¿Los trabajos en segundo plano no se ejecutan? Arregla colas, cron y workers rápido
Que los trabajos en segundo plano no se ejecuten puede romper correos, facturación y sincronizaciones. Aprende a identificar si el problema es cron, las colas, los workers, los reintentos o la idempotencia, y cómo solucionarlo.
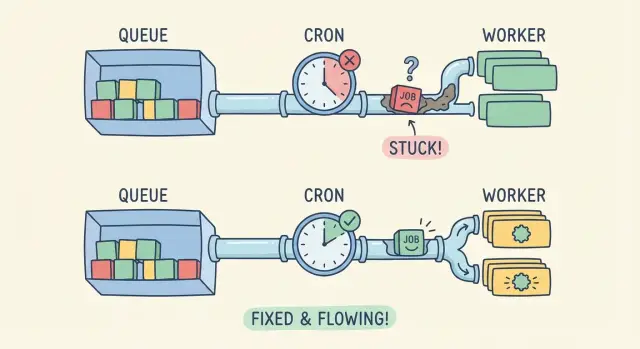
Cómo se ve cuando los trabajos en segundo plano dejan de funcionar
Cuando los trabajos en segundo plano no se ejecutan, la aplicación puede parecer bien al principio. Las páginas cargan, los usuarios navegan y los formularios se envían. Pero el trabajo “posterior” nunca sucede.
La gente nota efectos secundarios faltantes: el email de bienvenida no llega, una importación CSV se queda en “procesando” para siempre, se recibe un webhook de pago pero el pedido no se actualiza, o una sincronización nocturna deja de cambiar cifras. Los tickets de soporte suenan vagos (“se quedó atascado”) porque nada se cae de forma evidente.
Esto es especialmente común en prototipos generados por IA. A menudo funcionan localmente porque una sola máquina hace todo: servir la app web, activar los schedules y ejecutar los workers. En producción esas piezas están separadas en servicios, contenedores o máquinas. Que falte una pieza rompe la cadena.
La mayoría de las fallas caen en cuatro categorías:
- Scheduling: cron/timers no se disparan, hay deriva de zonas horarias o el schedule corre en el entorno equivocado.
- Despliegue del worker: el worker no está ejecutándose, no puede alcanzar la cola o apunta a la cola equivocada.
- Reintentos: los trabajos fallan y se reintentan sin fin, o fallan una vez y desaparecen sin alertas.
- Idempotencia: un trabajo se ejecuta dos veces y corrompe el estado, por lo que se deshabilita o falla constantemente.
Antes de tocar código, reúne algunos datos. Ahorras horas de adivinanzas y te queda más claro dónde se rompe la canalización:
- La marca temporal cuando ocurrió la acción del usuario (o cuando debería haberse disparado el schedule)
- El nombre/tipo del trabajo y cualquier ID de trabajo que registre tu sistema
- Logs del worker en ese momento (no solo los logs web)
- Métricas de la cola: pendientes, en progreso, fallidos
- La última vez que ese mismo trabajo corrió con éxito
Si heredaste un prototipo de herramientas como Replit, Cursor o Bolt, este “paquete de evidencias” es también lo que equipos como FixMyMess usan para detectar si falta un scheduler, si hay un worker muerto o si un trabajo está fallando en silencio.
Cron, colas y workers: el modelo mental simple
Piensa en el trabajo en segundo plano como un sistema de entrega. Algo decide cuándo debe suceder el trabajo, algo guarda el trabajo y algo lo ejecuta.
Cron (o un scheduler) es el reloj. Dispara una tarea según un calendario como “cada 5 minutos” o “todos los lunes a las 9am”. Una cola es el buzón. Mantiene los trabajos hasta que un worker esté listo. Un worker es el repartidor. Toma trabajos de la cola y ejecuta el código.
Los trabajos puntuales y los recurrentes se inician de forma distinta. Un trabajo puntual suele ser creado por tu app (por ejemplo, “redimensionar esta imagen tras la subida”). Un trabajo recurrente suele ser creado por cron (por ejemplo, “enviar informes semanales”). Si usas una cola, ambos acaban en el mismo lugar: un registro de trabajo esperando ser procesado.
En producción, el estado debe vivir en un sitio compartido y duradero: una tabla de base de datos para ejecuciones programadas, Redis para mensajes de cola o un servicio de colas gestionado. Si un prototipo depende de estado en memoria, puede funcionar localmente y fallar en cuanto haya más de un servidor o tras un reinicio.
