínima con UI básica, API básica y acciones de base de datos básicas. Simula integraciones no críticas (usa un pago sandbox, envía un email de prueba o registra el evento) y haz que las fallas sean obvias con errores claros y estados de carga. Luego ejecuta el flujo manualmente varias veces con datos realistas para atrapar fallos evidentes.
2) Añade pruebas solo donde la rotura dolería
No necesitas cobertura completa todavía. Añade un pequeño conjunto de pruebas que protejan la ruta central de regresiones: una que inicie sesión, otra que complete la acción principal y otra que confirme que los datos se guardaron correctamente. Incluso estas pruebas básicas pueden evitar sorpresas del tipo “ayer funcionaba”.
3) Arregla una clase de fallos a la vez
Los bugs vienen en racimos. Agrupa los problemas por tipo y soluciónalos por lotes para no rebotar entre arreglos. Lotes comunes son autenticación (sesiones, redirecciones), integridad de datos (restricciones, migraciones) y pagos (webhooks, idempotencia). Mantén cada cambio lo bastante pequeño para revisarlo y despliega frecuentemente.
Ejemplo: una reconstrucción por fases realista para una app pequeña
Imagina una mini SaaS que ayuda a un responsable de marketing a subir un CSV, etiquetar leads y generar un primer informe simple (segmentos principales y recuentos). El prototipo generado por IA se ve bien, pero los registros fallan aleatoriamente, los permisos son inconsistentes y los datos a veces desaparecen tras un refresh.
Aquí tienes un plan por fases que mantiene el negocio en marcha mientras reduces el riesgo.
Fase 1: hacer el núcleo seguro y aburrido (en el buen sentido)
Empieza desde el registro hasta el primer informe y trata todo lo demás como opcional.
- Registro e inicio de sesión fiables (sesiones consistentes, restablecimiento de contraseña funciona, sin secretos expuestos)
- Permisos que reflejen la realidad (los usuarios no ven los datos de otros, los datos de demo están separados)
- Guardado y carga fiables (subida, etiquetas e inputs del informe persisten siempre)
- UI básica (pantallas simples y estables sin botones medio funcionales)
Una buena prueba: ¿pueden cinco personas distintas ir de “crear cuenta” a “primer informe” sin ayuda, dos veces seguidas?
Fase 2: añadir funciones que ayuden al uso diario por equipos
Construye sobre la base estable: invitaciones de equipo, exportaciones e una o dos integraciones (por ejemplo, enviar leads etiquetados a un CRM). Cada adición debe evitar reescribir el flujo core.
Fase 3: pulir y funciones avanzadas
Una vez que la app sea estable en uso real, añade dashboards de analítica, más roles, ajustes avanzados y otras mejoras.
Trampas comunes que ralentizan una reconstrucción por fases
Una reconstrucción por fases solo funciona cuando cada fase tiene una línea de final clara. La mayoría de retrasos ocurren cuando el equipo se mantiene ocupado en vez de lograr que la app haga una cosa de forma fiable de extremo a extremo.
Un error común es limpiar todo antes de que la app funcione. Los refactors pueden ser útiles, pero si el login, el checkout o el guardado de datos siguen fallando, no tienes una base sólida sobre la que construir. Código ordenado es un plus, no el primer hito.
Otra trampa es rehacer la UI mientras la lógica core sigue rota. Una pantalla más bonita puede ocultar que el sistema debajo está fallando. Si los usuarios no pueden completar el flujo principal sin errores, el pulido visual solo aumenta el rehacer después.
El progreso también se descarrila añadiendo funciones para demostrar impulso. Un filtro nuevo, un dashboard o una integración queda bien en demo, pero añade estados y casos borde. Eso hace que confirmar la estabilidad sea más difícil, lo que derrota el propósito de reconstruir en fases.
La trampa más cara es mantener la misma arquitectura enmarañada y esperar que escale. Si el código generado por IA mezcla UI, reglas de negocio y llamadas a base de datos en un mismo lugar, cada cambio rompe otra cosa. Una pequeña reestructuración dirigida temprano puede ahorrar semanas luego.
Atento a estas señales de advertencia:
- Los pull requests tocan archivos no relacionados con “ya que estamos aquí”
- Los bugs reaparecen después de marcarse como arreglados
- No puedes explicar el flujo principal en 5 pasos
- Las pruebas se saltan porque “toman demasiado tiempo”
Comprobaciones rápidas antes de añadir funciones secundarias
Las funciones secundarias parecen seguras porque son “solo UI” o “agradables de tener”. Pero si las añades antes de que el núcleo sea verdaderamente estable, a menudo reabren los mismos bugs que acabas de arreglar. Trata el final de la Fase 1 como una puerta que debes pasar.
