Timeouts y reintentos de API: límites sensatos para llamadas a terceros
Los timeouts y reintentos en llamadas a terceros evitan que una API lenta congele tu app. Define timeouts sensatos, backoff exponencial, límites de reintentos y valores por defecto seguros.
Por qué las APIs de terceros lentas pueden bloquear tu app
Una llamada a una API de terceros parece pequeña hasta que cada petición depende de ella. Cuando ese proveedor se ralentiza, tu app empieza a esperar, y esperar. Los usuarios ven spinners interminables. Los jobs en background dejan de terminar. Nada “se cae”, pero todo se siente atascado.
La mayoría de apps funcionan con capacidad limitada: un número fijo de hilos web, ranuras de concurrencia serverless o workers de cola. Cuando una petición se queda esperando a un proveedor lento, secuestra esa capacidad. Un puñado de llamadas lentas puede convertirse en un embotellamiento donde el trabajo nuevo ni siquiera puede empezar.
Las solicitudes atascadas suelen aparecer con este patrón:
- Las peticiones web se cuelgan hasta que el navegador agota su tiempo, aunque tus servidores parezcan “up”.
- Los workers se mantienen ocupados pero no completan trabajos, así que la cola sigue creciendo.
- Un endpoint empieza a consumir la mayoría de tus hilos (o conexiones a base de datos) porque está esperando una llamada externa.
- Los reintentos se disparan a ciegas, repitiendo la misma llamada lenta y haciendo que el backlog crezca más rápido.
Los timeouts y los reintentos tienen un objetivo: fallar rápido, reintentar de forma segura y recuperarse con gracia. Un timeout claro evita que un proveedor lento congele todo el sistema. Reintentos conservadores te ayudan a recuperarte de breves fallos sin crear una caída autoinfligida.
Esto sorprende a mucha gente porque los valores por defecto de los clientes HTTP suelen ser demasiado permisivos. Algunos están configurados con timeouts muy altos, y otros esperan efectivamente para siempre a menos que definas tanto connect como read timeout. Muchos prototipos generados por IA salen con esos valores por defecto, así que el sistema hace exactamente lo que le dijeron: seguir esperando.
Si tratas cada llamada a un tercero como un posible cuello de botella, puedes diseñar la app para degradarse de forma ordenada: mostrar un mensaje útil, encolar la tarea para después o cambiar a una alternativa en lugar de dejar que todo se atasque.
Términos clave: timeouts, reintentos, backoff y límites
Si quieres integraciones con terceros fiables, sé claro sobre cuatro básicos: cuánto esperas, si vuelves a intentar, cómo espacias los intentos y cuándo te rindes.
Timeouts (los distintos “relojes”)
Un timeout es una regla estricta: “Si no hemos avanzado en X segundos, para y devuelve el control a la app.” Tipos comunes:
- Connect timeout: cuánto esperas para abrir una conexión (DNS, handshake, ruta de red). Esto detecta redes muertas rápidamente.
- Read timeout: cuánto esperas por datos después de abrir la conexión. Aquí es donde los proveedores lentos suelen hacer daño.
- Total/request timeout: el tiempo máximo para toda la llamada, de inicio a fin. Es tu última red de seguridad.
Sin timeouts, un proveedor lento puede atar hilos de servidor o workers de cola hasta que todo se congestione.
Reintentos (intentar otra vez) vs. timeouts (parar)
Un reintento es otro intento después de un fallo. Los reintentos no sustituyen a los timeouts. Reintentos sin timeouts pueden ser peores que no tener reintentos, porque puedes acumular múltiples solicitudes atascadas en lugar de una sola.
Los reintentos ayudan con problemas temporales: timeouts breves, errores 502/503 y fallos de red. Son arriesgados para fallos “reales” como credenciales inválidas o peticiones mal formadas, donde repetir la misma llamada no servirá.
