Registros de auditoría para acciones de admin que resuelven disputas rápido
Los registros de auditoría para acciones de admin te permiten ver quién cambió qué, cuándo y por qué. Aprende qué capturar, cómo añadir diffs y cómo buscar logs para resolver disputas.
Por qué importan los registros de auditoría para admin y soporte
Cuando algo cambia en una app y nadie puede explicar por qué, el soporte se convierte en conjeturas. Los clientes se sienten acusados, los compañeros de equipo se sienten señalados, y problemas pequeños se vuelven hilos largos y respuestas a incidentes lentas.
Las acciones de admin y soporte son los movimientos entre bastidores que pueden cambiar la experiencia de un usuario sin que él haga nada. Un agente de soporte restablece una contraseña. Un admin cambia un plan. Alguien elimina contenido. Estas acciones suelen ser necesarias, pero generan más discusiones porque ocurren fuera de la vista.
Las disputas normalmente suenan así:
- “Nunca pedí ese reembolso, ¿por qué se emitió?”
- “Mi cuenta fue deshabilitada, ¿quién lo hizo y qué regla se activó?”
- “Nuestra suscripción se degradó y desaparecieron funciones de la noche a la mañana.”
- “Se eliminó una publicación, pero necesitamos probar la razón y el momento.”
- “Soporte cambió mi correo y ahora no puedo iniciar sesión.”
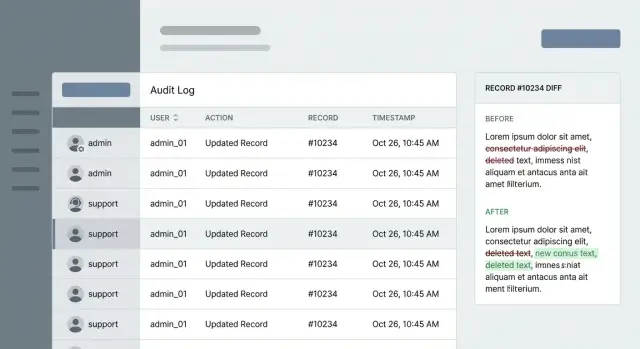
En esos momentos, el objetivo de un registro de auditoría no es “más datos”. Es una respuesta clara. Una buena entrada muestra quién hizo qué, sobre qué registro y cuándo. Una entrada excelente también muestra qué cambió (un diff) y suficiente contexto para explicar por qué pasó (ID de ticket, código de motivo, nota interna).
Esto importa aún más para equipos que envían rápido o heredan código generado por IA. Cuando la lógica es desordenada, la app puede comportarse distinto a lo esperado y aún necesitas una pista fiable. En FixMyMess, a menudo vemos prototipos construidos con herramientas como Cursor o Replit donde los paneles de administración funcionan a medias y las acciones críticas no se registran en absoluto: justo entonces las disputas se vuelven dolorosas.
Los buenos logs zanjan discusiones rápido, acortan investigaciones y protegen tanto a clientes como a tu equipo con hechos en lugar de opiniones.
Qué debe contener una entrada de auditoría
Un registro de auditoría solo es útil en una disputa si cada entrada responde claramente cinco preguntas: quién lo hizo, qué pasó, qué se vio afectado, cuándo ocurrió y de dónde vino. Si falta alguna, vuelves a adivinar.
Empieza por el actor. Almacena un identificador estable (user ID, admin ID o service account ID) y los permisos que tenía en ese momento (rol). Si soporte puede suplantar usuarios, registra eso explícitamente: realizado por admin X mientras suplantaba al usuario Y. Sin esto, no puedes distinguir si el cambio lo hizo el cliente o el personal en su nombre.
Captura la acción y el objetivo juntos. “Updated customer email” es mejor que “update”, pero no confíes solo en texto libre. Mantén un nombre de acción estructurado (create, update, delete, export, password reset, login override) y el registro exacto que se tocó. Incluye el tenant/workspace para separar cuentas.
Para el tiempo, guarda un timestamp preciso en UTC y solo dale formato a la hora local para la visualización. Las disputas a menudo dependen de minutos, y UTC evita la confusión por horario de verano.
