SSRF en apps generadas por IA: detectar endpoints y reforzar fetches
El SSRF en apps generadas por IA puede exponer servicios internos. Aprende a localizar endpoints de fetch riesgosos y aplicar allowlists, comprobaciones DNS/IP y endurecimiento de peticiones.
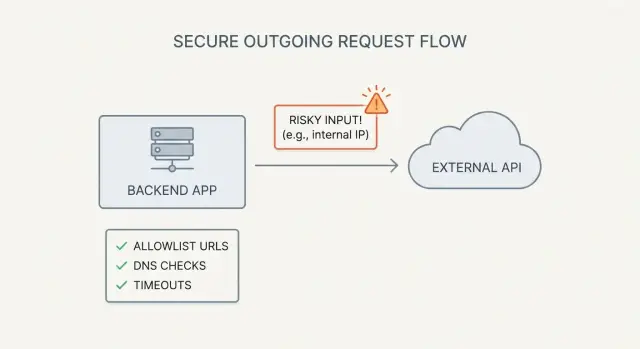
Qué es SSRF (y por qué las apps generadas por IA lo provocan)
SSRF (server-side request forgery) ocurre cuando tu app puede ser engañada para hacer una petición de red para un atacante.
El atacante no necesita acceso a tus servidores. Solo necesita cualquier función que acepte una URL (o hostname) y luego la descargue desde el backend.
Un ejemplo simple: añades un botón “Importar desde URL”. El navegador envía url=https://example.com/data.json a tu API y tu servidor descarga el archivo. Si ese mismo endpoint también acepta http://localhost:3000/admin o http://169.254.169.254/ (metadatos de la nube), tu servidor puede terminar exponiendo datos internos.
Esto aparece constantemente en prototipos generados por IA. A menudo incluyen endpoints de “trae cualquier cosa” (proxies de imagen, vistas previas de enlaces, testers de webhook, generadores de PDF/capturas) porque hacen que las demos se vean completas. Pero se publican sin las medidas que hacen que las descargas server-side sean seguras.
SSRF es peligroso porque los servidores suelen tener acceso que los usuarios no tienen. Un SSRF exitoso puede:
- Alcanzar paneles y servicios internos en
localhosto IPs privadas - Leer endpoints de metadatos de la nube y robar credenciales
- Escanear tu red interna y encontrar puertos y servicios abiertos
- Eludir reglas basadas en IP (porque la petición viene desde tu servidor)
SSRF no es lo mismo que el navegador haciendo peticiones. Si el navegador de un usuario carga una URL directamente, eso es del lado cliente. SSRF es específicamente tu backend (o una función serverless) haciendo el fetch, con tu acceso de red y tus secretos.
Dónde suele esconderse SSRF: endpoints a revisar
SSRF suele esconderse en cualquier lugar donde el servidor descargue una URL que el usuario pueda influir. Estos endpoints parecen inofensivos porque “solo están trayendo contenido”, pero pueden usarse para alcanzar servicios internos, metadatos de la nube u otros destinos privados.
Empieza por listar las funciones del producto que aceptan una URL, directa o indirectamente. Lugares comunes: vistas previas de enlaces, herramientas de importar desde URL (CSV/JSON/plantillas), testers de webhook, proxies de archivos e imágenes, y lectores de RSS/feeds.
Revisa también herramientas solo para admins. Las apps generadas por IA suelen incluir páginas rápidas de “comprobar conexión”, checks de salud que hacen ping a dependencias, o pantallas de configuración de integraciones que verifican una URL. Son de alto riesgo porque pueden ejecutarse con acceso de red elevado y saltarse validaciones normales.
No olvides las descargas retrasadas. Jobs en background, colas y tareas cron pueden almacenar una URL ahora y descargarla después. Ese desfase puede hacer que el bug sea más difícil de detectar.
Cuando busques en el código (y en los logs de peticiones), vigila nombres de parámetros que suelen llevar URLs, incluso si suenan inocentes: url, callback, avatarUrl, webhookUrl, redirect.
Un ejemplo concreto: una opción “foto de perfil desde URL” podría descargar la imagen server-side para redimensionarla. Si el endpoint acepta avatarUrl sin comprobaciones estrictas, un atacante puede apuntarlo a una dirección interna y usar la descarga de la imagen como túnel.