Backoff y jitter (esperar con cabeza)
Backoff significa esperar más entre cada reintento (por ejemplo: 1s, luego 2s, luego 4s). Jitter significa añadir una pequeña demora aleatoria para que muchos clientes no reintenten exactamente al mismo momento y vuelvan a sobrecargar al proveedor.
Límites de reintentos (cuándo rendirse)
Un límite de reintentos pone un tope a los intentos. “Rendirse” debe ser un resultado limpio: mostrar un mensaje tipo “Ese servicio está lento ahora, por favor inténtalo de nuevo,” mantener el estado del usuario seguro (carrito, borrador, datos del formulario) y registrar el fallo para seguimiento en lugar de quedarse dando vueltas para siempre.
Elegir valores de timeout sensatos
Los timeouts no son un número único que copias en todas partes. Elige por proveedor y por tipo de llamada, según lo que sea aceptable para los usuarios y lo que tu sistema pueda tolerar cuando un proveedor sea lento.
Un punto práctico de partida es separar “¿puedo conectar?” de “¿puedo recibir respuesta?”. Muchos clientes HTTP permiten configurar ambos.
Rangos típicos iniciales:
- Connect timeout: 0.2 a 1s para la mayoría de APIs públicas, hasta 2s si esperas cierta lentitud en la red.
- Read/response timeout: 2 a 10s para solicitudes típicas; 15 a 30s sólo para endpoints que sabes que tardan (reportes, exportaciones).
- Llamadas de escritura (crear cargo, crear pedido): mantén timeouts modestos (a menudo 5 a 10s) y confía en reglas de reintento seguras en lugar de esperar indefinidamente.
- Polling/chequeos de estado: timeouts cortos (2 a 5s) y menos reintentos.
Las peticiones de cara al usuario deben ser más estrictas que los jobs en background. Si una página de checkout está esperando, limita la llamada a terceros a 3–5 segundos y muestra un fallback claro. Si una sincronización nocturna corre en background, puede esperar más, pero aún necesita límites para que no se acumulen workers atascados.
También fija una deadline global para toda la operación, incluyendo reintentos. Por ejemplo: “Intentar hasta 20 segundos en total, luego fallar.” Sin esto, los reintentos pueden extender silenciosamente una llamada de 5 segundos a un problema de 2 minutos.
Escribe tus suposiciones para que la próxima persona no tenga que adivinar:
- Latencia típica del proveedor que observas (p50 y p95)
- Tolerancia UX (cuánto espera un usuario antes de abandonar)
- Tiempo máximo total que dedicarás incluyendo reintentos
- Qué endpoints pueden ser más lentos y por qué
Cuándo reintentar (y cuándo no)
Los reintentos son para problemas que probablemente se arreglan en un momento. Si la petición está mal, reintentar solo desperdicia tiempo y puede empeorar una caída.
Suelen tener sentido para fallos transitorios: una conexión caída, un DNS con fallos o un timeout. También para limitación por tasa (HTTP 429) y algunos errores de servidor (5xx), porque el proveedor puede estar sobrecargado.
Una regla práctica:
- Reintenta en errores de red, timeouts, 429 y ciertos 5xx (como 502/503/504).
- No reintentes la mayoría de 4xx (400, 401/403, 404) hasta que cambie algo.
- Respeta
Retry-Aftercuando la API lo indique. - Para si recibes un mensaje de error claramente permanente.
Ten cuidado con las solicitudes de “resultado desconocido”. Si haces timeout después de enviar un cargo de tarjeta, reintentar puede crear duplicados a menos que uses claves de idempotencia o un token de pedido.
Un enfoque práctico es separar dos patrones:
- Un reintento rápido para fallos pequeños (un intento rápido tras ~100–200 ms).
- Una secuencia corta de backoff para throttling o fallos parciales (unos pocos intentos con retrasos crecientes).
Así la app sigue siendo responsiva y aún se recupera cuando el proveedor necesita un momento.