Lista de salida de la Fase 1
Ejecuta estas comprobaciones solo en la ruta crítica (registro, login, pago, flujo core, lo que tu app no puede vivir sin):
- Rendimiento: mide la carga de páginas y los pasos más lentos en el flujo core. Busca desperdicio obvio como consultas repetidas, payloads grandes o endpoints que hacen trabajo extra “por si acaso”.
- Seguridad: confirma que no hay secretos en el repo ni en el frontend. Verifica el control de acceso con algunas pruebas reales. Re-revisa riesgos comunes de inyección y subidas inseguras.
- Fiabilidad: añade timeouts en llamadas externas, establece reintentos sensatos (no infinitos) y haz que las fallas sean manejadas con gracia (errores claros, no pantallas en blanco).
- Preparación para release: asegúrate de poder desplegar con seguridad, monitorizar errores clave y hacer rollback.
- Puerta de decisión: escribe los criterios de aprobación que aceptarás (por ejemplo, “login funciona 100 veces seguidas” y “sin hallazgos de seguridad de alta gravedad”). Si no puedes decirlo en una frase, no estás listo.
Si tu app generada por IA desconecta usuarios al azar, no añadas un widget nuevo al dashboard todavía. Primero prueba que las sesiones son estables en uso real y luego avanza.
Evita que la Fase 2 vuelva a romper la Fase 1
La Fase 1 es donde ganas confianza: la app corre, el flujo core funciona y los bugs críticos dejan de aparecer. La Fase 2 es donde los equipos suelen deshacer ese progreso añadiendo “solo una función más” que se cuela en el núcleo.
Una barrera práctica es una separación clara entre el dominio core (la ruta crítica) y las funciones opcionales. Trata el núcleo como un pequeño producto dentro de tu producto. Las funciones pueden llamarlo, pero no deben reescribirlo.
Pon un límite claro alrededor del núcleo
Haz evidente en el código qué es core y qué es opcional. Si una nueva función necesita algo del core, añádelo mediante una pequeña interfaz en lugar de acceder a la lógica interna.
Por ejemplo, si tu ruta crítica es registro -> login -> checkout, una función de códigos promocionales no debería editar las reglas de checkout por todos lados. Debe enviar la solicitud de promo a una interfaz de checkout que valide entradas y aplique descuentos en un punto controlado.
Chequeo rápido de límites:
- El flujo core tiene su propio módulo o carpeta, con pruebas
- El código de funciones no puede importar internals del core directamente
- Código compartido se mantiene pequeño (validación, tipos, utilidades)
- Los cambios de datos pasan por un servicio core, no por consultas dispersas
Mantén visibles las decisiones y normas estrictas
Anota brevemente las decisiones mientras están frescas: qué cambió, por qué y qué no hacer. Una nota corta puede ahorrar horas después, especialmente cuando la intención no queda clara.
Establece reglas para el trabajo nuevo para que el desorden no vuelva:
- No hay merges de funciones sin pasar las pruebas de la Fase 1
- Los nuevos campos de base de datos incluyen un plan de rollback
- Los secretos nunca van al repo, ni siquiera “temporalmente”
- Cualquier cambio en el core necesita una segunda revisión
- Si una función necesita 3+ ediciones en el core, para y rediseña la interfaz
Planifica las funciones secundarias una vez probada la estabilidad
Un plan por fases solo funciona si la Fase 1 se mantiene protegida. Antes de añadir cualquier cosa nueva, asegúrate de que el flujo core sea aburrido en el mejor sentido: se ejecuta igual cada vez, los errores son previsibles y los arreglos no crean nuevas sorpresas.
Al decidir qué pertenece a la Fase 2 o posteriores, separa “agradable de tener” de “necesario para mantener el servicio”. Si una función no es requerida para la ruta crítica, debe competir por espacio en la Fase 2.
Una forma simple de ordenar funciones es puntuar cada una por valor de usuario frente a riesgo para la estabilidad. Considera cuántos usuarios la necesitan ahora, si toca auth/pagos/permisos/modelos de datos, qué tan grande es el cambio, cuántas incógnitas quedan y qué carga de soporte crea.
Entrega funciones secundarias en releases pequeñas y luego escucha. Un lote estrecho con feedback vale más que cinco funciones que nadie usa.
Después de cada lote, reserva tiempo de endurecimiento para que la Fase 1 no se vuelva a romper: ejecuta una regresión corta en la ruta crítica, arregla rendimiento y manejo de errores antes del siguiente feature, elimina flags temporales, revisa básicos de seguridad y actualiza la monitorización para que los problemas aparezcan temprano.
Próximos pasos: ten un plan por fases claro para tu app generada por IA
Si tu app fue generada con herramientas como Lovable, Bolt, v0, Cursor o Replit, el camino más rápido suele ser un plan por fases que proteja primero la jornada central del usuario y evite apilar funciones sobre código tambaleante.