Un modelo de amenazas rápido para abuso de fetch server-side
Antes de arreglar nada, aclara qué está intentando alcanzar el atacante.
Primero, mapea qué puede alcanzar tu servidor desde su red. Normalmente incluye servicios en localhost (paneles admin, puertos de debug), rangos IP privados dentro de tu VPC y endpoints de metadatos del proveedor de la nube que pueden entregar credenciales. Si la app corre en un contenedor, incluye nombres de servicios internos y sidecars.
Después, decide qué debes proteger. Los premios mayores son secretos y tokens (API keys, secretos de sesión), credenciales de base de datos, dashboards internos y cualquier servicio que confíe en peticiones provenientes de dentro de tu red.
Finalmente, escribe el perímetro para cada función de fetch server-side:
- Quién puede activarlo (público, usuario, admin)
- Qué se le permite descargar (dominios concretos o una lista pequeña de partners)
- Qué nunca debe ser alcanzable (localhost, IPs privadas, metadatos)
- Para qué se usa la respuesta (archivo almacenado, datos parseados, HTML renderizado)
Si heredaste un prototipo de herramientas como Bolt o Replit, este modelo de amenazas rápido es un buen primer paso antes de una auditoría más profunda.
Paso a paso: encuentra cada fetch server-side en tu código
SSRF suele empezar con una función simple: “descarga esta URL”, “importa desde enlace”, “previsualiza un webhook” o “comprueba si este sitio está arriba”. Antes de añadir defensas, necesitas un inventario completo de todos los lugares donde tu servidor hace peticiones salientes.
1) Busca peticiones salientes (incluidos wrappers)
Empieza con una búsqueda de texto en el repo. Busca clientes HTTP comunes y helpers, no solo fetch.
- JavaScript/Node:
fetch,axios,got,superagent,node-fetch - Python:
requests,httpx,urllib,aiohttp - Ruby:
Net::HTTP,Faraday - Wrappers de shell:
curl,wget,exec(,spawn(
También busca palabras que suelen rodear estas funciones: “webhook”, “callback”, “import”, “download”, “proxy”, “scrape”.
Si la app fue generada por herramientas como Lovable, Bolt, v0, Cursor o Replit, busca módulos helper que oculten llamadas de red bajo nombres como getUrlContent() o scrapePage().
2) Traza de dónde viene la URL
Para cada sitio de llamada, sigue la variable hacia atrás hasta llegar a la fuente. Fuentes comunes: campos del body de la petición, parámetros de query, cabeceras, filas de base de datos, variables de entorno y strings de plantilla que combinan entrada de usuario con una URL base.
Presta atención al control indirecto, como un subdominio controlado por el usuario, un baseUrl por tenant o un ID que mapea a una URL en la base de datos.
3) Comprueba caminos ocultos de fetch
Confirma si el cliente sigue redirecciones, resuelve enlaces cortos o reintenta con URLs alternativas. Una petición que parece segura puede volverse insegura tras un 302 hacia un host interno.
4) Confirma el comportamiento y documéntalo
Provoca fallos a propósito (dominio inválido, timeout, respuesta grande) y observa qué pasa: qué se registra en logs, qué texto de error se devuelve y si algún dato de la respuesta se refleja al usuario.
Documenta cada endpoint con sus entradas, salidas, requisitos de auth y dominios destino previstos. Este inventario será tu plan de corrección SSRF.
Allowlists que funcionan: valida host, esquema y puerto
Las listas negras fallan porque las reglas de URL son complejas y los atacantes perseveran. Una allowlist estricta de destinos conocidos es la opción más segura por defecto, especialmente cuando una función permite a usuarios descargar o importar contenido desde una URL.
Parsea y normaliza la URL antes de compararla con cualquier regla. No compruebes la cadena cruda. Descomponla en esquema, hostname, puerto y path. Compara el hostname normalizado y el puerto efectivo (incluidos los por defecto como 443 para https).
Un flujo práctico de allowlist:
- Parsear la URL con un parser real (no regex)
- Exigir el esquema https (o http solo si realmente lo necesitas)
- Exigir un hostname (evitar IPs a menos que las permitas explícitamente)
- Permitir solo puertos aprobados (usualmente 443, a veces 80)
- Hacer match del hostname contra tus reglas de allowlist
Esquemas y puertos son vías comunes de escape. Si validas solo el dominio pero olvidas el esquema, un atacante puede probar handlers inesperados en algunos entornos. Si permites cualquier puerto, el atacante puede sondear servicios internos en puertos raros aunque el host parezca aceptable.