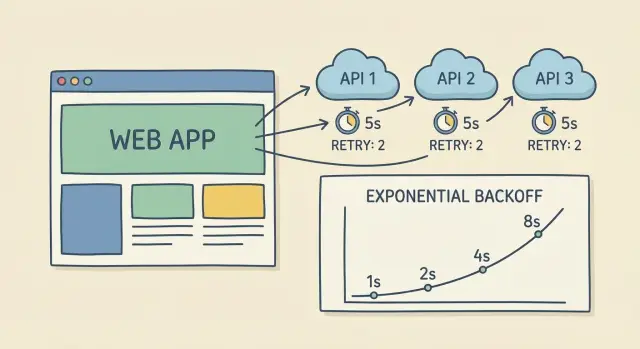
Backoff exponencial con jitter, explicado de forma simple
Cuando una llamada falla o hace timeout, reintentar de inmediato a menudo empeora las cosas. El backoff exponencial significa esperar un poco y luego cada vez más tiempo entre intentos. Reduce la presión sobre el proveedor y le da tiempo para recuperarse.
Una progresión simple (con un tope para que no se alargue):
- Intento 1: esperar 0.25s
- Intento 2: esperar 0.5s
- Intento 3: esperar 1s
- Intento 4: esperar 2s (tope aquí)
El jitter añade un pequeño desfase aleatorio. Sin él, miles de clientes pueden reintentar a los mismos instantes (exactamente un segundo después), creando otro pico y otra ola de fallos. Con jitter, un cliente puede esperar 0.8s y otro 1.3s, de modo que los reintentos se reparten.
Dos protecciones importan más:
- Limita el retraso máximo (a menudo 2 a 5 segundos).
- Mantén los intentos pequeños y predecibles, normalmente 2 a 4 reintentos.
Eso hace que el peor caso sea fácil de razonar y evita colas ocultas de trabajo atascado.
Hacer los reintentos seguros: idempotencia y prevención de duplicados
Los reintentos pueden sacarte del apuro en fallos de red, pero también pueden crear desastre. Si reintentas una acción no idempotente (como “cobrar tarjeta” o “crear pedido”), el mismo clic puede ejecutarse dos veces. Así aparecen cargos dobles, cuentas duplicadas o dos envíos.
Una regla simple: reintenta solo llamadas que sean seguras de repetir. Las lecturas (GET) suelen ser seguras. Las escrituras (POST que crean o cobran) necesitan protección antes de habilitar reintentos.
Usa claves de idempotencia cuando el proveedor las soporte
Muchas APIs de pago, mensajería y pedidos permiten enviar una idempotency key. Genera una clave única para la acción del usuario (por ejemplo, un intento de checkout) y reutilízala en cada reintento. Entonces el proveedor devuelve el mismo resultado en lugar de ejecutar la acción otra vez.
Almacena esa clave con la respuesta y mantenla estable aunque el usuario refresque la página.
Añade tu propio dedupe cuando el proveedor no lo ofrece
Si no hay idempotencia, aún puedes evitar duplicados en tu lado. Manténlo simple:
- Crea un “registro de petición” con un
request_idúnico antes de llamar al proveedor. - Aplica una restricción única (por ejemplo:
user_id + cart_id + action_type). - Guarda la respuesta del proveedor (éxito o fallo) y reutilízala en reintentos.
- Añade una ventana TTL corta para no bloquear compras legítimas futuras.
- Registra un ID de petición estable para que soporte pueda rastrear el flujo extremo a extremo.
Ejemplo: en el checkout, la primera petición de cobro hace timeout pero el proveedor luego la procesa. Si reintentas sin idempotencia o dedupe, podrías cobrar dos veces. Con un request_id estable puedes reintentar con seguridad y mostrar un único resultado final.
Detener fallos descontrolados: topes, circuit breakers y fallbacks
Los reintentos ayudan cuando un proveedor tiene un tropiezo breve. Si el proveedor está caído o muy lento, los reintentos pueden convertir un problema pequeño en una avalancha de solicitudes atascadas. El objetivo no es “nunca fallar”, sino “fallar de forma controlada” para que tu app siga siendo usable.
