Redimensionado de imágenes sin tiempos de espera: workers y miniaturas seguras
Aprende a redimensionar imágenes sin timeouts delegando trabajo a workers en segundo plano, limitando dimensiones y guardando los originales por separado para subidas más seguras y rápidas.
Por qué las subidas de imágenes agotan el tiempo en primer lugar
Cuando una subida de imagen agota el tiempo, los usuarios suelen ver un spinner que nunca termina, seguido de un vago mensaje de “Subida fallida”. A veces la subida técnicamente tiene éxito, pero la página se queda congelada mientras el servidor intenta terminar de procesar la foto.
La razón más común es sencilla: la misma petición que recibe el archivo también intenta hacer todo el trabajo pesado. Subir ya es más lento que una llamada API normal porque estás moviendo muchos datos por la red. Si además redimensionas la imagen, generas múltiples miniaturas, la comprimes y escribes todo en almacenamiento antes de responder, dependes de que todo eso termine antes de que venza el tiempo de espera.
Redimensionar durante la petición de subida es impredecible. Una foto que parece normal puede ser enorme (alta resolución, conversión de formato, metadatos extra). Las librerías de imagen también pueden disparar el uso de CPU y memoria. Una imagen “mala” puede alargar una petición, y bajo carga puede ralentizar otras peticiones también.
La situación empeora cuando la gente sube desde redes móviles, carga varias imágenes a la vez, o hay picos de tráfico y tu servidor tiene menos ciclos de CPU libres.
Una solución confiable es el enfoque “original + derivados”: guarda el original rápidamente, devuelve éxito y crea las versiones redimensionadas después. Esas versiones (miniaturas, vistas previas) son derivados porque puedes recrearlas en cualquier momento a partir del original.
Si quieres que las subidas sean fiables, trata el endpoint de subida como un paso rápido de entrada, no como un laboratorio fotográfico. Todo lo que pueda hacerse después, hazlo después.
Por qué el redimensionado y las miniaturas son tan costosos
Redimensionar no es solo “guardar un archivo”. Es trabajo de CPU: decodificar una imagen grande, mantener píxeles en memoria, transformarlos y luego codificar un nuevo archivo. Si haces eso durante una petición web, compites con todo lo demás que la petición debe hacer, como comprobaciones de autenticación, escrituras en la base de datos y operaciones de almacenamiento.
Las fotos modernas de móvil son grandes incluso cuando parecen normales en pantalla. Una imagen de 12 MP son aproximadamente 4000 x 3000 píxeles. Para redimensionarla, el servidor a menudo la expande primero a píxeles crudos, lo que puede usar temporalmente decenas de megabytes por imagen. Con múltiples subidas concurrentes, esos picos se suman rápido.
La configuración frágil es cuando una petición intenta hacerlo todo: aceptar la subida, validarla, redimensionarla, generar miniaturas, convertir formatos y guardar metadatos. Cualquier pequeña ralentización (CPU ocupada, almacenamiento más lento, un fallo transitorio de red) puede empujar la petición más allá del timeout.
El trabajo también se multiplica cuando creas muchos tamaños. Una subida se convierte en varios ciclos decodificar–redimensionar–codificar más múltiples escrituras a almacenamiento. Incluso si cada paso tarda uno o dos segundos, puede abrumar un servidor pequeño con tráfico real.
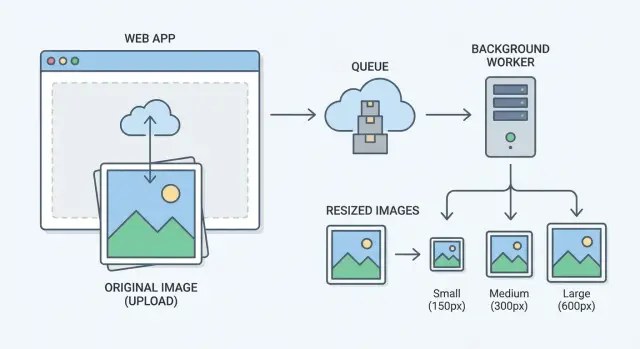
Una arquitectura simple y fiable: originales + workers en segundo plano
La forma más rápida de evitar timeouts en subidas es hacer que las subidas sean aburridas. Tu endpoint de subida debe hacer un trabajo: aceptar el archivo, guardar el original y devolver rápido. El redimensionado, la compresión y la generación de miniaturas deben ocurrir después.