Los subdominios también necesitan reglas claras. La coincidencia exacta es la más sencilla (solo api.example.com). Si debes usar wildcards, aplica un límite real para que example.com.evil.com no se cuele.
Trata la allowlist como configuración centralizada, no código disperso. Manténla en un solo lugar y registra qué regla hizo match para facilitar revisiones y evitar excepciones que se queden por ahí.
Protecciones DNS: evita rebinding y trucos de IP internas
DNS rebinding es un truco simple con un resultado desagradable. Tu app valida una URL como https://example.com/image.png. Parece inofensiva. Pero el atacante controla example.com y puede cambiar a qué resuelve después de tus comprobaciones. Para cuando tu servidor conecte, ese hostname puede apuntar a 127.0.0.1 o a una IP de metadatos.
Por eso las comprobaciones básicas del hostname no bastan.
Un patrón más seguro es resolver el hostname tú mismo, comprobar cada IP devuelta y conectar solo si todas son seguras.
Qué bloquear (IPv4 e IPv6)
Al resolver el hostname, rechaza cualquier dirección en rangos privados o especiales, incluyendo redes privadas (RFC1918) y ULA de IPv6, loopback (127.0.0.1, ::1), link-local (169.254.0.0/16, fe80::/10), rangos reservados/indefinidos (como 0.0.0.0, ::) y formas IPv4-mapeadas en IPv6.
Comprueba todos los registros devueltos, no solo el primero. Los atacantes suelen depender de múltiples registros A/AAAA donde uno parece público (pasa la validación) y otro es interno.
Volver a comprobar cerca de la conexión
Si tu cliente HTTP lo permite, resuelve y valida justo antes de abrir el socket y evita búsquedas DNS posteriores durante redirecciones. Si no puedes controlarlo, reduce al mínimo el tiempo entre la validación y la descarga.
Endurecimiento de peticiones: timeouts, redirecciones y valores seguros
Incluso con una buena allowlist, los clientes HTTP server-side suelen ser demasiado permisivos por defecto. El objetivo es claro: fallar rápido, bajar la cantidad de datos descargados y nunca seguir redirecciones hacia sitios no previstos.
Empieza por establecer límites estrictos en cada fetch server-side. Si una petición es lenta, grande o ambigua, trátala como sospechosa y deténla.
Valores por defecto más seguros para fetch server-side
Un baseline práctico:
- Establecer timeouts estrictos (conect y lectura separados) y limitar el tamaño de la respuesta.
- Desactivar redirecciones para URLs suministradas por usuarios, o permitir solo una redirección si el destino final se revalida.
- Restringir métodos a GET (y quizá HEAD).
- Quitar cabeceras sensibles. No adjuntes cookies, API keys o tokens internos a solicitudes externas.
- Registrar un resumen corto (host, path, status, tiempo). Evita registrar URLs completas si pueden contener secretos.
Un patrón de fallo común: una función “previsualiza esta URL” permite redirecciones. Un atacante envía una URL que 302-redirige a un panel admin interno o a una dirección de metadatos de la nube. Tu app la sigue y, por accidente, reenvía una cabecera Authorization que se reutiliza para llamadas internas.
Errores: mantener al usuario seguro, mantener informados a los ingenieros
Cuando una descarga se bloquea o falla, muestra un mensaje genérico al usuario (por ejemplo, “No se pudo obtener esa URL”). Pon la razón detallada (timeout vs redirect vs host bloqueado) solo en logs internos. Los errores demasiado detallados en la UI suelen enseñar a los atacantes qué reglas usas.
Errores comunes que siguen dejando SSRF abierto
Los bugs SSRF suelen sobrevivir a arreglos “básicos”. El resultado parece protegido, pero un atacante aún puede hacer que tu servidor hable con servicios internos o metadatos.
Muchos equipos empiezan con comprobaciones de cadena como startsWith('https://'). Eso falla con URLs trucadas, codificaciones inusuales o URLs que parecen seguras pero resuelven a destinos peligrosos.
