Transacciones de base de datos para escrituras atómicas: evita datos a medio guardar
Aprende cómo las transacciones de base de datos para escrituras atómicas evitan registros a medio guardar, con pasos sencillos, manejo de rollback y comprobaciones rápidas para apps más seguras.
Qué son los registros “a medio guardar” y por qué ocurren
Un registro “a medio guardar” aparece cuando una acción del usuario requiere varios cambios en la base de datos, pero solo algunos de ellos se completan. El usuario cree que terminó la tarea, pero la base de datos ahora contiene una versión incompleta.
Ejemplo: un checkout debería (1) crear un pedido, (2) reservar inventario y (3) registrar un intento de pago. Si la fila del pedido se crea pero la actualización de inventario falla, tienes un pedido que no puede enviarse. Si el inventario se reserva pero falta la fila de pago, soporte ve stock desaparecer sin ingresos asociados.
Este tipo de inconsistencia genera fallos que parecen aleatorios:
- filas faltantes (existe un pedido, pero no hay items de pedido)
- totales que no cuadran (el total de la factura no coincide con las líneas)
- registros huérfanos (un pago referencia un pedido que nunca se creó)
- duplicados (un reintento crea un segundo pedido)
- estados “atascados” (el estado dice “pagado” pero nada más coincide)
Los usuarios viven esto como confusión de alto impacto: un registro que dice “Bienvenido” pero luego no puede iniciar sesión, un correo de confirmación con un pedido vacío, o un pago que parece exitoso pero no aparece la suscripción.
Los datos a medio guardar suelen aparecer cuando el código ejecuta varias inserciones y actualizaciones por separado, sin tratarlas como una única unidad. Un fallo de red, un crash del servidor, un error de validación o un timeout a mitad de camino bastan para dejar pasos iniciales comprometidos y pasos posteriores sin ejecutar.
Es especialmente común en prototipos generados por IA porque se enfocan en el camino feliz. Los casos extremos como fallos parciales, reintentos y limpieza suelen faltar, así que acciones que deberían ser atómicas terminan siendo una cadena de consultas independientes sin un plan claro de rollback.
Cuándo deberías usar una transacción (y cuándo no)
Usa una transacción cuando una acción del usuario crea o cambia datos en más de un lugar y no es aceptable quedarte “a medio”. El objetivo es simple: o todos los cambios relacionados se guardan, o ninguno.
Las transacciones encajan bien cuando los registros dependen unos de otros, como crear la cabecera de un pedido y sus líneas. Si el pedido se guarda pero las líneas no, tu app tiene un registro que parece real pero no se puede cumplir.
También son la herramienta correcta cuando los cambios deben fallar juntos porque hay dinero o límites implicados: recuentos de inventario, saldos de cuentas, créditos y consumo de cuota. Si una actualización ocurre sin la otra, puedes sobrervender, cobrar doble o permitir que usuarios excedan límites.
Una regla práctica: si tocas varias tablas como parte de un mismo resultado, asume que necesitas una transacción.
Si un flujo cruza servicios (escritura en DB más enviar un correo o cobrar una tarjeta), mantén los efectos externos fuera de la transacción. Guarda primero el estado, confirma (commit), y luego desencadena el correo o el cobro de forma que puedas reintentar de manera segura.
Señales de que probablemente necesitas transacciones (o más estrictas) incluyen scripts de limpieza recurrentes tras fallos, tickets de soporte como “lo veo en una pantalla pero no en otra”, dashboards que no coinciden porque faltan filas, y código donde los saves están dispersos en helpers.
Cuándo no usar una transacción: para trabajo largo y lento (procesamiento de archivos, jobs en lote grandes, espera de APIs de terceros). Mantener una transacción abierta demasiado tiempo puede bloquear a otros usuarios y aumentar probabilidad de timeouts.
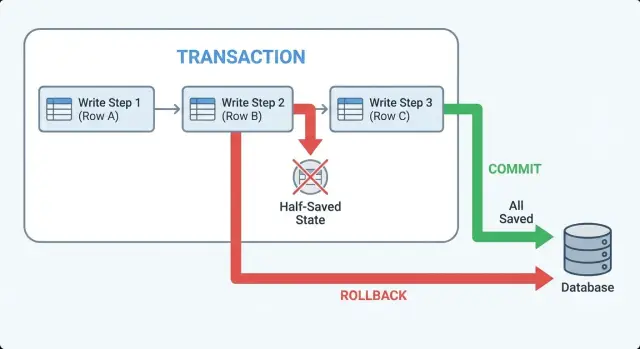
Transacciones en términos simples: commit, rollback, atómico
Una transacción es una envoltura de seguridad alrededor de un conjunto de escrituras en la base de datos. Convierte “guardar estas 3 cosas” en una acción todo-o-nada.
