Logging estructurado para depurar en 5 minutos en producción
El logging estructurado facilita reproducir bugs en producción rápidamente. Añade request IDs, límites de error y patrones de log listos para copiar para depurar en 5 minutos.
Por qué los bugs en producción parecen imposibles de reproducir
Un informe de error en producción suele ser algo así: “Se rompió cuando hice clic en el botón.” Sin captura de pantalla, sin hora exacta, sin ID de usuario y sin pistas sobre dispositivo o navegador. Para cuando lo intentas reproducir tú, funciona perfectamente.
Producción es desorden porque las condiciones exactas son difíciles de recrear. Los usuarios reales tienen cuentas diferentes, datos distintos, redes inestables, varias pestañas abiertas y sesiones caducadas. Un problema de tiempo raro puede convertirse en un fallo que nunca ves en staging.
Los prints en consola y los mensajes de error vagos no sobreviven este entorno. La consola de un usuario no es tu consola, y aun si recopilas logs, “algo falló” no te dice qué request, qué feature flag o qué servicio upstream lo provocó. Peor aún: un único error no manejado puede detener la app antes de que registre el detalle que necesitabas.
El objetivo es simple: cuando llegue un informe, deberías poder responder tres preguntas en minutos:
- Qué pasó (el evento y la acción del usuario)
- Dónde pasó (la petición exacta, la página y el componente)
- Por qué pasó (el error, más el contexto importante)
Por eso importa el logging estructurado. En lugar de volcar frases aleatorias, registras eventos consistentes con los mismos campos cada vez, así puedes filtrar y seguir la historia a través de servicios y pantallas.
No necesitas una reescritura grande para llegar ahí. Pequeños cambios suman rápido: añade un request ID a cada petición, inclúyelo en cada línea de log y captura caídas con error boundaries para seguir teniendo contexto cuando la UI falle.
Aquí tienes un ejemplo realista. Un fundador dice: “El checkout a veces se queda girando.” Sin mejores logs, adivinas: ¿proveedor de pagos? ¿base de datos? ¿auth? Con request IDs y eventos consistentes, buscas un ID y ves: checkout_started, payment_intent_created, luego un timeout en inventory_reserve, seguido por un error en la UI. Ahora tienes un único camino fallido para reproducir.
Si heredaste una app generada por IA donde los logs son aleatorios o faltan, esto suele ser una de las mejoras con mayor retorno. Equipos como FixMyMess suelen empezar con una auditoría rápida de lo que se puede y no se puede trazar hoy, luego añaden el logging mínimo para que el próximo bug sea una investigación de 5 minutos en lugar de una semana de conjeturas.
Qué son los logs estructurados, en lenguaje llano
Los logs en texto plano son los que probablemente has visto antes: una frase impresa en la consola como “User login failed”. Son fáciles de escribir, pero difíciles de usar cuando las cosas se rompen en producción. Cada persona redacta mensajes distinto, se omiten detalles y buscar se vuelve una tarea de adivinanza.
Logging estructurado significa que cada línea de log sigue la misma forma e incluye detalles clave como campos nombrados (a menudo en JSON). En lugar de una frase, registras un evento más el contexto alrededor. Así puedes filtrar, agrupar y comparar logs como datos.
Un buen log debería responder unas preguntas básicas:
- Quién fue afectado (qué usuario o cuenta)
- Qué pasó (la acción o evento)
- Dónde pasó (servicio, ruta, pantalla, función)
- Cuándo pasó (la marca de tiempo suele añadirse automáticamente)
- Resultado (éxito o fallo, y por qué)
Aquí está la diferencia en la práctica.
Texto plano (difícil de buscar):
Login failed for user
Estructurado (fácil de filtrar y agrupar):
{
"level": "warn",
"event": "auth.login",
"userId": "u_123",
"requestId": "req_8f31",
"route": "/api/login",
"status": 401,
"error": "INVALID_PASSWORD"
}
Los campos más útiles suelen ser los aparentemente aburridos que desearías tener después: event, userId (o ID de cuenta/equipo), requestId y status. Si solo añades cuatro campos, empieza por ahí. Te permiten responder: “¿Qué petición exacta hizo este usuario y qué devolvió la app?”