Antes de pedir ayuda, lleva un pack inicial pequeño para que alguien vea qué es real rápido: acceso al repo (o una copia zip) y detalles del entorno, los pasos de la ruta crítica que el usuario debe completar, logs recientes o capturas de fallos, cualquier clave que pueda haber estado expuesta y tu objetivo de éxito para la Fase 1.
A veces una reparación focalizada es suficiente. Otras veces reconstruir es más rápido que parchear. Las reparaciones suelen ganar cuando la estructura core es sólida y los bugs están aislados. Las reconstrucciones suelen ganar cuando ves problemas repetidos como módulos enmarañados, modelos de datos inconsistentes o problemas de seguridad que reaparecen.
Si heredaste una base de código generada por IA que no aguanta en producción, FixMyMess puede empezar con una auditoría de código gratuita para identificar qué rompe la ruta crítica y luego centrarse en reparar lógica, endurecer seguridad, refactorizar los puntos más críticos y preparar el despliegue. Eso te da un alcance de Fase 1 concreto en el que confiar antes de invertir en las funciones de la Fase 2.
Preguntas Frecuentes
¿Qué es exactamente una reconstrucción por fases?
Una reconstrucción por fases consiste en rehacer tu app en pequeñas partes planificadas, empezando por la única ruta de usuario que debe funcionar siempre. Te ayuda a evitar el caos de cambiar “todo a la vez”, para que puedas desplegar arreglos, ver qué mejoró y mantener el producto usable mientras lo estabilizas.
¿A qué te refieres con “ruta crítica”?
La ruta crítica es el conjunto mínimo de pasos que un usuario real debe completar para obtener el valor principal de tu producto sin soluciones alternativas. Si esa ruta es estable, puedes añadir funciones secundarias después sin romper continuamente la app.
¿Cómo encuentro rápidamente la ruta crítica de mi app?
Escribe el valor de la app en una frase, luego enumera lo que hace un usuario primerizo para lograrlo. Manténlo en los pasos mínimos desde la entrada hasta el éxito, incluyendo el momento irreversible como un pago o una escritura en la base de datos, y una confirmación que pruebe que funcionó.
¿Por qué los prototipos generados por IA suelen fallar al intentar llevarlos a producción?
Los prototipos generados por IA a menudo parecen completos pero ocultan internals frágiles como lógica copiada, validación ausente y flujo de datos poco claro. Si añades funciones encima, terminas rehaciendo las mismas partes porque el núcleo no es confiable todavía.
¿Cómo establezco una línea base de estabilidad antes de reconstruir?
Define “roto” en términos sencillos según lo que los usuarios realmente experimentan, y mídelo durante un periodo corto (3–7 días). Elige unas pocas señales que puedas revisar a diario, como si el inicio de sesión funciona de forma fiable, si los registros clave persisten tras un refresh y si las pantallas críticas se bloquean o agotan el tiempo.
¿Qué debería incluir el alcance de la Fase 1 (y qué debería esperar)?
La Fase 1 debe incluir solo lo que hace que la ruta central sea segura y fiable: limpieza básica de seguridad, autenticación confiable, permisos correctos, entradas validadas, guardados consistentes y suficiente logging para ver fallos con claridad. Si no ayuda a completar el flujo principal de extremo a extremo, normalmente pertenece a fases posteriores.
¿Cuál es la forma más segura de reconstruir la ruta crítica sin distraerse?
Empieza implementando la versión más simple y completa del flujo crítico, aunque la UI sea básica. Luego añade un pequeño conjunto de pruebas que protejan ese flujo y soluciona problemas por lotes (auth, integridad de datos, pagos) para evitar cambiar de un bug a otro sin avanzar.
¿Cómo evito que las funciones de la Fase 2 vuelvan a romper la Fase 1?
Trata la Fase 1 como un núcleo protegido y añade nuevas funciones a través de una pequeña interfaz en vez de tocar la lógica interna por todas partes. Mantén las pruebas del núcleo como puerta para los merges y ejecuta una regresión corta en la ruta crítica tras cada conjunto de funciones para que la estabilidad no caiga en silencio.
¿Cuáles son los errores más comunes que ralentizan una reconstrucción por fases?
Refactorizaciones exhaustivas y pulir la UI pueden parecer productivos, pero no sirven si los usuarios siguen sin poder iniciar sesión, pagar o guardar datos de forma fiable. Otro error común es añadir “una función más” para mostrar progreso, lo que introduce estados y casos límite antes de confirmar la estabilidad del núcleo.
Herité una app generada por IA que no aguantará en producción—¿qué debo hacer primero?
Si no eres técnico, empieza escribiendo los pasos de la ruta crítica, reuniendo algunos ejemplos recientes de fallos (capturas o logs) y listando claves que puedan haber estado expuestas. FixMyMess puede hacer una auditoría de código gratuita para identificar qué está rompiendo la ruta crítica; normalmente entregamos reparaciones enfocadas y preparación para despliegue en 48–72 horas, o aconsejamos cuando es más rápido reconstruir que parchear.