Agrega suficiente contexto para rastrear el evento de extremo a extremo. Una línea base sólida es: punto de entrada (nombre de pantalla UI o endpoint API), request ID (y session ID si lo tienes), IP de origen y user agent (cuando sea apropiado), resultado (éxito/fallo con código de error) y una razón de soporte o referencia de ticket.
Ejemplo: un cliente dice: “Soporte cambió mi plan sin pedirlo.” Una entrada fuerte muestra el admin ID, si se usó suplantación, una acción como plan_update, el workspace objetivo, un timestamp UTC y un request ID que puedes seguir hasta la pantalla exacta o la llamada API. Esa es la diferencia entre una historia vaga y un log que resuelve el problema en minutos.
Registrar diffs sin filtrar datos sensibles
Un diff es la forma más simple de zanjar discusiones porque muestra los valores antes y después de cada campo que cambió. El objetivo es claridad sin convertir tus logs en una segunda base de datos llena de datos privados.
Registra solo lo que cambió. Si un admin edita un registro de cliente, registra una pequeña carga como role: user -\u003e admin y status: trial -\u003e active, no el perfil completo. Esto mantiene las entradas legibles, hace que las búsquedas sean más rápidas y reduce la exposición accidental.
Los campos sensibles requieren manejo especial. Normalmente no quieres valores en bruto en los logs para contraseñas, tokens de acceso, números completos de tarjeta o notas privadas. Una regla útil: si no lo pegarías en un chat de soporte, no lo pongas en el registro de auditoría.
Enfoques comunes incluyen enmascaramiento (por ejemplo, ****@gmail.com), hashing (una huella unidireccional), un simple indicador “changed” (como password: changed), redacción completa o separar detalles sensibles en un almacén distinto con acceso más restringido y retención más corta.
Los diffs son aún más útiles con intención. Añade un code de motivo (como customer_request, fraud_review, bug_fix, policy_exception) y una nota corta. Cuando surge una disputa más adelante, el “por qué” importa tanto como el “qué”.
También captura IDs relacionadas para reconstruir la historia: ticket ID, conversation ID, order ID, refund ID y la clave primaria del registro.
Ejemplo: un cliente afirma que soporte le subió el plan sin permiso. Tu entrada debería mostrar plan: basic -\u003e pro, la identidad del agente, el timestamp, el code de motivo customer_request y un ticket ID que coincida con la conversación donde pidieron el cambio. Si heredaste código generado por IA que registra demasiado (o nada), en FixMyMess solemos empezar añadiendo diffs seguros y reglas estrictas de redacción para que los logs resuelvan disputas en vez de crear nuevos riesgos.
Cómo diseñar logs en los que puedas confiar después
Los logs confiables tienen menos que ver con dashboards vistosos y más con reglas aburridas que nunca cambian. Si quieres que los registros de admin y soporte resuelvan disputas, necesitas entradas difíciles de falsificar, fáciles de leer y consistentes en todos los caminos de código.
Trata cada entrada como append-only. No edites eventos antiguos cuando algo cambie o cuando un agente cometió un error. Escribe un nuevo evento que corrija el anterior, así la historia permanece completa.
Usa una sola forma de evento en todas partes, incluso entre equipos y servicios. Cuando soporte, admins, jobs en background y llamadas API producen campos diferentes, el log deja de responder preguntas básicas bajo presión.
Un esquema práctico básico:
- who: user ID, rol e información de acting-as si aplica
- what: nombre de acción (por ejemplo,
user.password_reset) - where: tipo de registro y record ID
- when: timestamp del servidor (UTC)
- context: request correlation ID, origen (UI/admin panel/API key/background job) e IP/dispositivo cuando corresponda
Los correlation IDs son lo que convierten “creemos que pasó alrededor de las 3pm” en prueba. Genera uno por request, pásalo por llamadas internas y adjúntalo al evento de auditoría. Si una acción toca tres tablas, el mismo correlation ID te permite relacionar esos eventos con un único ticket de soporte o clic.
Registra la fuente siempre. “Admin changed plan” no basta cuando la pregunta real es si vino desde la UI de admin, una API key usada por una agencia o un job nocturno.