Otros fallos comunes:
- Permitir redirecciones sin volver a validar cada salto
- Validar el host y luego conectar usando un valor diferente más tarde
- Bloquear solo
127.0.0.1y olvidar loopback en IPv6 (::1),0.0.0.0y rangos privados como10.*,172.16.*,192.168.* - Omitir defensas contra DNS rebinding (validar una vez y descargar después)
Si devuelves el contenido descargado directamente al navegador, puedes crear un segundo problema: tu servidor se convierte en un proxy. Sin límites estrictos, atacantes pueden bajar archivos enormes para generar costes o enviar tipos de contenido inesperados que tu frontend no maneje.
Checklist rápido pre-lanzamiento para defensas SSRF
Antes de lanzar, asume que alguien intentará convertir cualquier fetch server-side en un túnel.
Haz inventario de cada lugar donde un usuario (u otro sistema) puede influir una URL, host o referencia a un archivo remoto. Incluye campos obvios como “importar desde URL”, además de testers de webhook, previsualizadores de imagen, generadores de PDF, lectores de feeds, funciones de “comprueba mi web” e integraciones que aceptan callback URLs.
En staging, valida unos esenciales:
- Cada endpoint y job en segundo plano que acepte una URL/hostname está listado.
- La allowlist se aplica en el servidor para cada descarga (no solo en la UI).
- Esquema, host y puerto se validan antes de la petición.
- Comprobaciones DNS/IP bloquean rangos internos para IPv4 e IPv6, y la comprobación ocurre cerca de la conexión.
- Timeouts, límites de tamaño de respuesta y reglas de redirección están en su lugar.
Para pruebas simples de “objetivos malos”, intenta localhost, una IP privada, un hostname interno usado en tu entorno y la dirección común de metadatos de la nube. No buscas explotar nada, solo confirmar que tu app rechaza la petición y no filtra detalles útiles en errores hacia el usuario.
Ejemplo: arreglar de forma segura una función “importar desde URL”
Un patrón común es una función de conveniencia como “Importar avatar desde URL”. Un generador añade un endpoint backend que toma una URL, descarga la imagen server-side y la almacena.
La vía de explotación es predecible. Un atacante envía una URL que no es de un host de imágenes, sino una dirección interna como un servicio de metadatos, un panel admin o un puerto HTTP de base de datos expuesto solo dentro de tu red. Si tu servidor lo descarga, el atacante puede obtener secretos, hostnames internos o incluso HTML si almacenas o previsualizas la respuesta.
Haz la descarga aburrida y estricta:
- Allowlist solo hosts específicos de imágenes que controlas o en los que confíes.
- Exige https y bloquea puertos no estándar.
- Resuelve el DNS tú mismo y bloquea IPs privadas, loopback y link-local antes de conectar.
- Desactiva redirecciones, o permite una sola redirección que aún pase la validación.
- Establece timeouts reducidos y un tamaño máximo de descarga pequeño, y verifica el content-type y los bytes mágicos.
Añade monitorización para detectar sondeos. A menudo aparece como muchas peticiones fallidas a distintos hosts, intentos repetidos de alcanzar 169.254.169.254 o localhost, o picos en resultados DNS bloqueados y redirecciones bloqueadas.
Próximos pasos: simplifica las funciones de fetch y pide una revisión focalizada
Si encontraste aunque sea un fetch server-side que puede recibir una URL proporcionada por el usuario, asume que hay más. La reducción de riesgo más rápida es reducir la superficie.
Decide qué funciones de fetch realmente necesitas. Muchas apps incluyen extras como “importar desde URL”, “previsualizar enlace”, “obtener Open Graph”, “tester de webhooks”, “proxy de imágenes” o “conectar a cualquier API”. Cada una es un posible punto de entrada para SSRF. Si una función no es esencial, eliminarla suele ser más seguro que endurecerla para siempre.
Luego establece unas reglas que deben cumplirse para cada fetch server-side:
- Solo se permiten esquemas, puertos y hosts aprobados (nada de “cualquier URL”).
- Las comprobaciones DNS e IP ocurren en el momento de la petición, no solo una vez durante la validación.
- Timeouts, límites de tamaño y límites de redirección están siempre activados.
- Las descargas se centralizan en un helper para que nuevos endpoints no puedan eludir las protecciones.
