Subidas directas a almacenamiento de objetos que evitan timeouts
Las subidas directas a almacenamiento de objetos evitan timeouts enviando archivos grandes directamente al almacenamiento, usando URLs firmadas y pasos reanudables para mantener las apps responsivas.
Por qué las subidas grandes fallan en aplicaciones reales
Los usuarios lo notan rápido: la barra de progreso llega al 90% y se queda congelada. Actualizan, lo intentan otra vez y falla en otro punto. En móvil o con Wi‑Fi inestable, empieza a sentirse como jugar a la lotería, incluso cuando el archivo está bien.
Cuando las subidas fallan, la gente no solo pierde tiempo. Pierde confianza. Un creador que pasó 20 minutos exportando un video no va a aceptar con gusto volver a subirlo tres veces. Un reclutador que adjunta un portafolio grande abandonará el formulario. Y tu equipo recibe las consecuencias: "Está atascado", "Dice que falló", "¿Dónde quedó mi archivo?"
Los reintentos suelen empeorar las cosas. Muchos sistemas vuelven a empezar desde cero, consumen ancho de banda y dejan archivos duplicados "casi subidos" o registros de base de datos a medio hacer. Si tu app guarda metadatos antes de que la subida termine de verdad, acabas con entradas que parecen reales pero no apuntan a nada.
Las subidas grandes ponen a prueba las partes más débiles de una pila típica. Las conexiones de larga duración agotan los tiempos, los proxies y balanceadores cortan solicitudes, y los servidores disparan CPU y memoria si hacen buffering de grandes cargas. Una subida lenta puede ocupar recursos destinados a todos.
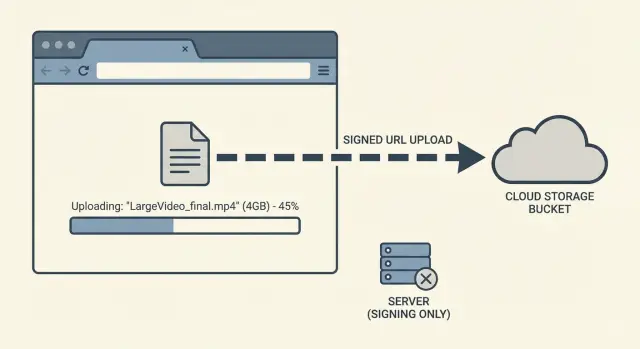
El objetivo es sencillo: hacer que los archivos grandes se suban de forma fiable sin convertir tu servidor en un intermediario frágil. Las subidas directas al almacenamiento de objetos lo consiguen. En vez de empujar gigabytes a través del backend, el dispositivo del usuario sube directamente al almacenamiento. Tu app se concentra en permisos, seguimiento y confirmar el resultado final.
Aquí es donde los prototipos suelen fallar: "funciona con archivos pequeños" y luego se hunde en producción.
Qué suele provocar timeouts en las subidas
La mayoría de los timeouts ocurren porque tu servidor actúa como retransmisor. El navegador envía un archivo enorme a tu servidor, tu servidor mantiene esa conexión abierta y después reenvía los mismos bytes al almacenamiento de objetos. Si el usuario es lento, el servidor se queda esperando. Mientras tanto, memoria y CPU suben y otras solicitudes empiezan a fallar.
Los timeouts también pueden venir de cualquier punto del trayecto. Un único límite es suficiente para matar una subida aunque el resto esté bien: la pestaña del navegador (segundero en segundo plano, reposo, cambio de red), un proxy o balanceador con límite duro de petición, timeouts de workers en tu servidor, límites de tamaño y parsing del framework, o la propia llamada al cliente de almacenamiento.
La reacción habitual es "simplemente aumenta el timeout". Eso puede darte un día más, pero rara vez arregla la causa raíz. Timeouts más largos significan más conexiones de larga duración, y la sobrecarga es más probable. Una persona subiendo un video de 2 GB en Wi‑Fi inestable puede ocupar un worker durante minutos y de pronto los usuarios normales ven páginas lentas o inicios de sesión fallidos.
Imagina un escenario común: un usuario sube desde el Wi‑Fi de una cafetería. A mitad de camino la conexión cae 10 segundos. El navegador reintenta, tu servidor sigue con una petición a medio terminar, un proxy la mata a los 60 segundos y el usuario recibe "Subida fallida" sin explicación clara.
Las subidas directas al almacenamiento ayudan porque eliminan a tu servidor de la ruta de datos pesada.