El desarrollo local oculta problemas porque todo corre en un mismo proceso. En producción están separados. Si no está instalado cron, si no se desplegó el worker o si el worker no puede alcanzar Redis o la base de datos, obtendrás el síntoma clásico: los trabajos en segundo plano no se ejecutan aunque la app parezca “saludable” en la superficie.
Triage rápido: ¿dónde se rompe la canalización?
No adivines. Averigua qué parte de la canalización está fallando: ¿no se crean los trabajos, no se recogen o se ejecutan y fallan?
1) ¿Se crean trabajos en absoluto?
Empieza con la división más simple: “no existe ningún trabajo” vs “el trabajo existe pero no pasa nada”. Busca un registro de trabajo en tu almacén/tabla de colas, o cualquier línea de log que confirme que un trabajo fue encolado.
Si no ves nada, suele ser scheduling. Cron/timers pueden no estar corriendo en producción, pueden estar corriendo en el entorno equivocado o pueden no tener los permisos adecuados. Un error común en prototipos es depender de un scheduler local (tu portátil) sin desplegar un proceso scheduler real.
2) ¿Se crean trabajos pero nunca se procesan?
Si los trabajos existen pero se quedan como “queued”, probablemente tengas un worker que no procesa trabajos. Confirma que un worker esté realmente ejecutándose en el entorno de producción (no solo durante el deploy) y que esté escuchando el mismo nombre de cola al que tu app publica.
También revisa conectividad y credenciales. Los workers necesitan acceso al backend de la cola (Redis/SQS/base de datos) y las mismas vars de entorno que la app. Una variable desajustada puede hacer que el worker parezca “saludable” mientras nunca ve los trabajos.
3) ¿Los trabajos se ejecutan pero fallan y se reintentan para siempre?
Si ves que aumentan los intentos, probablemente el scheduling esté bien. Ahora es ejecución. Abre el último error y busca la causa que se repite (errores de autenticación, secretos faltantes, timeouts). Los reintentos deberían tener backoff y un número máximo de intentos.
Si un trabajo toca dinero, correo o datos de usuario, asume que puede ejecutarse dos veces. La falta de idempotencia es cómo un “está fallando” se convierte en “está fallando en voz alta”, con cargos duplicados o correos repetidos.
Arreglar problemas de scheduling (cron y timers)
Primero verifica lo básico: ¿se dispara algo y lo hace cuando crees que debe hacerlo?
Confirma que el schedule es el que crees
Las expresiones cron pueden parecer correctas y aun así estar mal. Las zonas horarias son la trampa más común. Tu portátil puede estar en hora local mientras producción corre en UTC. Eso convierte “todos los días a las 9am” en “todos los días a la 1am” o “no durante tu ventana de pruebas”.
También revisa cómo interpreta tu plataforma el schedule. Algunos sistemas usan cron de 5 campos, otros de 6 (con segundos). Un campo extra desplaza todo.
Comprobaciones rápidas que detectan la mayoría de errores:
- Imprime los próximos 5 tiempos de ejecución desde tu scheduler (en logs) y confirma que coinciden con lo esperado.
- Confirma la configuración de zona horaria tanto en la configuración de la app como en el entorno de hosting.
- Valida la cadena cron contra la librería de scheduler que realmente estás usando.
- Asegúrate de que el trabajo esté habilitado en producción (feature flags y vars de entorno suelen diferir).
- Confirma que solo hay una instancia del scheduler activa (o podrías obtener duplicados).
Haz que el scheduler sea seguro en producción
Un scheduler que corre en tu portátil no se ejecuta automáticamente después del despliegue. En prototipos, es común poner el scheduler dentro del proceso del servidor web. Entonces se detiene cuando el dyno web se reinicia, escala a cero o duerme.
Las ejecuciones perdidas son otra falla silenciosa. Si la app se reinicia a las 9:01, el trabajo de las 9:00 no se dispara a menos que lo diseñes para ello. Para tareas importantes, considera un enfoque de recuperación: al iniciar, comprueba qué debería haber corrido y encola esos trabajos.
Finalmente, maneja los solapamientos. Si un trabajo puede tardar más que su intervalo, necesitas un lock o una regla de “no solapar”. Si no, verás envíos dobles, facturación duplicada o actualizaciones en competencia.
Arreglar despliegue del worker y conectividad
Si el scheduling parece correcto pero los trabajos siguen sin procesarse, revisa el worker. Una cola solo avanza cuando un proceso worker está en línea, conectado y capaz de mantenerse en ejecución.