Planifica la retención desde temprano. Decide cuánto necesitas conservar eventos para disputas, qué tamaño pueden alcanzar los logs y dónde viven. Los equipos que vienen a FixMyMess a menudo descubren que su app generada por IA nunca registró acciones críticas o eliminó el historial demasiado pronto, lo que hace imposible la verificación cuando un cliente impugna un cargo.
Hacer que los logs sean realmente buscables para trabajo de soporte
La búsqueda es la diferencia entre “creemos que pasó esto” y “aquí está el momento exacto en que cambió”. Diseña la búsqueda según como trabaja el soporte: encuentra un cliente, reduce al registro y luego confirma el cambio exacto.
Mantén los nombres de acción pequeños y consistentes. Una taxonomía ajustada (piensa en decenas, no cientos) hace que los filtros sean útiles y evita el lío de “todo es personalizado” en el que acaban las apps construidas rápido. Si necesitas más detalle, ponlo en campos estructurados, no en un nuevo nombre de acción.
Normaliza lo básico para que cada evento pueda filtrarse de la misma manera en toda la app.
Los campos que hacen que la búsqueda funcione de verdad
Como mínimo, asegúrate de que cada evento incluya:
- action (por ejemplo,
user.password_reset,billing.refund_issued) - actor_id y actor_role (admin, support, system)
- record_type y record_id (siempre presentes y con el mismo formato)
- created_at (hora del servidor)
- request_id (para agrupar eventos relacionados)
Luego añade un pequeño conjunto de campos de “contexto de soporte” seguros que ayuden a buscar: email del cliente (o una versión hashed/normalizada), número de orden, nombre del workspace/org y ticket o conversation ID. Mantén estos como campos separados, no enterrados en una oración.
Evita eventos ruidosos. Vistas de página, aperturas de pantalla y “list loaded” entierran la señal. Los logs de auditoría deben centrarse en acciones que cambien el estado, concedan acceso o expongan datos sensibles.
Haz cada entrada legible sin perder estructura: una frase clara para humanos más campos estructurados para filtros. “Support agent updated billing email” es útil, pero debería incluir record_type=workspace, record_id=... y un resumen diff que pruebe qué cambió.
Paso a paso: añade logging de acciones de admin a una app
Un flujo de trabajo práctico
Lista lo que admins y soporte realmente pueden hacer hoy, no lo que esperas que hagan. Convierte cada capacidad en un nombre de evento claro para que el log lea como una línea temporal en lugar de un cajón de cosas sueltas.
Un flujo simple:
- Inventaria acciones de admin/soporte (refund, password reset, plan change, profile edit, role grant) y mapea cada una a un evento.
- Marca registros de alto riesgo que siempre deben loguear (auth, facturación, permisos, ownership de cuentas).
- Define el contexto requerido: actor, registro objetivo, timestamp, motivo y un diff seguro.
- Implementa el logging en la capa de servicio (donde corren las reglas de negocio), no disperso en botones de la UI.
- Ejecuta una “prueba de disputa” que reconstruya quién cambió qué y por qué usando solo los logs.
Después de mapear eventos, decide qué significa “target” en tu app. Un buen patrón es target_type (Subscription), target_id (sub_123) y IDs relacionados opcionales (como user_id). Esto facilita las búsquedas después.
Dónde se atascan los equipos
Alto riesgo no significa raro. Significa que un cambio aquí puede costar dinero, bloquear a alguien o generar una discusión de soporte. Si dudas, comienza con un conjunto corto: configuraciones de autenticación, facturación/facturas, roles/permissions, cambios de email/teléfono y cualquier cosa que afecte acceso.
Exige una razón humana para acciones sensibles, aunque sea corta. “Customer confirmed new email over phone” es mucho más útil que “updated.”
Ejecuta una disputa falsa antes de lanzar. Haz como si un cliente dijera “Soporte degradó mi plan sin pedirlo.” ¿Puedes extraer un evento que muestre: qué admin, qué registro, el diff antes/después (Plan: Pro -\u003e Basic), la nota de motivo y el timestamp? Si no, arregla los campos ahora.