Qué significa subir directo a almacenamiento de objetos (en palabras sencillas)
Subir directo a almacenamiento de objetos significa que el archivo va desde el dispositivo del usuario (navegador o app móvil) directamente al bucket de almacenamiento, en lugar de pasar primero por tu servidor. Tu app sigue coordinando, pero no transporta los bytes del archivo.
Piénsalo así: tu servidor le da al usuario un permiso temporal y de un solo uso. El usuario lo utiliza para subir directamente al almacenamiento. Ese permiso puede limitarse a un solo archivo, un destino concreto y una ventana de tiempo corta.
En la práctica, tu backend hace tres tareas pequeñas:
- confirmar que el usuario puede subir
- crear el permiso de subida de corta duración (a menudo una URL firmada)
- registrar metadatos y luego verificar que la subida terminó
La ganancia es inmediata: menos timeouts, menos presión de ancho de banda en el servidor y una experiencia más fluida. Los servicios de almacenamiento están hechos para aceptar muchas subidas grandes a la vez.
Un ejemplo simple: un fundador prueba subiendo un video demo grande. Con "subir a través de mi servidor", la petición puede morir a los 60 segundos, 120 segundos o cuando un proxy decida que ya esperó suficiente. Con el enfoque directo, el navegador sube al almacenamiento y tu app solo maneja una petición corta de "iniciar" y otra de "confirmar".
Subidas firmadas: la forma segura de dejar que los usuarios suban directamente
Una subida firmada es ese permiso de corta duración que tu backend crea para que un usuario pueda subir un archivo al almacenamiento sin que tu servidor quede en medio.
La parte "firmada" importa porque la URL (o los campos del formulario) incluye la prueba de que tu backend aprobó la subida bajo reglas específicas. Si alguien copia la URL después, debería ser inútil porque expira rápido y solo permite una acción concreta.
Qué límites debe incluir una subida firmada
Las subidas firmadas deben ser estrictas por defecto. Buenos límites incluyen un tiempo de expiración (minutos, no horas), un tope rígido de tamaño de archivo, tipos de contenido permitidos (por ejemplo, video/mp4 o image/png) y una clave de destino o patrón de ruta bloqueado para que los usuarios no sobrescriban otros archivos. Si dependes de metadatos (como un ID de propietario), valídalo también.
Un flujo típico: el usuario selecciona un video de 1 GB. Tu backend revisa su cuenta y el tipo y tamaño esperados. Luego devuelve una URL firmada válida, por ejemplo, 10 minutos. El navegador sube directamente al almacenamiento y tu backend recibe un pequeño mensaje de "subida completada" después.
Subida de una sola vez vs subidas multipartes
Usa una URL firmada de una sola vez cuando los archivos sean lo bastante pequeños como para que una sola petición usualmente termine y no necesites reanudar.
Para archivos grandes, prefiere subidas multipartes. Multipart divide el archivo en fragmentos para que solo reintentes la parte que falló en vez de reiniciar todo. A menudo esa es la diferencia entre "funciona en la red de la oficina" y fiabilidad real.
Estrategias reanudables que sobreviven conexiones inestables
Las subidas grandes fallan por razones aburridas: el Wi‑Fi cae, un portátil se suspende, un móvil cambia de red. Si tu subida depende de una sola petición larga, cualquier tropiezo puede obligar al usuario a empezar de nuevo.
Las subidas reanudables arreglan eso al convertir una transferencia frágil en muchas transferencias pequeñas y reintentables. Esto encaja naturalmente con las subidas directas a almacenamiento porque tu servidor no está vigilando un archivo enorme durante minutos.
Cómo funcionan las subidas reanudables
En vez de enviar todo el archivo a la vez, el cliente lo divide en partes (chunks). Cada parte se sube por separado y el sistema registra lo que llegó.
Un enfoque simple:
- divide el archivo en chunks de tamaño fijo (por ejemplo, 5‑25 MB cada uno)
- sube los chunks en orden (o varios en paralelo) y registra los números de chunks completados
- reintenta solo los chunks que fallen, con backoff (esperar un poco más en cada reintento)
- reanuda más tarde preguntando: "¿Qué chunks ya tienes?" y continúa
- finaliza diciendo al almacenamiento que una los fragmentos en un único objeto
Si el navegador se cierra o el dispositivo duerme, la siguiente sesión puede continuar desde el último chunk confirmado.
Qué deben experimentar los usuarios
Reanudable no es solo una decisión de backend. Cambia la sensación de la subida. Los usuarios deben ver un progreso basado en chunks confirmados y tener controles que reflejen la vida real: pausar, reanudar y un estado claro de "reconectando" cuando la red falla.