Un esquema simple se ve así:
- El servicio de subida valida el archivo y guarda el original de inmediato.
- Una cola de trabajos registra “hacer miniaturas para la imagen 123” para que el trabajo no se pierda bajo carga.
- Workers en segundo plano toman jobs y generan las versiones redimensionadas.
- Los originales se almacenan por separado de las miniaturas y otros derivados.
- El cliente muestra un marcador hasta que la miniatura esté lista.
Esto convierte “sin timeouts” de una promesa frágil en un resultado natural. La petición de subida se mantiene pequeña y predecible, mientras que los workers manejan el trabajo pesado en su propio horario.
Aún puedes mantener la sensación de rapidez. Después de la subida, la API devuelve un ID de imagen y un estado como “processing”. La app renderiza la entrada con un placeholder temporal y sustituye la miniatura real cuando el worker termina. En el backend, el worker actualiza una bandera de estado (o escribe metadata junto al derivado) para que la app sepa que está lista.
Un ejemplo realista: alguien sube una foto de 12 MB desde un teléfono en Wi‑Fi lento. Si el servidor intenta redimensionar durante la petición, la conexión puede caerse y el usuario reintenta, creando duplicados. Con una cola y workers, la subida se completa, el original está a salvo y el redimensionado puede tardar de 5 a 20 segundos sin bloquear al usuario.
Paso a paso: implementar generación de miniaturas offloaded
Separa dos preocupaciones: subidas rápidas para usuarios y trabajo de imagen más lento para tu sistema. El objetivo es mantener la petición de subida pequeña y predecible.
1) Maneja la subida rápido
Valida el archivo inmediatamente: tipo MIME, tamaño de archivo y dimensiones básicas. Si falla, recházalo antes de almacenar nada. Mantén estas validaciones estrictas para que una foto sobredimensionada u otro formato extraño no pase y colapse pasos posteriores.
Tras la validación, almacena la imagen original tal cual. Crea un registro de imagen (un ID) y márcalo como “original guardado” o “processing”. No redimensiones durante la petición.
2) Crea un job en segundo plano
Una vez almacenado el original, encola un job con solo lo que el worker necesita: el ID de imagen y los tamaños objetivo.
Un flujo limpio es:
- La petición de subida valida y guarda el archivo original.
- La app escribe una fila de imagen con estado como “processing”.
- La app encola un job con
{image_id, sizes}. - Un worker carga el original, genera miniaturas y guarda cada derivado.
- El worker actualiza el estado a “ready” (o “failed” con un error).
3) Sirve el mejor tamaño disponible
Cuando la página carga, sirve la miniatura más pequeña que aún se vea bien para esa pantalla. Si la miniatura no está lista, muestra un placeholder (o, si debes, usa temporalmente el original) y vuelve a intentarlo más tarde.
Asegúrate de que la UI maneje estados parciales con gracia. Una subida puede tener éxito mientras las miniaturas siguen procesándose. La app debe mostrar algo estable en lugar de girar para siempre.
Limita dimensiones y estandariza tamaños para controlar la carga
Una subida sobredimensionada puede causar más problemas que cien fotos normales. Una imagen de 12.000 x 9.000 obliga a tu servidor a decodificar un búfer enorme, redimensionarlo y volver a codificarlo.
Fija un ancho y alto máximo para cualquier derivado que generes, incluso para vistas “grandes”. Mantén el original separado para no perder datos, pero no dejes que el original determine tu coste de procesamiento.
Elige pocos tamaños y reglas claras
Escoge un pequeño conjunto de tamaños estándar para que puedas caché, reutilizar y predecir la carga. Por ejemplo:
- Small: 320 px de ancho (feeds, listas)
- Medium: 800 px de ancho (páginas de detalle)
- Large: 1600 px de ancho (lightbox)
Decide cuándo recortar vs ajustar y aplícalo de forma consistente. El recorte funciona mejor para rejillas (avatares, tarjetas de producto). Ajustar dentro de límites funciona mejor cuando la imagen completa importa.
