Soluciona problemas de configuración “funciona en mi máquina” para dev, staging y prod
Soluciona problemas de configuración “funciona en mi máquina” con separación clara entre dev, staging y prod, validación de variables de entorno y comprobaciones simples que evitan sorpresas en tiempo de ejecución.
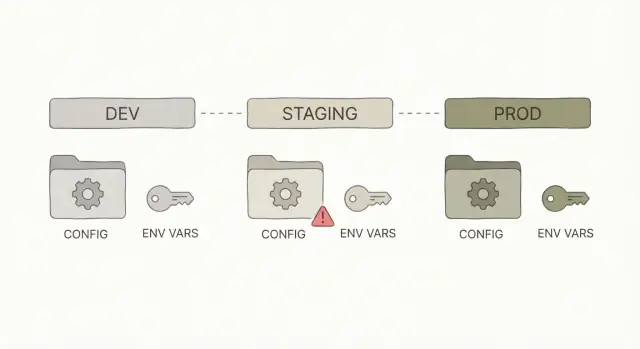
Qué suele significar “funciona en mi máquina"
Cuando alguien dice “funciona en mi máquina”, quiere decir que la app se ejecuta bien en su portátil pero falla tras el despliegue. El código puede ser el mismo, pero el entorno alrededor es distinto.
La mayoría de las veces no es un “bug lógico”. Es configuración: la app recibe entradas diferentes según dónde se ejecute. Localmente, tu equipo llena silenciosamente los huecos (inicios de sesión guardados, archivos locales, bases de datos seed, tokens en caché). En staging o producción, esas muletas no están.
Causas comunes:
- Variables de entorno faltantes o incorrectas (claves de API, URL de la base de datos, URL de callback de auth)
- Servicios externos distintos (SQLite local vs Postgres alojado, Stripe en sandbox vs Stripe en vivo)
- URLs y redirecciones diferentes (localhost vs un dominio real)
- Configuración de build y runtime distinta (versión de Node, puerto, feature flags)
- Secretos copiados en el código o en archivos
.envy nunca configurados en producción
Los problemas de configuración a menudo aparecen con síntomas confusos: el login funciona localmente pero falla tras el despliegue, los pagos se agotan por timeout, las imágenes no se suben o los jobs en segundo plano nunca se ejecutan. La ruta de código es la misma, pero la app apunta al sitio equivocado o le falta un valor necesario.
El objetivo es ejecuciones repetibles en cada entorno. Dev, staging y prod pueden usar valores distintos, pero deben seguir las mismas reglas. Si una variable es obligatoria en prod, trátala como obligatoria en todas partes. Si staging usa una base de datos distinta, debe seguir usando el mismo esquema y el mismo tipo de conexión.
Ejemplo: una app generada por IA se despliega y lanza inmediatamente “DATABASE_URL is undefined.” Localmente, el desarrollador la tenía en un archivo privado .env. En producción nunca se configuró. La solución no es buscar por el código. Es definir la configuración requerida, validarla al inicio y establecerla en cada entorno.
Dev vs staging vs prod: qué cambia y qué no debe cambiar
Dev, staging y prod son la misma app en tres lugares distintos.
- Dev es donde construyes y pruebas rápido en tu portátil.
- Staging es un ensayo que debería comportarse como producción, pero sin clientes reales.
- Prod es el sistema en vivo del que dependen las personas.
Algunas cosas deberían diferir entre entornos porque apuntan a servicios o datos distintos. Otras deben mantenerse idénticas para que realmente estés probando lo que vas a desplegar.
Qué debería cambiar
Mantén el código igual, pero intercambia los valores alrededor:
- URLs de servicios (base URL de API, URL de callback OAuth, URL de webhooks)
- Claves y secretos (credenciales distintas por entorno)
- Fuentes de datos (bases de datos y buckets separados, o al menos esquemas separados)
- Feature flags (valores seguros por defecto en prod, más toggles en dev)
- Nivel de logs (más detalle en dev, menos ruido en prod)
El entorno debe decidir estos valores, no la máquina local del desarrollador.
Qué no debe cambiar
La build y el runtime deben coincidir entre staging y prod: mismas dependencias, mismo paso de build, mismo comando de arranque y misma versión de runtime. Si staging usa node 20 pero prod usa node 16, estás probando una app diferente.
Evita cambios “rápidos” en producción, como editar un archivo de configuración en el servidor o añadir una variable de entorno faltante a mano sin registrarlo. Esos arreglos puntuales crean fallos que no puedes reproducir después. Un ejemplo común: alguien arregla a mano una URL de redirección en prod, staging queda desactualizado y el siguiente despliegue rompe el login.