La estructura es lo que hace rápida la depuración en producción. Puedes buscar rápidamente todos los event = auth.login fallidos, agrupar por status o sacar todos los logs con requestId = req_8f31 para ver la historia completa de un problema de usuario. Esa es la diferencia entre buscar durante 30 minutos y encontrar el problema en 5.
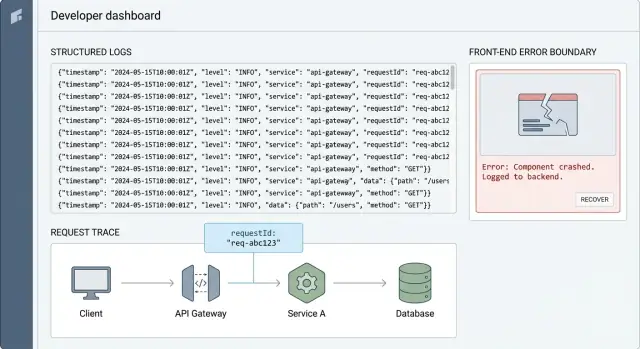
Request IDs: la forma más rápida de trazar un problema de usuario
Un request ID es una cadena corta y única (como req_7f3a...) que adjuntas a una acción de usuario. La idea es simple: conecta todo lo que pasó por esa acción, desde el click en el frontend, hasta la API, la consulta a la base de datos y de vuelta.
Sin él, depurar en producción se convierte en adivinanza. Buscas logs por tiempo, usuario o endpoint y aun así acabas con un montón de mensajes no relacionados. Con un request ID, puedes filtrar hasta una sola historia y leerla en orden.
Esto es correlación: el mismo ID aparece en cada línea de log que pertenece a la misma request. Es el pegamento que hace que el logging estructurado sea realmente usable cuando estás bajo presión.
Dónde se debe crear el request ID
Crea el ID lo antes posible y pásalo por todas las capas.
- En el borde (CDN / load balancer) o gateway de API, si tienes uno
- Si no, en el punto de entrada del backend (el primer middleware que maneja la petición)
- Si ninguno existe (común en prototipos generados por IA), généralo en el handler del servidor antes de cualquier otra cosa
Una vez creado, devuélvelo al cliente en una cabecera de respuesta también. Cuando un usuario diga “falló”, puedes pedir ese ID o mostrarlo en una pantalla de soporte.
Cuándo reutilizar vs generar un nuevo ID
Reutiliza el mismo request ID durante toda la vida de una petición, incluidas llamadas internas que desencadene. Si tu API llama a otro servicio, pasa el ID para que la traza no se rompa.
Genera un nuevo ID cuando ya no estés manejando la misma petición:
- Reintentos: conserva el ID original como padre, pero da a cada intento su propio attempt ID (para ver fallos repetidos)
- Trabajos en background: crea un job ID nuevo y guarda el request ID original como el “trigger” (para poder conectar el job con la acción del usuario)
Un ejemplo simple: un usuario hace clic en “Pay” y obtiene un error. El frontend registra requestId=abc123, la API registra el mismo abc123 con la ruta y el ID de usuario, y la capa de base de datos registra abc123 junto a la consulta y tiempos. Cuando el pago falla, puedes sacar abc123 y ver exactamente dónde se rompió, normalmente en minutos.
Cómo añadir request IDs de extremo a extremo (paso a paso)
Un request ID es un valor corto y único que sigue una acción de usuario por tu sistema. Cuando soporte dice “checkout falló a las 14:14”, el request ID te permite sacar cada línea de log relacionada en segundos.