Ejemplo: alguien sube un video de 3 GB en un tren. La conexión cae dos veces. Con subidas reanudables, solo reenvía dos chunks perdidos, el progreso sigue siendo creíble y la subida termina sin la frustración de "empezar de 0%".
Paso a paso: un flujo de subida fiable que puedes implementar
Un flujo fiable mantiene a tu servidor fuera de la ruta de datos. Tu servidor establece las reglas y confirma resultados. El navegador envía el archivo directo al almacenamiento.
Una secuencia práctica:
- El cliente pide subir (solo metadatos). Envía nombre de archivo, tamaño, tipo y contexto (proyecto, usuario), pero no el archivo.
- El servidor valida y devuelve info de subida firmada. Aplica límites, crea un registro provisional en la base de datos y devuelve la información firmada más un ID/clave de subida.
- El navegador sube directamente y muestra progreso. Subida desde el cliente al almacenamiento y actualización del progreso. Si soportas chunking, guarda el estado de los chunks localmente para que una actualización pueda continuar.
- El cliente confirma la finalización. Tras el éxito en almacenamiento, el cliente llama a tu servidor con el ID/clave y el tamaño esperado.
- El servidor verifica y finaliza. Confirma que el objeto existe, coincide en tamaño/tipo y pertenece al usuario correcto. Luego marca el registro como listo.
Un pequeño detalle que evita mucho dolor: trata la subida como una máquina de estados. "Borrador" no es "listo". Solo cambia a "listo" después de la verificación del servidor.
Mantén el trabajo posterior fuera de la petición de subida. Encola tareas como miniaturas, escaneo antivirus o transcodificación para que los usuarios no esperen y los timeouts no se acumulen.
Hacer que las subidas inspiren confianza en los usuarios
La gente perdona una subida lenta. No perdona una confusa. Incluso con subidas directas al almacenamiento, la conexión suele ser el eslabón débil, así que tu interfaz debe poner expectativas y cumplirlas.
Haz que el progreso parezca honesto. Un porcentaje solo puede engañar en archivos grandes porque la velocidad cambia. Muestra tamaño subido de total y considera "tiempo restante" como una estimación. Si la subida está estancada, dilo. "Pausado, intentando reconectar" es mejor que un 72% congelado.
Un patrón simple:
- muestra MB subidos de MB totales y la velocidad actual
- muestra una ETA solo después de unos segundos de transferencia estable
- detecta ausencia de progreso durante N segundos y cambia a "reconectando"
- ofrece una acción clara de "Pausar" o "Reintentar"
Las subidas también parecen más seguras cuando sobreviven comportamientos normales. Si alguien actualiza, cierra la pestaña o su portátil se suspende, conserva suficiente estado local (nombre, tamaño, ID de sesión de subida, partes completadas) para reanudar en vez de reiniciar.
Cuando ocurren errores, sé específico y ofrece el siguiente paso. "Subida fallida" no sirve. "Tu conexión se cortó. Guardamos tu progreso. Haz clic en Reanudar." tranquiliza. Si el usuario eligió el tipo equivocado o superó un límite, indica qué está permitido.
La accesibilidad importa porque el estado de la subida depende del tiempo. Usa texto de estado legible (no solo color), mantén el foco en la acción que el usuario pulsó y anuncia cambios clave (inició, pausado, reanudado, completado) para que usuarios de teclado y lectores de pantalla no queden desorientados.
Errores comunes y trampas que evitar
La gran trampa con subidas directas al almacenamiento es asumir "el navegador lo manejó, así que ya está". El almacenamiento es fiable, pero tu app aún debe controlar el acceso, confirmar la finalización y mantener la base de datos consistente.
Confiar demasiado en el navegador
Una subida firmada prueba que el usuario tenía permiso al inicio. No prueba qué subieron ni que la subida terminó.
Después de la subida, verifica en tu servidor que el objeto existe y coincide en tamaño y tipo esperado, que aterrizó en el prefijo correcto para ese usuario o proyecto, y que cualquier metadato que uses coincide. Solo entonces marca la subida como "lista".
URLs firmadas demasiado permisivas
Algunos sistemas "arreglan" timeouts haciendo que las URLs firmadas duren horas y permitan cualquier archivo. Eso es arriesgado. Mantén la URL de corta duración y con alcance estrecho: limita tamaño, MIME types y bloquea la ruta de destino.
Registros de subidas que nunca terminaron
Si creas un registro en la base de datos como "subido" antes de la confirmación, acumularás entradas rotas y archivos faltantes. Créalo como "pendiente" y cambia a "subido" solo después de confirmar que el objeto existe (o tras un evento de callback del almacenamiento si usas uno).