La calidad y la configuración de formato también afectan el tiempo de CPU. Calidad demasiado alta puede duplicar el tiempo de codificación con poca mejora visible. Puntos de partida sensatos:
- Calidad JPEG: 75 a 85 para fotos
- Calidad WebP: 70 a 80 si lo soportas
- Elimina metadatos en miniaturas
- Usa codificación progresiva solo si la has probado
Ejemplo: si alguien sube una foto de 10 MB y 6000 px, tu worker mantiene el original y genera versiones 320/800/1600 con tope en 1600 px. La UI sigue rápida y los workers se mantienen predecibles.
Almacena los originales por separado y trata las miniaturas como derivados
Mantén el original de la subida como un archivo de solo lectura, aunque tu app sirva mayoritariamente imágenes redimensionadas. Te da un fallback limpio cuando algo falla y te permite generar nuevos tamaños más tarde sin pedir al usuario que vuelva a subir. También evita la pérdida de calidad por redimensionar una imagen ya redimensionada.
Una buena regla es nunca sobrescribir el original durante el procesamiento. Escribe los derivados en una ruta o bucket diferente y usa un derivado en la UI solo cuando esté totalmente generado.
Nombrar derivados para que sean fáciles de encontrar
Haz las claves de los derivados predecibles. Usa un ID de imagen estable más una etiqueta de tamaño, y trata el original como otra variante con una etiqueta especial.
Por ejemplo, si el original está ligado al ID img_7F3, podrías almacenar:
img_7F3/originalimg_7F3/w_200_h_200_fillimg_7F3/w_1200_fit
Esto mantiene las búsquedas simples: la app puede solicitar un tamaño específico sin adivinar nombres de archivo, y los workers pueden regenerar derivados sin escanear el almacenamiento.
Almacena metadata para mantener la app honesta
Registra lo que tienes y lo que está pendiente. En tu base de datos, guarda ancho/alto original, tipo de contenido y un estado de derivados.
Un conjunto simple de campos:
- Dimensiones originales y tamaño de archivo
- Estado de procesamiento (pending, ready, failed)
- Qué tamaños existen (y cuándo fueron generados)
- Checksum opcional para detectar duplicados
Si un derivado falla, la UI puede seguir mostrando un placeholder mientras se reintenta.
Mantén los workers estables: límites, reintentos y visibilidad
Los workers son donde ganas o pierdes fiabilidad. Si la cola de redimensionado sobrecarga CPUs, se cuelga o falla silenciosamente, los usuarios lo notan, pero más tarde.
Empieza con límites de concurrencia. Redimensionar consume CPU y memoria. Un pico de subidas puede dejar al resto de tu app sin recursos. En lugar de ejecutar tantos jobs como sea posible, empieza pequeño (a menudo 1 a 4 jobs por host) y escala solo cuando veas el impacto.
Los reintentos ayudan, pero con backoff. Muchas fallas son temporales: problemas de almacenamiento, reinicios, caídas de red cortas. Reintentar al instante puede crear acumulación. Usa backoff exponencial con jitter y un número máximo de intentos sensato, luego marca el job como fallido.
También añade límites de tiempo. Un job de redimensionado nunca debería ejecutarse para siempre. Pon un timeout por job y registra errores con suficiente contexto para depurar (tipo de archivo, dimensiones e identificadores que puedas buscar).
Finalmente, añade visibilidad básica para notar problemas temprano: profundidad de cola, tasa de fallos, tiempo de procesamiento mediano y p95, y edad del job más antiguo.
Errores comunes que aún causan timeouts
Los timeouts suelen aparecer después de que “arreglaste” las subidas y luego el tráfico crece o alguien sube una foto enorme.
El mayor error sigue siendo redimensionar durante la petición web porque parece más simple. Funciona en pruebas y luego varios uploads grandes coinciden y tu servidor quema su presupuesto de peticiones decodificando y comprimiendo imágenes.