Pon topes estrictos en cada llamada
Toda llamada saliente necesita límites que terminen el problema con rapidez. Mantén la lista de topes corta y aplícalos consistentemente:
- Intentos máximos (por ejemplo, 3 intentos en total)
- Tiempo transcurrido máximo (por ejemplo, parar tras 10 segundos en total)
- Llamadas concurrentes máximas (evita 500 peticiones acumuladas a la vez)
- Definición estricta de qué es reintentable (solo errores esperables de recuperar)
Estos topes evitan que un proveedor lento congele tu servidor web, sature colas o consuma todos tus límites de tasa.
Usa un circuit breaker cuando un proveedor falle
Un circuit breaker es una regla simple: si demasiadas llamadas fallan en una ventana corta, pausa las llamadas por un rato. Durante la pausa devuelves una respuesta controlada inmediatamente en lugar de esperar timeouts. Tras un enfriamiento, permites un pequeño número de llamadas de prueba para ver si el proveedor se recuperó.
Esto ayuda a aislar una caída de proveedor del núcleo de tu app. Los usuarios aún pueden iniciar sesión, navegar y guardar progresos aunque una integración esté degradada.
Añade fallbacks que mantengan al usuario avanzando
Los fallbacks pueden ser tan simples como datos cacheados, un mensaje “intenta de nuevo en un minuto” o un modo degradado que omita una función no crítica.
Ejemplo: si las tarifas de envío hacen timeout en el checkout, muestra una tarifa por defecto o permite completar el pedido y confirmar el envío luego.
Paso a paso: añadir timeouts y reintentos a una app existente
Empieza por hacer consistente el comportamiento. Si cada ingeniero pone timeouts diferentes (o se olvida), un proveedor lento aún puede atar la app.
1) Centraliza tus defaults HTTP
Crea un cliente HTTP compartido (o un wrapper) y fuerza que todas las llamadas salientes pasen por él. Dale valores seguros: connect timeout, response timeout y un tope duro en el tiempo total (incluyendo reintentos). Registra cada petición con el nombre del proveedor para detectar patrones.
Luego añade una pequeña capa de políticas por proveedor. Pagos, email, mapas y modelos de IA se comportan distinto, así que las mismas reglas de reintentos rara vez encajan en todo.
2) Añade overrides por proveedor que reflejen la realidad
Para cada proveedor define:
- Timeouts (cortos para endpoints rápidos, más largos solo donde sea necesario)
- Reglas de reintento (qué códigos y errores de red califican)
- Límites de reintento (intentos máximos y tiempo máximo total)
- Manejo de rate-limits (respeta 429 y
Retry-Aftercon un número limitado de reintentos)
Mantén los reintentos conservadores. Un proveedor roto debería fallar rápido y dejar a tu app seguir funcionando.
3) Mide lo que sienten tus usuarios
Sigue unas pocas métricas y revísalas: tasa de timeouts, reintentos por petición, éxito tras reintento y latencia total (incluyendo esperas). Si los reintentos “funcionan” pero añaden 8 segundos al checkout, los usuarios igual lo sienten.
4) Compruébalo con lentitud forzada
Prueba en staging simulando respuestas lentas y conexiones inestables. Haz que una llamada a proveedor “duerma” 10 segundos y confirma que tu app hace timeout a 2 segundos, reintenta con backoff y luego para en el límite. También prueba fallos parciales donde cada tercera petición falla.
Errores comunes que causan solicitudes atascadas
Las solicitudes atascadas suelen venir de un problema raíz: no hay un límite claro sobre cuánto tiempo la app seguirá intentando. Cuando un proveedor se vuelve lento, los workers se quedan esperando y el backlog crece hasta que toda la app parece congelada.
Patrones que generan acumulaciones:
- Contar reintentos tan alto que son efectivamente infinitos.
- Reintentos inmediatos sin pausa, especialmente bajo carga.
- Sin una deadline global, el usuario espera más mientras tus servidores siguen ocupados.