Confirma que hay un proceso worker en el mismo entorno donde se despliega la app (no solo en tu portátil). Quieres evidencia de que arranca, permanece activo y apunta a la misma cola a la que tu app envía trabajos. Revisa la lista de procesos o el panel de servicio, luego busca en logs una línea de inicio como "listening" o "connected".
Grietas de despliegue que aparecen a menudo en prototipos generados por IA:
- El worker nunca se desplegó (solo se desplegó la app web).
- El comando del worker es incorrecto (ejecuta un script de dev o sale inmediatamente).
- Faltan variables de entorno en el worker (URL de la cola, credenciales, NODE_ENV).
- El worker apunta a un nombre/región de cola distinto al de la app.
- El worker se cae y reinicia en bucle (a menudo por límites de memoria o dependencias faltantes).
Los problemas de conectividad se parecen: los trabajos se acumulan y nadie los consume. Causas comunes: host incorrecto, puertos bloqueados, credenciales expiradas o un servicio de colas accesible solo desde una red privada en la que el worker no está.
La concurrencia importa también. Muy pocos workers implican procesamiento lento; demasiados pueden causar timeouts, límites de tasa o crashes por falta de memoria. Un punto de partida simple es 1–2 workers con baja concurrencia, y aumentar solo cuando veas memoria estable y tiempos de trabajo predecibles.
Ejemplo: una startup despliega un trabajo “enviar correos de facturas”. La app web encola bien, pero el worker arranca sin las credenciales de la cola en producción, así que inicia y luego sale. Arreglar el entorno del worker (y añadir una línea clara de log “connected to queue”) hace el problema evidente la próxima vez.
Reintentos, backoff y manejo de fallos sin espirales
A veces la queja “los trabajos en segundo plano no se ejecutan” es en realidad: el trabajo se ejecuta, falla instantáneamente y se reintenta tan rápido que nunca avanza. Buenas reglas de reintento mantienen el sistema tranquilo y los logs legibles.
Clasifica las fallas en dos grupos:
- Errores transitorios suelen desaparecer: timeouts, límites de tasa, bloqueos breves de DB, pequeñas interrupciones de red. Estos deben reintentarse.
- Errores permanentes no mejoran con el tiempo: datos faltantes, una API key inválida, “usuario no encontrado”, errores de validación o un bug que siempre lanza en la misma línea. Estos deben fallar rápido y terminar en un estado “muerto” para revisión.
El backoff evita que un problema pequeño se convierta en una tormenta. Un valor sensato por defecto es un número reducido de intentos (por ejemplo, 3–10), con retrasos que aumentan cada vez. Añade un poco de jitter aleatorio para que mil trabajos no reintenten exactamente al mismo segundo.
Captura lo mismo cada vez que un trabajo falla para poder reproducirlo después:
- Nombre del trabajo, ID de trabajo único y número de intento
- El payload exacto (o un resumen seguro) y los IDs de registros relevantes
- El mensaje de error y stack trace, además del código de respuesta upstream si fue una llamada API
- Información temporal: cuánto duró el trabajo y cuánto hasta el próximo reintento
Las alertas pueden ser simples. Si la profundidad de la cola crece por 10 minutos, o la edad del trabajo más antiguo cruza un umbral, notifica a alguien o al menos manda un mensaje a un canal compartido. Esto detecta fallos “silenciosos” donde el worker está vivo pero cada trabajo está atascado.
Ejemplo: un trabajo semanal de correos choca con un límite de tasa del proveedor el lunes por la mañana. Sin backoff, se reintenta inmediatamente, consume todos los intentos y pierde correos. Con backoff y un log claro de “rate limited”, espera, se recupera y puedes confirmar la solución.
Idempotencia: hacer que los trabajos sean seguros para ejecutarse dos veces
Una vez que los trabajos vuelven a correr (o los reintentos empiezan a funcionar), aparece un problema nuevo: el mismo trabajo se ejecuta dos veces. Si el trabajo no es idempotente, “dos veces” puede significar cobrar dos veces a un cliente, enviar correos duplicados o crear registros repetidos.
Idempotencia significa que puedes ejecutar el mismo trabajo más de una vez y aún así obtener un resultado correcto y único. Imagina una tarea “cobrar tarjeta y enviar recibo”. Un fallo de red puede ocurrir después de que el pago se haya completado pero antes de que tu app guarde el resultado. La cola reintenta y el cliente recibe otro cargo.