Si estás reparando una app generada por IA, registrar en la capa de servicio también reduce los “eventos faltantes” cuando cambia el código de la UI. Suele ser una de las primeras correcciones que equipos como FixMyMess añaden cuando los prototipos se convierten en productos reales.
Acciones de alto riesgo que debes loguear siempre
Si solo vas a registrar unas pocas cosas, regístralas cuando cambian dinero, acceso o confianza. Estos son los momentos que se vuelven disputas: “Yo no cambié eso”, “Soporte accedió a mis datos” o “Alguien se escaló permisos a sí mismo.”
Las acciones que merecen logging siempre encendido
Prioriza eventos potentes, difíciles de revertir o que tocan datos sensibles. Una prueba simple: si un usuario estaría molesto viéndolo en un estado de cuenta, una captura o un informe de cumplimiento, pertenece al log.
Prioriza:
- Lecturas de datos sensibles (exports, descargas, “view full card”, abrir perfiles completos con detalles privados).
- Cambios de roles y permisos (actualizaciones de rol, pertenencia a grupos, API keys, SSO, flags de admin).
- Impersonación (inicio, fin y cada acción tomada mientras se suplantaba, registrando tanto al miembro del staff como a la cuenta cliente).
- Acciones masivas (reembolsos masivos, eliminaciones en lote, migraciones, ediciones por lotes), incluyendo conteos y referencias a los IDs afectados.
- Intentos fallidos restringidos (chequeos de permiso denegados, tokens admin inválidos, exports bloqueados), con rate limits para evitar ruido.
Un ejemplo rápido de cómo esto zanja disputas
Un cliente dice: “Soporte descargó mi lista de facturas y cambió mi plan.” Si tus logs capturan tanto “Export invoices” (lectura) como “Plan changed” (escritura), puedes mostrar rápidamente quién lo hizo, cuándo, desde qué sesión y si ocurrió durante suplantación.
Aquí muchos prototipos generados por IA fallan en producción: registran solo escrituras exitosas y se saltan lecturas sensibles. Plataformas como FixMyMess suelen comenzar añadiendo estos eventos de alto riesgo porque dan el mayor retorno de confianza y soporte con un pequeño cambio de código.
Mantén cada evento fácil de entender: un nombre de acción claro, el/los registros tocados y suficiente contexto para explicar por qué pasó sin exponer secretos.
Errores comunes que hacen que los logs no sean fiables
La mayoría de las disputas no ocurren porque no tengas logs. Ocurren porque los logs son vagos, incompletos o imposibles de confiar después. Un buen rastro de auditoría debería leerse como evidencia: claro, específico y difícil de manipular.
Un fallo frecuente es registrar un evento genérico como “updated user” sin detalle a nivel de campo. Cuando un cliente dice “Soporte cambió mi plan”, necesitas ver exactamente qué cambió (valor antiguo, valor nuevo), no solo que “algo” pasó. Sin diffs, también pierdes patrones como alternancias repetidas o sobreescrituras accidentales.
Otro error es volcar secretos y datos personales en el rastro. Tokens completos, contraseñas, cookies de sesión, API keys o datos de pago en bruto nunca deberían terminar en logs. Almacena valores redactados o referencias en su lugar, y registra que un campo sensible cambió sin almacenar su valor.
La atribución del actor falla más seguido de lo que los equipos esperan. Jobs en background, webhooks y scripts suelen ejecutarse como “system”, incluso cuando fueron disparados por un humano. Eso vuelve el rastro mucho menos útil para soporte real.
Killer de fiabilidad a vigilar:
- Eventos que pueden editarse o eliminarse después del hecho.
- Falta del actor (o siempre “system”) en flujos automatizados.
- Identificadores de registro inestables, de modo que las búsquedas devuelven ruido.
- Nombres de acción inconsistentes, por lo que los filtros se pierden la mitad de la historia.
- Diffs parciales o ambiguos (falta before/after).
Ejemplo: un founder disputa un cambio de reembolso. Tu log debería mostrar el diff del estado del reembolso, la cuenta admin que lo pulsó, el ticket/razón y el record ID. Cuando FixMyMess audita apps generadas por IA rotas, esta es una de las primeras brechas que vemos: “se actualizó” sin la prueba que necesitas.