Variables de entorno 101 (sin jerga)
Una variable de entorno (env var) es una configuración que tu app lee al arrancar. Vive fuera del código, normalmente la proporciona tu terminal, el servicio de hosting o la herramienta de despliegue.
Piensa en las env vars como entradas para tu app. Trátalas como requisitos, no como sugerencias. Si falta un valor, la app debería fallar rápido con un mensaje claro, no funcionar de manera degradada y romperse después.
Una forma simple de decidir qué va dónde:
- Env vars: valores que cambian por entorno o son sensibles. Ejemplos:
DATABASE_URL,JWT_SECRET,STRIPE_API_KEY,S3_BUCKET,APP_ENV. - Código: valores por defecto y lógica que debe ser igual en todas partes. Ejemplo: “las sesiones expiran después de 7 días.”
- Archivos de configuración (commiteados): configuraciones no secretas que quieres revisar y versionar. Ejemplo: feature flags que es seguro exponer, etiquetas de UI, orígenes CORS permitidos (solo si no son sensibles).
El nombrado es donde los equipos se suelen enredar. Elige una convención y cúmplela: mayúsculas, palabras separadas por guiones bajos y un prefijo si tienes múltiples servicios. Evita casi-duplicados como DB_URL, DATABASE y DATABASE_URL en distintas partes de la app.
Una trampa común son las env vars “opcionales” que deshabilitan características silenciosamente. Por ejemplo, una app generada por IA podría envolver el envío de correo en if (process.env.SMTP_PASSWORD) y nunca advertirte cuando falta. El resultado: los registros funcionan localmente, pero los restablecimientos de contraseña nunca llegan tras el despliegue.
Mejor regla: si una característica está activada en ese entorno, sus env vars requeridas deben estar presentes o la app debe detenerse y decirte qué falta.
Paso a paso: configura una estructura de config simple y consistente
La mayoría de los bugs de “funciona en mi máquina” ocurren porque la configuración está dispersa. Una persona pone valores en un archivo local, otra los pone en el panel del hosting y la app elige silenciosamente el que vea primero. Decide una estructura y síguela.
1) Elige una única fuente de verdad
Para la mayoría de apps web, la regla más limpia es: las variables de entorno son la fuente de verdad. Un archivo .env local puede ser una comodidad para desarrollo, pero tu código debe leer la configuración de la misma forma en todas partes.
Si debes soportar tanto un archivo de config como env vars, establece una prioridad clara (por ejemplo: las env vars sobrescriben los valores del archivo) y documentalo para que no haya sorpresas.
2) Añade una bandera de entorno explícita
Haz que la app anuncie en qué cree que se está ejecutando. Usa una variable como APP_ENV con tres valores permitidos: development, staging, production. Evita adivinar por dominios o por “si debug está en true.”
Cuando el entorno es explícito, puedes tomar decisiones seguras por defecto, como logs verbosos en dev y silenciosos en prod.
Una configuración práctica para la mayoría de equipos:
- Mantén un archivo plantilla commiteado como
.env.exampleque liste cada variable requerida (sin secretos reales). - Usa un
.envlocal solo para conveniencia y mantenlo fuera del control de versiones. - Guarda los valores de staging y producción en las configuraciones de entorno del proveedor de hosting.
- Carga la configuración en un solo lugar (un módulo de config) e impórtalo donde haga falta.
3) Haz que los valores por defecto sean seguros
Los valores por defecto están bien para desarrollo (como una URL de base de datos local). En producción, evita valores por defecto para cosas sensibles. Un DATABASE_URL faltante en producción debe fallar rápido, no volver silenciosamente a algo no intencionado.
4) Documenta lo que tus compañeros necesitan para ejecutar la app
Pon las variables requeridas en un solo lugar (normalmente .env.example más una nota breve en el README). Esto importa todavía más para apps generadas por IA, donde la configuración suele crecer de forma aleatoria y terminar repartida entre código, archivos y paneles.
Valida las env vars al inicio para evitar sorpresas
Muchos problemas de “funciona en mi máquina” ocurren porque la app arranca con configuraciones faltantes o incorrectas y luego falla cuando un usuario accede a una página concreta. Una solución simple es validar las variables de entorno al arrancar la app y negarse a ejecutarla si algo está mal.
Falla rápido con comprobaciones claras
Trata la configuración como datos de entrada. Si faltan valores requeridos, para la app y muestra un error que te diga exactamente qué hay que configurar (sin exponer secretos).