Configuración paso a paso
Usa el mismo patrón básico en cualquier stack:
- Crea (o acepta) un request ID en el borde del servidor. Si el cliente ya envía uno (a menudo
X-Request-Id), consérvalo. Si no, généralo tan pronto como la petición entre en tu API. - Almacénalo en el contexto de la request para que cada log lo incluya. Ponlo en un lugar desde el que tu código pueda leerlo sin pasarlo por cada función. Muchos frameworks tienen almacenamiento local por request. Si no, adjúntalo al objeto request.
- Devuélvelo al cliente en la respuesta. Añade una cabecera de respuesta como
X-Request-Id. Esto da a soporte y a los usuarios algo concreto para copiar. - Pásalo a todo lo downstream. Añade la misma cabecera en llamadas HTTP salientes, inclúyelo en payloads de colas/jobs y pásalo a envoltorios de base de datos para que consultas lentas se puedan unir a la misma request.
- Inclúyelo en reportes de errores (opcional). Cuando captures excepciones, adjunta
requestIdpara que los crash reports y logs coincidan. Para errores visibles al usuario, puedes mostrar un “código de soporte” corto derivado del request ID.
Aquí hay un ejemplo simple al estilo Node/Express. La idea es la misma en otros lenguajes:
import crypto from "crypto";
app.use((req, res, next) => {
const incoming = req.header("X-Request-Id");
req.requestId = incoming || crypto.randomUUID();
res.setHeader("X-Request-Id", req.requestId);
next();
});
function log(req, level, message, extra = {}) {
console.log(JSON.stringify({
level,
message,
requestId: req.requestId,
...extra
}));
}
Una vez esto está en su lugar, tu logging estructurado se vuelve instantáneamente más útil: cada evento se puede buscar por requestId, incluso si el problema salta entre servicios.
Si heredaste una app generada por IA donde los logs son cadenas aleatorias (o faltan completamente), añadir request IDs es una de las reparaciones más rápidas porque mejora la depuración sin cambiar la lógica del negocio.
Diseñar eventos de log que realmente puedas buscar
Los buenos logs se leen como una línea de tiempo. Cuando algo falla, debes poder responder: qué pasó, en qué request y qué decisión tomó el código.
Con logging estructurado, eso significa que cada línea de log es un pequeño registro con los mismos campos cada vez, no una frase libre. La consistencia es lo que hace que la búsqueda funcione.
Empieza con un pequeño conjunto de nombres de eventos
Elige algunos tipos de evento centrales y reutilízalos en toda la app. Evita inventar un nombre nuevo para lo mismo cada semana.
Aquí hay tipos de evento comunes que siguen siendo útiles con el tiempo:
- request_started
- request_finished
- db_query
- auth_failed
- error
Nombra eventos en minúsculas con guiones bajos y mantén el significado estable. Por ejemplo, si ya tienes auth_failed, no añadas login_denied y sign_in_rejected más tarde a menos que signifiquen algo distinto.
Registra una decisión, no una línea de código
Una regla simple: registra cuando el programa toma una decisión que cambia el resultado. Ese es el punto que querrás encontrar después.
Malo: registrar cada línea alrededor de una llamada a la base de datos.
Mejor: un único evento db_query que te diga lo que importó: qué modelo/tabla (no SQL crudo), si tuvo éxito y cuánto tardó.
Incluye siempre campos de resultado
Haz fácil filtrar por fallos y caminos lentos. Añade algunos campos que aparezcan en la mayoría de eventos:
- ok: true o false
- errorType: una categoría corta como ValidationError, AuthError, Timeout
- durationMs: para cualquier cosa cronometrada (peticiones, bd, API externa)
- statusCode: para respuestas HTTP
Un ejemplo realista: si un usuario informa “el checkout falla”, deberías poder buscar event=auth_failed o ok=false, luego filtrar por statusCode=401 o errorType=AuthError y finalmente detectar la parte lenta ordenando por durationMs.
Si estás heredando código generado por IA, esto a menudo falta o es inconsistente. En FixMyMess, una de las primeras reparaciones es normalizar nombres de eventos y campos para que la depuración en producción deje de ser adivinanza.