Otro problema es generar demasiado. Si creas 8 a 12 tamaños por subida y los haces todos a la vez, aún puedes sobrecargar workers. Lo más seguro es menos tamaños estándar y solo los que realmente necesitas.
Faltan guardarraíles en las entradas también es común. Una sola imagen de 8000 x 8000 puede consumir memoria y hacer caer workers. Para los usuarios eso puede parecer “nunca termina” porque el job no completa.
Trampas recurrentes:
- Redimensionar o comprimir dentro del handler de la petición, incluso “solo para la primera miniatura”
- Crear muchos tamaños por subida y procesarlos todos en un solo job
- Aceptar dimensiones de píxel o tamaños de archivo ilimitados
- Servir originales en la UI por accidente en lugar de miniaturas
- No manejar estados parciales (original guardado, miniaturas pendientes)
Los estados parciales son traicioneros. Si la página asume que las miniaturas existen ya, puede seguir reintentando, bloquear el renderizado o disparar procesamiento repetido. Muestra un placeholder hasta que el derivado esté listo y haz la generación idempotente para que los reintentos sean seguros.
Lista rápida antes de lanzar
Trata la ruta de subida como un policía de tráfico, no como un taller. La subida debe aceptar el archivo, almacenarlo y devolver rápido, incluso cuando alguien envía una foto enorme desde un teléfono moderno.
Antes del lanzamiento, prueba con algunas imágenes de peor caso (dimensiones muy grandes, JPEG de alta calidad y PNG con transparencia). Observa qué pasa desde la subida hasta la visualización de la miniatura.
Checklist:
- La petición de subida termina rápido y nunca espera al redimensionado.
- El archivo original se guarda inmediatamente y el registro está claramente marcado como processing.
- Se crea un job en segundo plano enseguida y los workers lo recogen puntualmente.
- Las miniaturas se escriben en ubicaciones predecibles y verificas que existen tras el procesamiento.
- La UI maneja la brecha: muestra un placeholder y sustituye las miniaturas cuando llegan.
Una prueba sencilla: sube una foto de 12 MB en una conexión lenta y luego recarga la página. Debes ver siempre un resultado estable: la entrada de imagen existe, la app no gira eternamente y las miniaturas aparecen un poco después.
Escenario de ejemplo: arreglando subidas de fotos en una app real
Una pequeña app de marketplace permite a vendedores subir 5–10 fotos por listado. La mayoría de imágenes tienen 3 a 8 MB y algunas superan 4000 px de ancho. En pruebas todo parece bien, pero durante la noche las subidas empiezan a fallar.
La causa raíz es que la app redimensiona imágenes y genera miniaturas dentro de la misma petición que guarda el listado. Cuando varios usuarios pulsan “Publicar” a la vez, el servidor se queda decodificando JPEGs grandes, redimensionándolos y escribiendo múltiples archivos. Las peticiones se acumulan, otras páginas van lentas y las subidas fallan.
La solución no tiene que cambiar mucho la UI. Mantén el flujo, pero cambia lo que pasa detrás:
- Guarda rápido la imagen original (object storage o un bucket separado).
- Crea un registro en la base de datos por cada imagen con estado pending.
- Empuja un job a una cola en segundo plano para generar miniaturas estándar.
- Muestra el listado inmediatamente usando una miniatura placeholder hasta que el job termine.
Si algunas miniaturas fallan, trátalo como un problema operativo en vez de un error visible al usuario. Reencola el job unas cuantas veces con un retraso corto. Tras el último reintento, mantiene el original disponible, sigue mostrando el placeholder y lanza una alerta para inspeccionar el archivo que rompió el redimensionado.
Siguientes pasos: hazlo fiable y luego fácil de mantener
Una vez que las subidas dejan de tener timeouts, la meta es que sigan así a medida que la app crece. La mayor ganancia es escribir unas reglas para que todos construyan igual dentro de meses.
Empieza con un corto “contrato de imagen” que incluya tus tamaños de miniatura, dimensiones máximas y tamaño de archivo aceptado, formatos de salida y ajustes de calidad, qué significa “ready” y qué pasa en caso de fallo.