Procesamiento pesado en línea
No hagas esperar al usuario mientras transcodificas video, escaneas archivos o generas miniaturas. Acepta la subida, confírmala y luego encola el procesamiento en segundo plano y muestra un estado claro. Esto mantiene la ruta de subida rápida y predecible.
Enviar archivos por error a través de tu API
Si tu frontend vuelve a la opción de enviar el archivo a tu API cuando falla la subida directa, vuelves a sufrir timeouts. Mantén la autenticación y el tráfico de control en tu API, pero deja que los bytes del archivo vayan directo al almacenamiento.
Lista rápida antes de lanzar
Antes de declarar la función de subida como "lista", revisa rápidamente fiabilidad y seguridad. La mayoría de errores en subidas aparecen cuando usuarios reales intentan archivos grandes en Wi‑Fi inestable o cuando el trabajo en segundo plano tarda más que el timeout HTTP.
- La reanudación funciona sin empezar de nuevo. Si la conexión cae al 80%, el usuario debe continuar desde donde quedó.
- Los límites se aplican antes de dar permiso. Revisa tipo y tamaño temprano y rehúsa emitir permiso para archivos que no aceptarás.
- Los permisos firmados son de corta duración y con alcance limitado. Un archivo, una ruta, un método. No "sube cualquier cosa a cualquier sitio".
- La finalización se verifica en el almacenamiento. No marques una subida como "hecha" porque el cliente lo dijo.
- El trabajo pesado se mueve fuera de la petición de subida. Convierte, escanea, OCRa y genera miniaturas después de la subida.
Si el procesamiento tarda, muestra dos estados separados: "Subido" y "Procesando". Los usuarios confían en sistemas que explican lo que ocurre.
Un ejemplo realista: una subida grande que no falla
Un creador está en una cafetería intentando subir un video de 3 GB. El Wi‑Fi cae unos segundos de vez en cuando y su portátil se suspende una vez. Aun así espera que la subida termine sin empezar de nuevo.
Con el enfoque antiguo, el navegador sube todo el archivo a tu servidor, luego tu servidor lo reenvía al almacenamiento. Tras 30 a 120 segundos (según tu configuración), algo hace timeout: balanceador, proxy inverso, límite serverless o una petición lenta. El usuario ve un error, refresca y la subida reinicia desde 0%. Soporte recibe "Lo intenté tres veces y nunca funciona."
Ahora compáralo con subidas directas a almacenamiento usando una URL firmada más subidas reanudables. Tu servidor solo da permiso temporal y un plan de subida. El navegador envía el archivo directamente al almacenamiento en partes (por ejemplo, chunks de 10‑50 MB). Cuando falla el Wi‑Fi de la cafetería, solo la parte actual cae.
En vez de perder todo, el cliente reintenta el chunk fallido, continúa desde la última parte confirmada, mantiene el progreso realista y finaliza aunque la conexión sea imperfecta.
Tu equipo de producto puede medir la diferencia rápidamente: tasa de completado de subidas, reintentos promedio por subida y tiempo hasta el primer activo reproducible o procesable. La mejor señal son menos tickets de soporte sobre "subidas atascadas" o "subidas que reinician", porque el sistema se recupera en silencio y tu servidor sigue respondiendo.
Siguientes pasos si tu flujo de subidas actual es un desastre
Si las subidas ya son inestables, no rehagas todo de golpe. Las victorias rápidas vienen de reducir el alcance, hacer visibles los fallos y eliminar la parte más arriesgada (tu servidor proxy enviando archivos grandes).
Empieza con un tipo de subida, como videos o PDFs. Elige el que causa más tickets de soporte o son los archivos más grandes. Mantén la ruta antigua para otros tipos hasta que la nueva demuestre su eficacia.
Antes de cambiar comportamiento, añade seguimiento básico para ver qué falla. Los timeouts suelen ocultar múltiples problemas: redes lentas, tormentas de reintentos, CORS mal configurado, tokens expirados y usuarios que abandonan la pestaña.
Un plan de limpieza que funciona:
- migra una pantalla y un tipo de archivo a subidas directas al almacenamiento
- registra inicio de subida, bytes enviados, completado y una razón clara de fallo
- confirma tus límites de autenticación: crea permisos firmados de corta duración, nunca envíes claves de larga vida al navegador
- elimina secretos expuestos y lógica enredada (claves hardcodeadas, endpoints duplicados, responsabilidades mezcladas, bucles de reintento infinitos)
- centraliza el flujo de subida (un módulo cliente, un endpoint API que emite firmas)
Si heredaste una app generada por IA, dedica tiempo extra a autenticación y manejo de secretos. "Funciona en mi máquina" a menudo omite comprobaciones del lado servidor o acopla subidas al servidor de formas que colapsan bajo tráfico real.