Qué merece la pena validar pronto:
- Presencia: valores obligatorios como
DATABASE_URL,AUTH_SECRET,PORT - Tipo:
PORTes un número,DEBUGes booleano, timeouts son enteros - Formato: las URLs deben tener formato de URL, los emails deben parecer emails
- Reglas entre campos: si
FEATURE_X=true, también requiereFEATURE_X_KEY - Valores permitidos:
APP_ENVes uno dedevelopment,staging,production
Tras la validación, registra un breve resumen de arranque como el nombre del entorno, la versión de la app y qué características opcionales están activas. No imprimas secretos, cadenas de conexión completas ni tokens. Si necesitas confirmación, registra solo que un valor está configurado o una huella segura (por ejemplo, los últimos 4 caracteres).
Añade un comando de auto-test de configuración
Un auto-test de configuración ligero hace que los despliegues sean más seguros porque puedes ejecutarlo antes de iniciar el servidor.
Por ejemplo:
config:testcarga las env vars, las valida y sale con código 0/1- Imprime errores accionables (claves faltantes, tipos erróneos, URLs inválidas)
- Puede confirmar conectividad donde sea seguro (por ejemplo, si puede alcanzar el host de la BD) sin volcar credenciales
Mantén los secretos fuera del código (y de los logs)
Un “secreto” es todo lo que da acceso: claves de API, secretos de cliente OAuth, claves para firmar sesiones, contraseñas de bases de datos, claves privadas de cifrado, secretos de firma de webhooks e incluso algunos tokens internos. Si alguien lo consigue, puede suplantarte a ti o a tu app.
Las apps generadas por IA suelen filtrar secretos en dos lugares: el código y los logs. Una clave se codifica “solo para probar”, una cadena de conexión acaba en un commit o alguien imprime process.env para depurar y olvida quitarlo antes de publicar.
Reglas que evitan la mayoría de incidentes:
- Nunca comites secretos en el repo, ni siquiera “temporales”.
- Nunca envíes secretos al navegador o al cliente móvil. Si el usuario puede verlo, no es secreto.
- Nunca registres secretos o headers completos. Redacta tokens y contraseñas.
- Prefiere tokens de corta vida cuando sea posible.
Si sospechas que una clave se expuso, trátala como comprometida. Rótala y luego confirma que el valor antiguo queda inválido (muchas plataformas mantienen claves antiguas activas hasta que las deshabilitas). También revisa el historial de despliegues, logs y cualquier captura de pantalla o informe compartido.
Usa credenciales separadas por entorno. Dev, staging y prod no deberían compartir el mismo usuario de base de datos, clave de API o secreto de firma. Así, una fuga en staging no desbloquea automáticamente producción.
Haz que staging se parezca a producción (lo suficiente para ser útil)
Staging es donde atrapas problemas que solo aparecen después del despliegue, pero solo funciona si se comporta como producción en los aspectos que importan.
Empieza con builds repetibles. Si staging usa Node 20 pero producción está en Node 18, o un entorno instala versiones distintas de dependencias, no estás probando la misma app. Bloquea la versión de runtime y las dependencias (pincha versiones, commitea tu lockfile y usa el mismo comando de build en todos lados). Evita pasos de instalación específicos por entorno que cambien el comportamiento o salten comprobaciones.
Mantén staging cercano a prod en los caminos críticos: mismo tipo de base de datos, mismo caché o cola si usas uno, y la misma secuencia de inicio (migraciones, seed, workers). No necesita la escala completa ni datos reales, pero debe usar los mismos servicios y el mismo orden de operaciones.
Los health checks son tu sistema de alerta temprana. Un buen despliegue en staging debería fallar rápido si no puede conectar con la base de datos, si hay migraciones pendientes o si faltan env vars requeridas.
Un estándar simple:
- Mismo runtime y lockfile de dependencias en dev, staging y prod
- Mismo artefacto de build promovido de staging a prod (no reconstruido de forma distinta)
- Mismos pasos de arranque (migrar, luego arrancar el proceso web, luego los workers)
- Un health check básico que verifique la conexión a la BD y un par de endpoints clave
- Una huella de configuración por deploy (qué nombres de env var estaban presentes y qué feature flags estaban activadas), sin valores
Errores comunes que causan fallos en runtime
La mayoría de bugs de “ayer funcionaba” no son aleatorios. Suelen venir de deriva de configuración: alguien cambió un ajuste, añadió un hotfix o retocó un secreto en un sitio y luego olvidó documentarlo. Una semana después, un despliegue revierte el código pero no la configuración, y la app rompe de forma que parece misteriosa.