Niveles de log y volumen sin ahogarse en ruido
Si cada evento se registra como error, dejas de confiar en tus logs. Si lo registras todo como debug, entierras la pista que necesitabas. Una buena depuración en producción empieza con una promesa simple: los logs por defecto deben explicar qué pasó sin inundar tu sistema.
Para qué sirve cada nivel
Piensa en los niveles de log como un sistema de ordenación por urgencia y expectativa. En logging estructurado, el level es solo otro campo por el que puedes filtrar.
- DEBUG: Detalles que solo quieres al investigar. Ejemplo: tiempo de respuesta de una API downstream, o la rama exacta que tomó tu código.
- INFO: Hitos normales. Ejemplo: "user signed in", "payment intent created", "job completed".
- WARN: Algo salió mal, pero la app puede recuperarse. Ejemplo: reintento de una petición, usar un valor de fallback, un servicio tercero devolviendo 429.
- ERROR: La operación falló y necesita atención. Ejemplo: excepción no manejada, escritura en BD fallida o una petición que devuelve 5xx.
Una regla práctica: si haría que alguien se despierte por la noche si aumenta, probablemente es ERROR. Si ayuda a explicar una queja de usuario más tarde, probablemente es INFO. Si solo es útil mientras tienes un ticket abierto específico, es DEBUG.
Mantén el volumen bajo control
Los endpoints de alto tráfico pueden generar ruido rápido, especialmente en apps generadas por IA donde el logging a menudo se añade por todas partes sin plan. En lugar de borrar logs, controla el caudal.
Usa tácticas simples:
- Muestreo (sampling): registra el 1% de las peticiones exitosas, pero el 100% de WARN y ERROR. El muestreo es más útil en health checks, endpoints de sondeo y jobs de background muy verbosos.
- Límites de tasa: si la misma advertencia se repite, regístrala una vez por minuto con un contador.
- Un evento por resultado: prefiera un único log "request finished" con duración y estado en lugar de 10 logs pequeños.
Finalmente, vigila el rendimiento. Evita construir strings pesados o serializar JSON en caminos calientes. Registra campos estables (como route, status, duration_ms) y calcula detalles costosos solo cuando el nivel está habilitado.
Error boundaries: atrapa caídas y conserva contexto útil
Un error boundary es una red de seguridad en la UI. Cuando un componente falla durante el renderizado, un método de ciclo de vida o el constructor, el boundary lo atrapa, muestra una pantalla de fallback y (lo más importante) registra lo ocurrido. Así conviertes una página en blanco y una queja vaga en algo que puedes reproducir.
Qué atrapa: errores síncronos de UI que ocurren mientras la app construye la página. Qué no atrapa: errores en manejadores de eventos, timeouts o la mayoría del código asíncrono. Para esos, aún necesitas try/catch y manejo de promesas rechazadas.
Qué registrar cuando la UI se cae
Cuando el boundary se dispara, registra un único evento con suficiente contexto para buscar y agrupar fallos similares. Si usas logging estructurado, mantén las claves consistentes.
Captura:
route(la ruta actual) y cualquier estado importante de UI (pestaña, modal abierto, paso de un wizard)component(dónde falló) yerrorName+messageuserAction(qué hizo el usuario justo antes, como "clicked Save")requestId(si lo tienes desde el servidor o tu cliente API)- información de
build(versión de la app, entorno) para poder coincidir con un release
Aquí tienes una forma simple:
log.error("ui_crash", {
route,
component,
userAction,
requestId,
errorName: error.name,
message: error.message,
stack: error.stack,
appVersion,
});
Qué debe ver el usuario vs qué necesitan los desarrolladores
El mensaje para el usuario debe ser calmado y seguro: “Algo salió mal. Por favor, refresca. Si sigue pasando, contacta con soporte.” Evita mostrar texto de error crudo, stack traces o IDs que puedan revelar detalles internos.
Los desarrolladores, en cambio, necesitan el contexto completo en los logs. Un buen patrón es mostrar un “código de error” corto en la UI (como una marca de tiempo o token aleatorio) y registrar el evento detallado con ese mismo token.