Si quieres una segunda opinión, FixMyMess (fixmymess.ai) puede ejecutar una auditoría de código gratuita para encontrar problemas de subida y seguridad, y luego ayudar a reparar el flujo para que sea apto para producción.
Preguntas Frecuentes
Why do large uploads fail even when my server seems fine?
La mayoría de las fallas ocurren porque la subida pasa primero por tu servidor de aplicación. Eso crea una petición de larga duración que puede ser cortada por el navegador, un proxy, un balanceador de carga, un límite serverless o el timeout del propio trabajador del servidor. Mover los bytes fuera del backend (subidas directas a almacenamiento de objetos) elimina la parte más frágil del trayecto.
What exactly should my backend do in a direct-to-object-storage upload flow?
Tu servidor solo debe encargarse de permisos, seguimiento y verificación. Puede validar al usuario, crear un permiso de subida firmado y de corta duración, crear un registro provisional en la base de datos y finalizarlo después de verificar que el objeto existe en el almacenamiento. El servidor no debe transmitir ni almacenar en buffer el archivo.
What is a signed upload, and why is it safer?
Una subida firmada es un permiso de corta duración que tu backend crea para permitir que un cliente suba directamente a un almacenamiento de objetos bajo reglas estrictas. Es más seguro que exponer credenciales de larga duración porque expira rápido y puede limitarse a un solo archivo, un único destino y restricciones concretas.
What limits should I put on signed upload permissions?
Empieza siendo estricto y afloja solo si hay una razón clara. Usa una expiración corta (minutos), un tope de tamaño, tipos MIME permitidos y una clave o prefijo de destino que impida sobrescribir archivos de otros usuarios. Estos límites reducen el abuso y evitan archivos “subidos pero inútiles”.
When should I use multipart uploads instead of a single signed URL?
Usa subidas de una sola solicitud para archivos pequeños que suelen completarse en una vez. Para archivos grandes o cuando necesitas reanudar, usa subidas multipartes (en varias partes), ya que un fallo de red no obligará a reiniciar desde cero. Multipart es la opción práctica para usuarios reales en datos móviles o Wi‑Fi inestable.
How do resumable uploads actually work in practice?
Fragmenta el archivo en partes, sube las partes de forma independiente y lleva registro de las que se completaron. Si la conexión cae, vuelve a intentar solo las partes faltantes y continúa. La clave es guardar suficiente estado (como un ID de sesión de subida y números de partes completadas) para que una actualización o reinicio pueda continuar donde quedó.
How do I keep my database from filling with “uploaded” records that have no file?
No marques una subida como completa solo porque el cliente lo dice. Después de que el cliente reporte éxito, tu servidor debe comprobar en el almacenamiento que el objeto existe y coincide en tamaño y tipo esperado; entonces cambia el registro de la base de datos de “pendiente” a “listo”. Esto evita registros rotos que apuntan a archivos inexistentes.
What UI changes make uploads feel more trustworthy to users?
Muestra el progreso basado en bytes confirmados, no solo un porcentaje que puede quedarse congelado. Indica al usuario qué ocurre cuando el progreso se detiene, por ejemplo “Reconectando”, y ofrece una acción clara para reanudar o reintentar. Si es posible, conserva el estado para que una actualización no reinicie todo desde cero, porque eso destruye la confianza rápidamente.
Why shouldn’t I transcode or virus-scan during the upload request?
El procesamiento en línea aumenta la probabilidad de timeouts y hace esperar al usuario por trabajo que no necesita bloquear la subida. Acepta la subida, verifícala y luego ejecuta la comprobación antivirus, la generación de miniaturas o la transcodificación en segundo plano con un estado separado de “Procesando”. Esto mantiene la ruta de subida rápida y predecible.
My current upload code is messy (and partly AI-generated). What’s the fastest way to fix it?
Empieza migrando una pantalla y un tipo de archivo a un flujo directo a almacenamiento con verificación y una máquina de estados. Mide la tasa de completado y las razones de fallo. Si el código está parcialmente generado por IA, da prioridad a revisar límites de autenticación, eliminar secretos expuestos y evitar retrocesos que envíen bytes de archivo a través de tu API. Si quieres, FixMyMess (fixmymess.ai) puede hacer una auditoría de código gratuita y reparar el flujo de subida para que sea apto para producción.