Añade la visibilidad justa para detectar problemas temprano. Dos métricas ayudan mucho: duración de la petición de subida (p95) y tiempo de procesamiento de jobs de miniatura (p95). Si alguna sube, lo verás antes de que los usuarios se quejen.
Si ya tienes imágenes en producción, planea un backfill seguro. Evita ejecutar un lote enorme que compita con el tráfico real. Genera miniaturas en pequeños fragmentos, limita la concurrencia y controla el progreso para poder pausar y reanudar.
Si heredaste un prototipo generado por IA donde las subidas son frágiles (colgones aleatorios, reglas de almacenamiento confusas, límites de worker faltantes), una pasada de remediación puede ser más rápida que intentar parchear síntomas. FixMyMess (fixmymess.ai) se centra en diagnosticar y reparar codebases generados por IA, incluyendo mover el procesamiento de imágenes a workers en segundo plano, añadir guardarraíles y endurecer la canalización para producción.
Preguntas Frecuentes
Why do image uploads time out even when the server seems fine?
Normalmente significa que tu servidor está intentando hacer demasiado dentro de la misma petición: recibir el archivo, redimensionarlo, codificar nuevas versiones y escribir múltiples salidas antes de responder. Bajo carga o con una foto grande, ese trabajo empuja la petición más allá del tiempo de espera.
Should I resize images during the upload request?
No. Guarda el original primero y devuelve éxito; luego genera las miniaturas en segundo plano. Si necesitas mostrar algo de inmediato, muestra un marcador de posición y sustituye la miniatura cuando esté lista.
Why is thumbnail generation so CPU and memory expensive?
Las imágenes modernas tienen muchos píxeles aunque parezcan normales en pantalla. Redimensionar requiere decodificar a píxeles en crudo (memoria), usar CPU y volver a codificar, lo que puede provocar picos de uso y ralentizar otras peticiones.
What’s the simplest architecture to stop upload timeouts?
Almacena rápido el original, encola un job con el ID de imagen y los tamaños objetivo, y deja que workers en segundo plano generen los derivados. Tu API puede devolver un ID y un estado “processing” para que la UI siga respondiendo mientras el worker termina.
How should the client behave while thumbnails are still processing?
Haz que la UI trate las subidas como un estado de dos pasos: “uploaded” y “ready”. Tras el éxito de la subida, muestra una miniatura estable (placeholder) y consulta o refresca la metadata hasta que el derivado esté disponible; luego sustitúyelo sin bloquear la página.
Do I really need to cap image dimensions and file size?
Sí. Un límite estricto en dimensiones aceptadas y tamaño de archivo evita que una sola imagen enorme agote la memoria o haga caer workers. Conserva el original, pero asegúrate de que los derivados nunca excedan tu ancho/alto máximo para mantener el coste de procesamiento predecible.
How many thumbnail sizes should I generate?
Elige un pequeño conjunto de anchos estándar que cubran tu UI, por ejemplo feed, detalle y vista grande. Menos tamaños = menos cómputo, menos almacenamiento, cachés más simples y menos puntos de fallo, manteniendo una buena apariencia en distintos dispositivos.
Why store originals separately from thumbnails?
Trata el original como la fuente de verdad y nunca lo sobrescribas. Los derivados se pueden regenerar en cualquier momento, lo que hace que los reintentos sean seguros, permite añadir tamaños más tarde y evita pérdida de calidad por redimensionar imágenes ya redimensionadas.
What worker settings prevent the resize queue from becoming the new bottleneck?
Comienza con baja concurrencia para que los workers no se coman los recursos del resto de la app, y escala según métricas reales. Añade timeouts por job, reintentos con backoff, y registros de error claros para que las fallas no queden atascadas y las imágenes no se queden en “processing”.
What if my AI-built app keeps breaking uploads and I’m not sure where to start?
Si tu proyecto es un prototipo generado por IA con subidas que se cuelgan, secretos expuestos o reglas de almacenamiento confusas, a menudo es más rápido hacer una pasada de remediación focalizada que seguir parcheando síntomas. FixMyMess puede auditar la canalización, mover el procesamiento a workers, añadir guardarraíles y estabilizar las subidas para que puedas lanzar con confianza.