Otro fallo clásico es confiar en archivos locales que no existirán en producción. Tu portátil puede tener una carpeta uploads/ con permisos permisivos, una base de datos SQLite local o un archivo .env que nunca llega al servidor. En producción, el sistema de archivos puede ser de solo lectura, los contenedores pueden reiniciarse en cualquier momento y “ese archivo” simplemente no existe.
Errores que suelen acabar en outages:
- Tratar advertencias como aceptables: env vars faltantes, valores por defecto de respaldo o configuraciones “opcionales” que luego se vuelven obligatorias
- Mezclar variables de entorno de cliente y servidor en apps web, exponiendo secretos o rompiendo builds cuando el navegador no puede leer valores solo para servidor
- Olvidar registrar URLs de callback OAuth o de pago para un entorno
- Asumir que rutas locales existen en todas partes (uploads, directorios temporales, archivos de DB locales, certificados)
- Hacer cambios de configuración de emergencia en el dashboard del hosting y no sincronizar ese cambio con la documentación compartida
Pequeño ejemplo: un fundador tiene un prototipo generado por IA que funciona en un entorno de dev alojado, pero el login en producción falla. La causa raíz es simple: la app vuelve a la URL de callback de dev porque falta la variable de producción. No hay error claro, solo un bucle de redirección.
Lista rápida antes de lanzar
Una rutina previa al envío captura los problemas de configuración más comunes antes que los usuarios.
Ejecuta esto contra el entorno exacto que vas a lanzar (staging para ensayo, producción para la versión real):
- Confirma que todas las variables de entorno requeridas están establecidas (y no vacías). Revisa valores que difieren por entorno: base URLs, claves de API, configuraciones de correo.
- Verifica que la app apunta a la base de datos y al almacenamiento correctos (host/nombre de BD, bucket de almacenamiento, cola, caché). Un valor equivocado puede enviar tráfico de producción a staging.
- Revisa la autenticación de extremo a extremo: URLs de redirección, dominio de cookies, ajustes de sesión, orígenes CORS permitidos.
- Ejecuta la validación de config al arranque antes del release. La app debería negarse a iniciar si falta algo crítico o evidentemente incorrecto.
- Realiza un flujo realista de extremo a extremo en staging: registrarse, iniciar sesión, restablecer contraseña, pagar, subir, exportar, invitar a un compañero.
Si las pruebas en staging pasan pero el login en producción falla, la causa suele ser básica: la URL de redirección apunta al dominio equivocado, el dominio de la cookie está mal o falta un secreto de autenticación.
Ejemplo: limpieza real de configuración en una app generada por IA
Un fundador tenía una app generada por IA que funcionaba localmente pero fallaba justo después del despliegue. El problema no era complicado. En producción había nombres de variable distintos, faltaba un secreto y una URL seguía apuntando a localhost.
Qué falló tras el despliegue
Los usuarios podían abrir el sitio, pero el login fallaba. Los síntomas variaban: a veces pantalla en blanco, a veces un 500 genérico.
Causas raíz:
- URL de callback OAuth todavía apuntando a
http://localhost:3000/... - Un secreto de autenticación requerido (usado para firmar sesiones o tokens) no configurado en producción
- Se usó accidentalmente la URL de la base de datos de staging en producción
Cómo lo arreglamos (sin suposiciones)
Primero auditamos las variables de entorno: todos los valores que la app lee, de dónde vienen y en qué entorno son necesarios. Luego estandarizamos nombres y separamos claramente los valores por dev, staging y prod.
También añadimos guardas para que los fallos aparezcan inmediatamente:
- Validar variables requeridas al arrancar y listar las que faltan
- Validar formatos (por ejemplo, URLs deben ser HTTPS en prod, los secretos deben tener una longitud mínima)
- Bloquear valores por defecto inseguros en producción (no callbacks a localhost, no claves placeholder)
- Registrar pistas seguras solamente (nunca imprimir secretos)
Tras esto, los despliegues se volvieron predecibles. Staging se comportaba como producción en lo que importaba y los problemas aparecían al arranque en lugar de durante el login de un usuario.
Siguientes pasos: endurece tu configuración sin quedarte atascado
No intentes perfeccionarlo todo de una vez. Elige un cambio pequeño que reduzca sorpresas de inmediato, verifícalo localmente y tras el despliegue, y haz una pasada rápida antes del siguiente release.