Si quieres una revisión rápida de un codebase generado por IA, FixMyMess (fixmymess.ai) hace diagnóstico de código y endurecimiento de seguridad para prototipos construidos con herramientas como Lovable, Bolt, v0, Cursor y Replit. También ofrecen una auditoría de código gratuita para identificar rápidamente riesgos de fetch estilo SSRF y otros problemas críticos antes de que publiques.
Preguntas Frecuentes
¿Qué es SSRF en lenguaje sencillo?
SSRF ocurre cuando tu backend (o una función serverless) puede ser engañado para descargar una URL controlada por un atacante. Como la petición sale desde tu servidor, puede alcanzar servicios internos, IPs privadas o metadatos de la nube a los que un usuario normal no tiene acceso.
¿Por qué las apps creadas por IA suelen tener bugs de SSRF?
Los prototipos generados por IA suelen añadir funciones “convenientes” que hacen fetch del lado servidor, como vistas previas de enlaces, proxies de imágenes, importación desde URL, testers de webhooks o generadores de capturas/PDF. Funcionan en demos, pero normalmente se publican sin allowlists estrictas, comprobaciones DNS/IP ni control de redirecciones.
¿Qué endpoints debo revisar primero por SSRF?
Revisa cualquier endpoint o job que acepte campos como url, webhookUrl, callback, avatarUrl, redirect o una dirección usada para “probar integraciones”. También examina workers en segundo plano y tareas cron que guarden una URL ahora y la descarguen después, porque ahí puede esconderse el SSRF fuera de las rutas de petición normales.
¿Cómo encuentro todas las peticiones server-side en mi código?
Empieza por inventariar todas las salidas HTTP que puede hacer tu servidor buscando clientes HTTP (por ejemplo fetch/axios/requests) y cualquier helper interno que los envuelva. Para cada llamada, rastrea de dónde viene la URL y verifica si la entrada del usuario puede influir en alguna parte, incluso indirectamente mediante campos de la base de datos o configuración por tenant.
¿Debo usar allowlist o blocklist para prevenir SSRF?
Preferible una allowlist. Rechaza todo lo que no esté explícitamente aprobado. Parse y normaliza la URL con un parser real, exige https y permite solo puertos seguros (usualmente 443, a veces 80) para que los atacantes no puedan usar puertos raros para sondear servicios internos.
¿Cómo me protejo contra DNS rebinding y trucos que resuelven a localhost?
DNS puede cambiar después de validar el hostname. Resuelve el nombre tú mismo, revisa cada IP que devuelva y rechaza rangos privados, loopback y link-local tanto en IPv4 como en IPv6. Haz esta comprobación lo más cerca posible de la conexión real, no solo una vez durante la validación inicial.
¿Cuáles son las configuraciones más seguras para peticiones HTTP server-side?
Endurece timeouts, limita el tamaño de la respuesta y considera las redirecciones peligrosas para URLs proporcionadas por usuarios. El valor por defecto más seguro es no seguir redirecciones; si debes permitirlas, vuelve a validar el destino tras cada salto y nunca reenvíes cabeceras de autenticación o cookies internas.
¿Qué “arreglos” comunes siguen dejando SSRF?
Comprobaciones de strings como startsWith('https://') y reglas simples de “bloquear localhost” fallan en muchos casos: IPv6 loopback, rangos privados, redirecciones y cambios DNS entre validación y conexión siguen siendo vectores. Otro error frecuente es validar un host y luego conectar usando otro valor derivado después.
¿Cómo puedo probar rápidamente si mis defensas SSRF funcionan?
Prueba objetivos conocidos malos como localhost, rangos IP privados y la IP de metadatos de la nube, y confirma que tu app los bloquea sin filtrar detalles en los errores que ve el usuario. También prueba el comportamiento con redirecciones para asegurarte de que el destino final se valida y no solo la URL inicial.
¿Puede FixMyMess ayudar a endurecer un código generado por IA contra SSRF?
Si tu app fue generada por herramientas como Lovable, Bolt, v0, Cursor o Replit, es común dejar algún camino de fetch oculto o un job en segundo plano. FixMyMess puede ejecutar una auditoría de código gratuita para inventariar fetches server-side, endurecer el código (allowlists, comprobaciones DNS/IP, reglas de redirección, timeouts) y ayudarte a dejarlo listo para producción.