Dónde ayudan más las claves de idempotencia
Para cualquier cosa que hable con el mundo exterior (pagos, proveedores de email, SMS, webhooks), añade una clave de idempotencia que sea la misma para la acción lógica, no para el intento. Una buena clave se ata a un ID de negocio estable, como invoice_1234 u order_987.
También protege tu base de datos contra duplicados. La salvaguarda más simple es una restricción única, por ejemplo “solo un recibo por factura”. Entonces tu trabajo puede “intentar insertar” y tratar “ya existe” como éxito.
Patrones prácticos que funcionan bien al pasar de prototipo a producción:
- Registrar el estado del trabajo primero (por ejemplo:
payment_pending), luego hacer la llamada externa y luego marcarpayment_completed. - Almacenar una “clave procesada” (ID de trabajo o ID de negocio) y comprobarla antes de hacer efectos secundarios.
- Usar constraints únicos para cosas de una sola vez (recibos, emails, suscripciones).
- Devolver éxito si el resultado ya existe.
Si heredaste un prototipo generado por IA, esto suele faltar: los trabajos hacen el efecto secundario primero y luego intentan guardar. Corregir ese orden puede eliminar la mayoría de cargos y correos duplicados.
Paso a paso: un flujo de depuración repetible
Deja de adivinar y prueba un punto de la canalización a la vez. El objetivo es convertir un síntoma vago (no se envían correos, no se generan informes) en un punto de fallo claro que puedas arreglar.
Usa un trabajo pequeño de prueba con un payload conocido y manten todo lo demás igual que en producción:
- Prueba que el scheduler dispare: ejecuta el scheduler a demanda (o cambia temporalmente el cron a cada minuto) y confirma que intenta encolar el trabajo.
- Prueba que el trabajo se crea: revisa la cola, la tabla de trabajos o el broker para una nueva entrada con tu payload y timestamp conocidos.
- Prueba que un worker pueda verlo: arranca un worker en primer plano y obsérvalo recoger el trabajo.
- Lee el error real: encuentra la primera falla (var de entorno faltante, URL de DB equivocada, correo saliente bloqueado, permisos).
- Vuelve a ejecutar el mismo trabajo: confirma que se completa y luego confirma que no aplica cambios dos veces si se ejecuta de nuevo.
Cuando hagas esto, sabrás qué capa está rota: scheduling, encolado, despliegue/conectividad del worker o lógica del trabajo.
Después de que funcione una vez, añade guardarraíles
Que un trabajo funcione solo cuando estás mirando no significa que esté arreglado. Añade algunas protecciones para que las fallas no se acumulen en silencio:
- Timeouts y límites (para que los trabajos no se queden colgados)
- Reglas claras de reintento con backoff (para que las fallas no entren en bucle)
- Cola de muerto o failure queue (para que los trabajos malos no bloqueen los buenos)
- Comprobaciones de idempotencia (para que un reintento no cobre o envíe dos veces)
- Logs que incluyan ID del trabajo y entradas clave
Trampas comunes que impiden que los trabajos se completen
A menudo la causa no es el sistema de colas en sí. Es una pequeña desincronización entre dónde corre el scheduler, dónde corre el worker y qué necesita el trabajo para tener éxito.
Un fallo común es dividir la canalización por accidente. Por ejemplo, cron corre en un servidor web, pero el worker está desplegado en otra máquina o contenedor que no está activo en producción. El scheduler encola felizmente trabajo, pero no hay nadie que lo recoja.
Otras trampas recurrentes:
- Usar una cola en memoria (o un adaptador solo para dev) de modo que los trabajos desaparezcan al reiniciar o al escalar.
- Capturar errores y devolver “éxito” de todos modos, de modo que el trabajo parezca hecho pero no hizo nada.
- No tener visibilidad de fallos, de modo que los trabajos rotos se acumulen en silencio durante días.
- Secretos y endpoints hardcodeados que difieren entre local, staging y prod.
- Los trabajos dependen de archivos locales o una carpeta temporal que no existe en el worker.
Un ejemplo pequeño: un trabajo envía facturas y llama a una API externa. Localmente funciona porque la API key está en tu .env. En producción, el contenedor del worker no tiene esa variable, el código captura la excepción y el trabajo termina “completado” sin enviar la factura. Solo lo notas cuando los clientes se quejan.
Si sospechas una de estas, responde dos preguntas: ¿dónde corre el trabajo (qué servicio) y dónde ves sus logs? Si no puedes encontrar ambas cosas, las fallas pueden ocultarse mucho tiempo.