Lista rápida para resolver una disputa usando logs
Cuando un cliente dice “Yo no cambié eso” o “Su equipo rompió mi cuenta”, el objetivo es simple: construir una línea de tiempo clara que ambas partes puedan entender. Los buenos logs te permiten responder tres preguntas rápido: quién lo hizo, qué cambió y cuándo.
Empieza amplio y reduce hasta que estés viendo un evento específico y su diff exacto.
Una forma rápida de llegar a la verdad
- Encuentra al cliente usando un identificador estable (customer ID, account ID, ticket ID) y confirma que estás viendo el registro correcto.
- Filtra por tipo de acción (password reset, refund, plan change) y actor (admin específico, agente de soporte, job automatizado).
- Abre los detalles del cambio y lee el diff, no solo el resumen.
- Usa el correlation/request ID para ver qué más pasó en el mismo flujo. Las disputas a menudo vienen de efectos secundarios, no del clic original.
- Escribe el resultado en palabras claras y, si hace falta, añade un evento de seguimiento que registre la resolución.
Pequeño ejemplo
Un cliente reporta que fue degradado sin consentimiento. El log muestra que un agente cambió el plan, pero el mismo correlation ID también incluye un intento de pago fallido segundos antes. El diff muestra que se ejecutó una regla de degradación automáticamente tras el intento fallido. Eso normalmente zanja la disputa y apunta a qué arreglar: aclarar la UI, endurecer permisos o mejorar la regla.
Si heredaste una app generada por IA, esto es de lo primero que añadir durante la limpieza. Equipos como FixMyMess suelen ver acciones administrativas poderosas que ocurren sin rastro, lo que convierte cada queja en conjeturas.
Ejemplo: trazar un cambio de soporte desde la queja hasta la prueba
Un cliente escribe: “Mi suscripción fue cancelada y yo no la cancelé.” Aquí los logs de admin y soporte eliminan la conjetura. Quieres una pista clara que muestre quién tocó la cuenta, qué cambió y por qué.
Empieza con el registro del cliente y filtra eventos alrededor del momento en que notó el problema. En un buen rastro, rápidamente encuentras una suplantación (o “login as user”) seguida de una actualización de suscripción.
Así podría verse esa pista cuando funciona bien:
2026-01-16 09:41:03Z actor=support:maya action=impersonate_user target=user:1842
context: ticket=SUP-10488 reason="Asked to check billing page error"
2026-01-16 09:43:19Z actor=support:maya action=subscription_update target=sub:7711
source=ui request_id=8f3c... ip=203.0.113.24
diff:
status: active -\u003e canceled
cancel_at_period_end: false -\u003e true
context: ticket=SUP-10488 note="Customer requested cancel at renewal"
Dos detalles zanjan disputas rápido: el diff (qué cambió) y el contexto (ticket ID, motivo y una nota corta). El timestamp y el actor aclaran si fue una acción de soporte o del cliente.
Confirma la fuente para no culpar al sistema equivocado:
- Acción UI: hay un actor interno más un session/request ID.
- API key: el actor es una key o integración, a menudo con un key ID.
- Job automatizado: el actor es el nombre del job, con un schedule/run ID.
Si el cambio fue incorrecto, reviértelo de inmediato (por ejemplo, vuelve a poner la suscripción en active) y luego registra la acción correctiva como su propio evento con una nota de motivo como “Reverted cancel, customer did not consent.” Esa entrada final evita que la misma discusión vuelva después.
Siguientes pasos: comienza pequeño y luego fortalece el rastro
Empieza con un alcance mínimo que puedas entregar en el próximo sprint. Elige las acciones de admin y soporte que más causan disputas y registra esas primero. Si solo haces una cosa, asegúrate de poder responder: quién lo hizo, qué cambió, qué registro y cuándo.
Una forma práctica de encontrar lagunas es un breve simulacro de disputa. Toma un ticket real pasado (o crea uno falso) e intenta probar qué pasó usando solo tus logs. Por ejemplo: “Un cliente dice que su plan fue degradado sin permiso.” ¿Puedes ver el usuario afectado, el actor (admin o system), los valores antes/después y el contexto del ticket? Si no, anota lo que falta y añádelo.