Buenas victorias "de hoy":
- Añadir un
.env.exampleque liste todas las variables requeridas (con valores de ejemplo seguros) - Añadir validación al arranque para que la app falle rápido cuando falte o esté mal una variable
- Eliminar claves, URLs y flags de debug codificados en el código y moverlos a la configuración de entorno
- Dejar de imprimir secretos en los logs (incluso logs de depuración “temporales”)
- Renombrar variables confusas para que concuerden con lo que realmente hacen
Después, haz una pasada de endurecimiento con tiempo limitado:
- Compara nombres de variables entre dev, staging y prod y asegura que solo difieran los valores
- Revisa las configuraciones de autenticación por entorno (URLs de redirección, ajustes de cookies, callbacks OAuth)
- Confirma que los secretos están en el almacén de secretos de tu plataforma de despliegue, no en el repo
- Haz un despliegue limpio desde cero para detectar variables faltantes y suposiciones
Si heredaste un repo generado por IA y está hecho un lío, empieza con una auditoría de configuración y secretos antes de tocar características. Ahí suelen empezar los valores por defecto ocultos, las fugas y las fallas que solo ocurren tras desplegar.
Si estás atascado, FixMyMess (fixmymess.ai) se especializa en diagnosticar y reparar apps generadas por IA rotas, incluida la deriva de configuración, fallos de autenticación, secretos expuestos y preparación para despliegue. Su auditoría de código gratuita puede ayudarte a ver qué falta y qué arreglar primero.
Preguntas Frecuentes
¿Qué significa realmente “funciona en mi máquina”?
Por lo general significa que el código está bien, pero el entorno es diferente tras el despliegue. Algo que tu portátil proporcionaba automáticamente (variables de entorno, archivos locales, tokens en caché, datos preseeded, una base de datos distinta) no está presente en staging o producción, así que la app falla aunque el repositorio no haya cambiado.
¿Qué debo revisar primero cuando una app falla solo después del despliegue?
Empieza revisando la configuración, no la lógica de negocio. Compara las variables de entorno, las versiones de runtime (por ejemplo Node) y los endpoints de servicio entre tu entorno local y el desplegado, y reproduce el problema con las mismas entradas que ve el servidor.
¿Cuál es el error de configuración más común que causa fallos en despliegues?
Las variables de entorno faltantes o incorrectas son la causa más común. Un signo típico es un error como “DATABASE_URL is undefined”, o funcionalidades que fallan silenciosamente porque una clave no se configuró en producción.
¿Qué debería ser diferente entre dev, staging y producción?
Mantén una sola app con tres conjuntos de valores. Dev es para velocidad, staging es un ensayo que debería comportarse como prod, y prod es la versión en vivo; debes cambiar URLs de servicio, secretos y fuentes de datos por entorno, pero mantener consistente la build, la versión del runtime y los pasos de arranque.
¿Qué debe ir en variables de entorno frente a código o archivos de configuración?
Trata las variables de entorno como entradas que pueden cambiar por entorno o que deben permanecer secretas. Pon reglas de negocio y valores por defecto que no deben cambiar en el código, y guarda configuraciones no secretas y revisables en archivos versionados solo cuando sea seguro exponarlas.
¿Cómo evito confusiones sobre “en qué entorno estoy?”?
Añade una bandera explícita como APP_ENV y permite solo valores reconocibles como development, staging y production. No lo deduzcas por el dominio ni por un toggle de depuración, porque eso crea diferencias de comportamiento ocultas y difíciles de reproducir.
¿Cómo hago para que los problemas con las variables de entorno fallen rápido en vez de fallar después?
Valida al arrancar y rechaza la ejecución cuando falten o estén mal formadas las variables requeridas. Así atraprás problemas antes de que los usuarios reales lleguen a una página rota y el mensaje de error puede indicar exactamente qué hay que configurar sin revelar secretos.
¿Vale la pena añadir un comando config:test a mi app?
Sí. Un pequeño auto-test de configuración es uno de los pasos previos al despliegue más seguros: carga la configuración, valida tipos y formatos, y sale con códigos y errores accionables para detener una mala publicación antes de que arranque el servidor web.
¿Cómo evito que se filtren secretos en apps generadas por IA?
Mantén los secretos fuera del repositorio, del código del cliente y de los logs. Si sospechas que un secreto se expuso, rodéalo inmediatamente y asegúrate de que cada entorno tenga credenciales separadas para que una fuga en staging no desbloquee producción.
¿Cuál es la forma más rápida de estabilizar una app generada por IA que no funciona en producción?
Arregla primero la estructura de configuración: centraliza la carga de config, estandariza nombres de variables y añade validación al arrancar. Si heredaste un repo generado por IA que falla tras el despliegue, FixMyMess puede ejecutar una auditoría gratuita de código y ayudar a reparar deriva de config, problemas de autenticación y prepararlo para producción rápidamente.