Lista de comprobación rápida antes de volver a lanzar
Antes de enviar otra build, haz un repaso rápido de toda la canalización. La mayoría de los reportes de “trabajos en segundo plano no se ejecutan” no son un bug único. Son pequeños desajustes entre scheduling, encolado y configuración del worker.
Empieza por el scheduler. En muchos prototipos, el proceso de cron nunca corre en producción, o corre en un contenedor que se escala a cero. Confirma que está ejecutándose ahora mismo (no solo “configurado”) y que tiene las mismas variables de entorno que la app.
Luego confirma que los trabajos realmente se crean. Verifica que la marca temporal (run at / scheduled for) coincida con tu zona horaria de producción y que el payload tenga IDs reales (no cadenas vacías, correos de ejemplo ni user IDs nulos). Si los trabajos se crean pero están programados para muy en el futuro, parecerán “atascados” aunque nada esté roto.
Después verifica el worker. Asegúrate de que al menos un proceso worker corra continuamente y escuche exactamente el nombre de la cola que usa la app. Un solo typo o una cola por defecto mal elegida puede crear acumulaciones silenciosas.
Finalmente, haz visibles los fallos y seguros los reintentos:
- Loggea errores con contexto suficiente (nombre del trabajo, ID, campos clave)
- Limita los reintentos y usa backoff, para que las fallas no se repitan sin fin
- Haz los trabajos idempotentes, para que un reintento no envíe correos duplicados, cobre dos veces o recree registros
Ejemplo: el trabajo semanal de correos que funciona localmente pero no en producción
Una historia común “funcionaba en mi portátil”: un prototipo envía un informe semanal cada lunes a las 9:00. Tras el despliegue, nada llega. El panel parece bien, los usuarios entran y no hay errores obvios.
Primera comprobación: ¿el schedule es real en producción? Localmente, tu servidor de dev puede ejecutar un scheduler automáticamente (o lo arrancaste una vez y lo olvidaste). En producción la entrada de cron existe en la configuración, pero no hay un proceso scheduler realmente ejecutándose. El código es correcto, pero nada lo dispara.
Tras desplegar un scheduler (o habilitar el cron de la plataforma), los trabajos empiezan a aparecer. Eso revela el segundo problema: el worker reintenta el mismo trabajo porque falta una var de entorno para la API del proveedor de correo. Cada ejecución falla, vuelve a encolar y crea un backlog. Los trabajos nuevos se retrasan y la cola parece “atascada”, aunque el worker esté ocupado fallando.
Qué arregla esto para siempre:
- Añadir un log de salud simple cuando el scheduler encola trabajos (para probar que los triggers ocurren).
- Fallar rápido por variables de entorno faltantes en el inicio (para que el worker se caiga de forma visible en vez de reintentarlo todo).
- Limitar reintentos con backoff (por ejemplo, 5 intentos en 30 minutos) y mover el trabajo a dead-letter para revisión.
- Hacer el trabajo de correo idempotente guardando una clave única como
report:teamId:weekStartDateantes de enviar, y omitiendo el envío si ya existe.
Con esos cambios puedes reiniciar workers, redeployar o recuperarte de crashes sin enviar duplicados ni crear bucles de reintento infinitos.
Próximos pasos: endurecer la canalización y mantenerla estable
Una vez que los trabajos vuelven a ejecutarse, el objetivo es evitar que la misma ruptura vuelva la próxima semana. Trata los trabajos en segundo plano como un riesgo de producción, no como un bug puntual.
Convierte lo aprendido en un runbook corto para que cualquiera pueda seguirlo:
- Dónde se definen los schedules (config de cron, scheduler de la plataforma, timers de la app)
- Cómo se arrancan los workers (nombre del proceso, comando, vars de entorno requeridas)
- Qué significa “saludable” (profundidad de cola, última ejecución exitosa)
- Los modos de fallo principales que viste (timeouts, auth, payloads inválidos)
- La forma segura de reproducir trabajos (y cómo evitar envíos dobles)
Añade monitorización mínima que responda a dos preguntas: ¿se están acumulando trabajos? ¿fallan? Incluso alertas básicas sobre crecimiento de la cola y un conteo diario de trabajos fallidos detectan la mayoría de los problemas temprano.
Si tu prototipo mezcla lógica de request web y lógica de trabajo, planifica un pequeño refactor. Mueve el núcleo del trabajo a una función que pueda ejecutarse desde un worker, y que la petición web solo encole y valide entrada. Esto hace los reintentos más seguros y elimina dependencias ocultas del estado de la petición.