Una vez que lo básico funcione, agrega guardarraíles para que el rastro se mantenga seguro y útil: enmascara u omite campos sensibles (contraseñas, tokens, datos completos de tarjeta) mientras registras el hecho del cambio, fija retención que cumpla necesidades de soporte y requerimientos legales, restringe el acceso a los logs (y registra el acceso a los propios logs), y añade alertas para acciones de alto riesgo como cambios de rol, reembolsos y restablecimientos de autenticación.
Si tu base de código fue generada por herramientas de IA, el logging inconsistente es común: las acciones ocurren en múltiples lugares, las comprobaciones de auth difieren por ruta y los cambios “system” son difíciles de separar de los humanos. Una auditoría enfocada puede ser la corrección más rápida.
FixMyMess (fixmymess.ai) ofrece una auditoría de código gratuita para detectar faltantes en logging de auditoría, rastros de auth rotos y brechas de seguridad, especialmente para prototipos generados por IA que necesitan comportamiento listo para producción.
Preguntas Frecuentes
What problem do admin and support audit logs actually solve?
Un registro de auditoría convierte una disputa en una línea de tiempo comprobable. En lugar de debatir sobre lo que “debe haber pasado”, puedes apuntar a una entrada que muestre quién actuó, qué hizo, qué registro tocó y cuándo ocurrió.
Which admin/support actions should I log first?
Registra cualquier acción que cambie dinero, acceso o confianza. Comienza con restablecimientos de contraseña, cambios de email, cambios de rol/permiso, upgrades/downgrades de plan, reembolsos, cancelaciones, suplantación (impersonation) y exportaciones de datos sensibles.
What fields should every audit log entry include?
Una entrada útil responde cinco cosas: actor, acción, registro objetivo, timestamp y contexto de origen. En la práctica eso significa un ID de actor estable y su rol, un nombre de acción estructurado, tipo y ID del registro, hora en UTC, más detalles de request/session y una referencia de ticket o razón de soporte.
How do I name actions so logs stay searchable?
Usa una taxonomía de acciones pequeña y consistente como billing.refund_issued o user.password_reset. Mantén la explicación detallada en campos estructurados (diff, reason code, ticket ID) para que los filtros sigan siendo fiables y no acabes con docenas de nombres de acción casi iguales.
Should I store diffs (before/after values) in audit logs?
Registra a nivel de campo el antes/después solo para los campos que cambiaron. Los diffs deben ser pequeños y específicos (por ejemplo, plan: basic -\u003e pro) para demostrar qué cambió sin volcar registros enteros en tus logs.
How do I log changes without leaking sensitive data?
No almacenes valores en bruto para secretos o datos altamente sensibles como contraseñas, tokens, datos completos de pago o notas privadas. Prefiere redacción, enmascaramiento, hashing o un marcador simple como “changed”, y enfócate en registrar el hecho del cambio más quién/cuándo/dónde ocurrió.
Why should audit log timestamps be stored in UTC?
UTC evita confusiones por horario de verano y zonas horarias, algo común en disputas donde importan minutos. Almacena la hora en UTC y solo conviértela a hora local en la interfaz cuando alguien lea el log.
How should I log support impersonation (“log in as user”)?
La suplantación debe ser explícita y trazable. Registra el inicio y fin de la suplantación, y para cada acción realizada mientras se suplantaba, registra ambas identidades: el miembro del equipo que la realizó y el usuario/cuenta en cuyo nombre se actuó.
How do I make audit logs trustworthy and hard to tamper with?
Haz los logs append-only y trátalos como evidencia. Si algo estuvo mal, escribe un nuevo evento correctivo que haga referencia al original, y restringe quién puede acceder o eliminar logs; además deberías registrar el acceso a los propios logs.
My app was built with AI tools and logging is a mess—can this be fixed quickly?
Sí; es habitual que los prototipos generados por IA no registren críticamente o lo hagan de forma inconsistente. Una solución práctica es implementar logging en la capa de servicio (donde corren las reglas de negocio), estandarizar la forma de los eventos y nombres de acción, y añadir diffs seguros con redacción; FixMyMess puede hacer una auditoría rápida para identificar lo que falta y parchearlo rápido.