- Reintentar errores permanentes (API key errónea, permisos faltantes, payload inválido) en lugar de arreglar la petición.
- Ignorar limits de tasa (429), lo que suele llevar a throttling más severo.
Un modelo mental útil: los reintentos son para problemas temporales, no para los permanentes. Cuando un proveedor está caído o lento, quieres menos intentos y más inteligentes, no más.
Lo que suele ser “seguro”: 2 a 3 intentos extra, backoff exponencial con jitter y un tope duro para toda la operación (por ejemplo, “parar tras 10 segundos en total, pase lo que pase”). Para respuestas 429, trata el tiempo de espera que indica el proveedor como parte del contrato.
Un ejemplo realista: un proveedor se enlentece durante el checkout
Imagina un flujo de checkout con tres llamadas a terceros: una API de pagos para cobrar la tarjeta, una API de envíos para obtener tarifas en vivo y un proveedor de email para enviar el recibo.
Una tarde, el proveedor de envíos se pone lento. Tu app pide tarifas, pero la petición cuelga 25–30 segundos. El cliente mira un spinner. Si tu servidor mantiene esa petición abierta, atas a los hilos y encolas más checkouts detrás. Un proveedor lento puede hacer que todo el sitio parezca roto.
Un flujo más seguro:
- Pagos: timeout corto; no reintentar automáticamente después de un intento de cobro a menos que puedas demostrar que es seguro.
- Tarifas de envío: timeout rápido (por ejemplo 2–3s), reintenta pocas veces con backoff y luego para.
- Fallback: si las tarifas siguen lentas, muestra una tarifa estándar o permite continuar y confirmar el envío después.
- Mensaje al usuario: “No pudimos cargar tarifas en vivo. Aún puedes hacer el pedido y te confirmaremos el envío por email.”
Dónde ocurren los reintentos importa. En la página de checkout mantén timeouts estrictos para dar una respuesta rápida al cliente. Después de crear el pedido puedes hacer reintentos más largos en background (siempre con límites estrictos) para obtener la tarifa final y actualizar el pedido sin tener al usuario retenido.
Lista rápida antes de desplegar
Antes de lanzar, revisa cada llamada a terceros (pagos, email, mapas, auth, envíos, proveedores de IA). El objetivo es simple: un proveedor lento no debe congelar tu app y una caída breve no debe crear una pila de solicitudes atascadas.
Asegúrate de que cada llamada tenga:
- Un connect timeout corto
- Un read/response timeout razonable
- Una deadline total para la operación (incluyendo reintentos)
Para reintentos:
- Reintenta solo fallos transitorios (timeouts, errores de red temporales, 429/5xx claros)
- Usa backoff exponencial más jitter
- Aplica máximos de intentos y tiempo transcurrido en todas partes (cliente HTTP, colas de jobs, workers)
Finalmente, haz los reintentos seguros. Si una operación puede crear duplicados (cargos, pedidos, creación de cuentas), añade claves de idempotencia o dedupe antes de habilitar reintentos.
El monitoreo debe decirte qué pasa por proveedor: tasa de timeouts, tasa de reintentos y latencia media. Así detectas problemas antes de que se conviertan en un bloqueo visible para el usuario.
Próximos pasos: estabiliza tus integraciones sin sobrecrear
Empieza encontrando las llamadas que pueden quedarse esperando para siempre. Busca peticiones sin timeout explícito, jobs en background que reintentan “hasta que tienen éxito” y workers que nunca se rinden. Esos son los que silenciosamente se acumulan y convierten una pequeña lentitud del proveedor en una caída.
Elige uno o dos APIs críticas y completa el patrón de extremo a extremo antes de tocar todo lo demás. Crítico suele significar flujo de dinero, inicio de sesión, mensajería o cualquier cosa que bloquee una acción de usuario. Implementa un timeout claro, una política de reintentos con backoff y un límite duro de reintentos. Añade logging básico para poder responder: ¿cuántas veces reintentamos?, ¿cuánto esperamos?, ¿al final tuvimos éxito?