Si heredaste una app generada por IA y necesitas una segunda opinión rápida, FixMyMess (fixmymess.ai) se centra en diagnosticar y reparar prototipos rotos para que colas, workers, reintentos y comportamiento de despliegue coincidan con lo que ves localmente — con verificación humana antes de desplegar.
Preguntas Frecuentes
How do I know it’s a background job problem and not a normal app bug?
Si las páginas cargan pero las acciones “posteriores” nunca ocurren (no llegan correos, las importaciones quedan en “procesando”, se recibe un webhook pero no se actualiza nada), da por hecho que los trabajos en segundo plano están fallando. Confirma revisando si el trabajo fue encolado alguna vez y si un worker intentó ejecutarlo alrededor del momento en que ocurrió la acción del usuario.
Why do background jobs work locally but not in production?
Porque en desarrollo local suele ejecutarse todo en el mismo sitio: el servidor web, el scheduler y el worker. En producción esos componentes están separados en procesos o servicios distintos, así que una pieza que falte (no hay scheduler ejecutándose, no se desplegó el worker, conexión a la cola incorrecta) rompe la cadena aunque la app web siga pareciendo correcta.
What’s the fastest way to triage where the pipeline is breaking?
Empieza por decidir qué etapa está rota: creación del trabajo, recogida por el worker o ejecución. Primero, busca un registro de enqueue o una entrada en la tabla/cola; si no existe suele ser problema de scheduling. Si existen trabajos pero quedan encolados, suele ser problema del worker o de conectividad. Si los intentos aumentan, el trabajo está ejecutándose y fallando, así que céntrate en el error y en las reglas de reintento.
What are the most common scheduling (cron) mistakes?
Se rompe el scheduling cuando no se crea el trabajo a la hora esperada. Causas comunes: el scheduler no corre en producción, diferencias de zona horaria (local vs UTC), el schedule definido para el entorno equivocado o un formato de cron distinto (5 campos vs 6). Una comprobación rápida es registrar las próximas ejecuciones y confirmar que coinciden con lo esperado.
What’s the difference between the queue and the worker, and what breaks most often?
La cola es donde esperan los trabajos y el worker es el proceso que los toma y los ejecuta. Si los trabajos se acumulan como “queued” suele significar que el worker no está ejecutándose, apunta a un nombre de cola distinto o no puede acceder al backend de la cola por credenciales o red.
Why does my worker look “healthy” but still never processes jobs?
Porque el app y el worker a menudo tienen conjuntos distintos de variables de entorno. La app puede encolar correctamente mientras el worker carece de URL de la cola, URL de la base de datos o una API key, así que arranca pero no puede procesar trabajos. La solución más simple es verificar que el worker tenga las mismas vars críticas que el proceso web y que registre un claro mensaje de “connected to queue” al iniciar.
If retries keep happening, does that mean scheduling is fine?
No necesariamente; puede significar que el trabajo falla instantáneamente y se reintenta. Comprueba si el contador de intentos aumenta y si el mismo error se repite. Si es así, añade un máximo de intentos y backoff para que las fallas no se repitan sin control, y asegúrate de que los errores permanentes vayan a un estado de fallo que puedas revisar en lugar de reintentarse indefinidamente.
How do I prevent duplicate emails or double charges when jobs retry?
La idempotencia permite que el mismo trabajo pueda ejecutarse más de una vez sin causar efectos duplicados. Usa claves de idempotencia estables para efectos externos (pagos, emails, SMS) y protege la base de datos con restricciones únicas para que “ya hecho” se trate como éxito. Así evitas cargos duplicados y correos repetidos cuando hay reintentos tras un éxito parcial.
What information should I collect before changing code?
Captura la marca temporal de la acción del usuario (o la hora esperada), el nombre/tipo del trabajo y cualquier ID de trabajo, los logs del worker para esa ventana, la profundidad de la cola y recuentos de fallos, y la última ejecución correcta del mismo trabajo. Este “paquete de evidencias” te dice rápido si no se crean trabajos, no se consumen o fallan en ejecución.
When should I bring in FixMyMess instead of debugging longer?
Si heredaste un prototipo generado por IA y los trabajos están atascados, fallan silenciosamente o duplican efectos, suele tratarse de un desajuste en despliegue y pipeline más que de un bug pequeño. FixMyMess puede hacer una auditoría de código gratuita para localizar si falta un scheduler, si hay un worker inactivo o si fallan secretos y reintentos, y luego reparar y endurecer la configuración con verificación humana.