En el servidor, usa redes de seguridad equivalentes: un handler global de errores para peticiones, además de manejadores para promesas rechazadas no atendidas y excepciones no capturadas. Aquí es donde muchas apps generadas por IA fallan, y por qué equipos como FixMyMess suelen encontrar caídas “silenciosas” sin requestId ni logs útiles.
Si lo configuras una vez, un crash en producción deja de ser un misterio y se convierte en un evento buscable que puedes arreglar rápido.
Registrar de forma segura: evita filtrar secretos y datos personales
Los buenos logs te ayudan a arreglar bugs rápido. Los malos logs crean nuevos problemas: contraseñas filtradas, claves de API expuestas y datos personales que nunca debiste guardar. Una regla simple funciona bien: registra lo que necesitas para depurar el comportamiento, no lo que el usuario escribió.
Nunca registres estos (ni siquiera “solo por ahora”): contraseñas, cookies de sesión, tokens de auth (JWTs), claves de API, códigos OAuth, claves privadas, números completos de tarjeta, CVVs, datos bancarios completos. Trata también los datos personales como sensibles: direcciones de email, números de teléfono, direcciones postales, IPs (en muchos casos) y campos de texto libre que puedan contener cualquier cosa.
Alternativas más seguras que aún te permiten depurar
En lugar de volcar payloads completos, registra piezas pequeñas y estables de contexto que te ayuden a reproducir el problema.
- Redacta: reemplaza secretos por "[REDACTED]" (hazlo automáticamente).
- Valores parciales: registra solo los últimos 4 caracteres de un token o número de tarjeta.
- Hash: registra un hash unidireccional de un email para correlacionar eventos sin almacenar el email.
- Usa IDs: userId, orderId, invoiceId y requestId suelen ser suficientes.
- Resume: registra recuentos y tipos ("3 items", "payment_method=card") en lugar del objeto completo.
Ejemplo: en lugar de loguear todo el request de checkout, registra orderId, userId, cartItemCount y paymentProviderErrorCode.
Por qué el código generado por IA filtra secretos (y cómo evitarlo)
Los prototipos generados por IA a menudo registran cuerpos de petición enteros, cabeceras o variables de entorno en “modo debug”. Eso es arriesgado en producción y fácil de pasar por alto porque “funciona”. Busca trampas comunes: console.log(req.headers), print(request.json()), loggear process.env o registrar el objeto de error completo que incluya cabeceras.
Protégéte con dos hábitos: sanitizar antes de loggear y bloquear claves peligrosas por defecto. Crea un pequeño wrapper de “logger seguro” que redacte campos como password, token, authorization, cookie, apiKey y secret sin importar dónde aparezcan.
Finalmente, adopta una mentalidad de retención. Almacena logs detallados solo el tiempo que realmente los necesites para depuración y revisiones de seguridad. Mantén resúmenes más tiempo, elimina detalles crudos pronto y facilita purgar logs de un usuario cuando sea necesario.
Un ejemplo realista de depuración en 5 minutos
Un usuario reporta: “No puedo iniciar sesión. Funciona en mi laptop, pero no en producción.” No puedes reproducirlo localmente y la única pista es una marca de tiempo y su email.
Con logging estructurado y request IDs en su lugar, empiezas desde el informe del usuario y trabajas hacia atrás a partir de una sola request.
Minuto 1: encontrar la request
Tu soporte o la UI muestran un “Código de soporte” corto (que es solo el requestId). Si aún no tienes esa UI, puedes buscar logs por el identificador del usuario (email hasheado) alrededor de la hora reportada y luego extraer el requestId del primer evento que coincida.
Minutos 2-4: trazar el flujo y detectar el paso que falla
Filtra logs por requestId=9f3c... y ahora tienes una historia limpia: un intento de login de extremo a extremo, a través de varios servicios.