Cuando algo falla, la velocidad importa más que la herramienta perfecta. Escribe un playbook de incidentes pequeño: cómo deshabilitar temporalmente un proveedor (feature flag o toggle de configuración), qué mostrar a los usuarios, qué revisar primero (estado del proveedor, tasas de error, profundidad de cola) y cuándo reactivar.
Si heredaste una base de código generada por IA con defaults inseguros, FixMyMess (fixmymess.ai) puede ejecutar una auditoría de código gratuita para localizar timeouts faltantes, reintentos descontrolados e integraciones frágiles, y luego ayudar a convertir el prototipo en software listo para producción con correcciones verificadas por humanos.
Preguntas Frecuentes
Why can a single slow third-party API make my whole app feel frozen?
Tu aplicación tiene una capacidad limitada (hilos web, slots serverless o workers). Si una solicitud espera a una API externa lenta sin un timeout estricto, mantiene esa capacidad ocupada y el trabajo nuevo no puede empezar, por eso todo parece bloqueado aunque nada "se caiga".
What timeouts should I set for most third-party API calls?
Configura un timeout corto de conexión y un timeout separado de lectura/respuesta, más una deadline total para la petición. Un punto de partida común es 0.2–1s para conectar y 2–10s para recibir la respuesta, luego ajusta según lo que toleren tus usuarios.
What’s the difference between a timeout and a retry?
Un timeout deja de esperar y devuelve el control a la app. Un reintento es un nuevo intento tras un fallo. Normalmente necesitas ambos: timeouts para evitar trabajo bloqueado y pocos reintentos para recuperarte de fallos breves.
Which errors should I retry, and which should I avoid retrying?
Reintenta solo errores que probablemente sean temporales, como timeouts, problemas de red, 429 por límite de tasa y ciertos 5xx. Evita reintentar la mayoría de los 4xx (peticiones inválidas o credenciales erróneas), porque repetir no arregla el problema.
How do I do backoff and jitter without making things worse?
Usa backoff exponencial para aumentar el tiempo entre intentos y añade jitter para que muchos clientes no reintenten exactamente a la vez. Manténlo pequeño y predecible, por ejemplo 2–4 reintentos con un retraso máximo, así no creas esperas largas ni acumulaciones grandes.
Why can retries cause double charges or duplicate orders?
Los reintentos pueden repetir una acción "de escritura" si el primer intento en realidad tuvo éxito pero no recibiste la respuesta. Sin idempotencia o deduplicación puedes terminar con cargos dobles, pedidos duplicados o mensajes repetidos.
Should timeouts be different for web requests vs. background jobs?
Para interacciones con usuario (por ejemplo checkout) mantén timeouts estrictos y muestra una alternativa clara si el proveedor está lento. Para jobs en background puedes esperar más, pero siempre con límites para que un proveedor no bloquee los workers.
When should I add a circuit breaker?
Cuando muchas llamadas fallan en poco tiempo, el circuit breaker pausa las llamadas por un rato para que devuelvas una respuesta controlada en lugar de esperar timeouts. Es útil para aislar una degradación del proveedor y mantener usable el resto de la app.
Why do AI-generated prototypes often ship with unsafe HTTP defaults?
La mayoría de clientes HTTP vienen con valores por defecto demasiado permisivos, y algunos esperan indefinidamente a menos que pongas tanto connect como read timeouts. Muchos prototipos generados por IA mantienen esos valores por defecto, así que la app simplemente sigue esperando.
What’s the fastest way to add sane timeouts and retries to an existing app?
Centraliza las llamadas salientes detrás de un cliente compartido para aplicar defaults seguros a todas ellas. Si heredaste un código generado por IA y no sabes dónde faltan timeouts y reintentos, FixMyMess (fixmymess.ai) puede ejecutar una auditoría gratuita y arreglar el comportamiento de las integraciones rápidamente con correcciones verificadas por humanos.