{"level":"info","event":"auth.login.start","requestId":"9f3c...","userHash":"u_7b1...","ip":"203.0.113.10"}
{"level":"info","event":"auth.oauth.callback","requestId":"9f3c...","provider":"google","elapsedMs":412}
{"level":"error","event":"db.query.failed","requestId":"9f3c...","queryName":"getUserByProviderId","errorCode":"28P01","message":"password authentication failed"}
{"level":"warn","event":"auth.login.denied","requestId":"9f3c...","reason":"dependency_error","status":503}
Esa tercera línea es la respuesta completa: la base de datos rechazó la conexión en producción. Porque el log tiene un nombre de event estable y campos como queryName y errorCode, no pierdes tiempo leyendo muros de texto ni adivinando a qué stack trace pertenece este usuario.
Si también tienes un error boundary en el cliente, puede aparecer un evento matching como ui.error_boundary.caught con el mismo requestId (pasado como cabecera) y la pantalla donde ocurrió. Eso ayuda a confirmar el impacto visible sin depender de capturas de pantalla.
Minuto 5: convertir logs en un caso de prueba reproducible
Ahora puedes escribir una reproducción ajustada que coincida con la realidad:
- Usa la misma ruta de login (callback de Google)
- Ejecuta contra la configuración similar a producción (fuente correcta de usuario/secretos de BD)
- Ejecuta la única operación que falla (
getUserByProviderId) - Aserta el comportamiento esperado (devolver un 503 claro con un mensaje seguro)
En muchas bases de código “generadas por IA” que vemos en FixMyMess, este problema ocurre porque los secretos están codificados localmente pero se obtienen de forma distinta en producción. El objetivo de los logs no es más datos, sino los campos correctos para ir de una queja de usuario a un paso fallido, rápido.
Lista rápida, errores comunes y próximos pasos
Cuando aparece un problema en producción, quieres logs que respondan tres preguntas rápido: qué pasó, a quién le pasó y dónde se rompió. Esta lista mantiene tu logging estructurado útil cuando estás bajo presión.
Lista rápida
- Cada request tiene un
requestId, y aparece en cada línea de log de esa request. - Cada log de error incluye
errorTypey un stack trace (o el equivalente más cercano en tu lenguaje). - Auth y pagos (o cualquier camino de dinero) tienen eventos claros de “start” y “finish” para detectar dónde se detiene el flujo.
- Secretos y tokens se redactan por defecto, y nunca vuelcas payloads completos de request o response.
- Los mismos campos centrales siempre están presentes:
service,route,userId(oanonId),requestIdydurationMs.
Si no haces nada más, asegúrate de poder pegar un requestId en tu buscador de logs y ver la historia completa desde el primer handler hasta la última llamada a la base de datos.
Errores comunes que hacen perder tiempo
Incluso buenos equipos caen en algunas trampas que hacen los logs difíciles de usar cuando importa.
- Nombres de campos inconsistentes (por ejemplo
req_id,requestIdyrequest_idusados en distintos sitios). - Falta de contexto (se registra un error, pero no puedes saber qué ruta, usuario o paso lo causó).
- Registrar solo en errores (necesitas algunos eventos “hito” clave para ver dónde se detiene un flujo).
- Demasiado ruido en el nivel equivocado (todo es
info, así las advertencias reales quedan enterradas). - Fugas accidentales de datos (tokens, claves API, cookies de sesión o payloads de pago completos en los logs).
Próximos pasos: elige los 3 flujos críticos para usuarios (a menudo registro/login, checkout y restablecer contraseña). Añade request IDs de extremo a extremo y luego 3 a 6 eventos buscables por flujo (start, paso mayor, finish y un evento claro de fallo). Cuando esos estén sólidos, expándelo al resto de la app.
Si tu app generada por IA es difícil de depurar porque los logs son un desastre o faltan, FixMyMess puede hacer una auditoría de código gratuita y ayudar a añadir request IDs, campos de evento consistentes y manejo de errores más seguro para que los problemas en producción sean más fáciles de reproducir.