“Atómico” significa que o bien cada cambio del grupo se guarda, o ninguno. No hay un estado intermedio donde algunas filas existen y otras no.
Piensa en un checkout donde (1) creas un pedido, (2) reservas inventario, y (3) registras un intento de pago. Sin transacción, un crash entre pasos puede dejarte con un pedido que parece real pero sin ítems reservados, o con inventario reservado sin pedido. Con una transacción, la base de datos trata esos pasos como una unidad.
Estos son los términos que verás en código y logs:
- Begin: iniciar la transacción. Los cambios son temporales hasta el final.
- Commit: hacerlo permanente. Todos los cambios aterrizan a la vez.
- Rollback: deshacerlo. La base de datos descarta todo desde el begin.
Commit y rollback son los dos finales limpios. Si tu app puede salir antes (error, timeout, fallo de validación), quieres que el código deje claro qué final ocurre.
Una frase sobre aislamiento
El aislamiento significa que tu transacción está protegida de sorpresas causadas por otras personas escribiendo al mismo tiempo, para que no leas o escribas en base a datos que cambian debajo de ti.
Si recuerdas una sola regla: agrupa inserts y updates relacionados que deben triunfar juntos, y no permitas efectos secundarios (emails, webhooks, jobs en background) hasta después del commit.
Paso a paso: envolver una escritura en varios pasos en una sola transacción
Los datos a medio guardar ocurren cuando un paso inicial tiene éxito (como crear una fila) y un paso posterior falla (como actualizar un balance). La solución es tratar todo el conjunto de cambios como una unidad de trabajo.
Empieza por elegir el límite: todo lo que debe ser cierto a la vez va dentro de la transacción. Por ejemplo, “crear pedido + reservar inventario + registrar pago” debería ocurrir todo o nada.
Un flujo fiable se ve así:
- Inicia una transacción antes del primer insert/update en la unidad de trabajo.
- Ejecuta las sentencias en un orden seguro (fila padre primero, luego hijos, luego actualizaciones derivadas).
- Tras cada sentencia crítica, verifica que obtuviste lo esperado (conteo de filas, id devuelto, constraints).
- Si algún paso falla, para inmediatamente y haz rollback.
- Confirma (commit) solo cuando cada paso haya tenido éxito, y luego devuelve una única respuesta clara de éxito.
Aquí está la forma en pseudocódigo:
BEGIN;
-- 1) Crear padre
INSERT INTO orders(...) VALUES(...) RETURNING id;
-- 2) Crear hijos
INSERT INTO order_items(order_id, ...) VALUES (...);
-- 3) Actualizar estado derivado
UPDATE inventory SET reserved = reserved + 1 WHERE sku = ? AND available > 0;
COMMIT;
Dos detalles pueden hacer que el patrón falle o funcione.
Primero, no tragues errores. Si el paso 3 actualiza 0 filas, trátalo como fallo, lanza un error y haz rollback.
Segundo, no envíes una respuesta de éxito hasta que el commit haya terminado. “OK” antes del commit es la manera en que el trabajo parcial se filtra como “éxito”.
Si heredaste código generado por IA, fíjate en las transacciones falsas donde cada consulta abre su propia conexión. El código puede parecer transaccional mientras que las consultas se ejecutan en sesiones diferentes.
Manejo de fallos: rutas explícitas de rollback y errores claros
Los datos a medio guardar a menudo vienen de tratar los errores como “problema de otro”. Decide desde el principio qué cuenta como fallo y haz que cada camino de fallo sea obvio en el código.
Haz rollback por más que crashes. Haz rollback por excepciones (timeouts, errores de constraint, deadlocks), verificaciones fallidas (una actualización afecta 0 filas cuando debe afectar 1), validaciones que dependen del estado actual (“el usuario ya tiene una suscripción activa”) o escrituras dependientes que devuelven valores inesperados.
Luego haz el rollback explícito. Evita patrones como “catch e ignorar” o devolver false sin limpieza. Una estructura simple te mantiene honesto:
begin transaction
try:
write A
write B
verify row counts
commit
return success
except error:
rollback
log safe context
return clear failure
finally:
close connection
Los errores claros importan. El llamador debe saber qué hacer después (“por favor reintenta” vs “entrada inválida”), pero el mensaje no debe revelar secretos como texto SQL, tokens o variables de entorno. Un enfoque práctico es una razón corta más un id de error interno que puedas buscar en logs.
Nunca dejes una transacción abierta. Las transacciones abiertas pueden bloquear filas, impedir a otros usuarios y provocar fallos extraños en solicitudes posteriores. Siempre confirma o haz rollback, y siempre cierra la conexión (o devuélvela al pool) en un bloque finally.
Registra lo suficiente para reproducir el problema sin volcar datos privados: nombre de operación (signup, checkout), ids relevantes, conteos de filas y tipo de error. Un fallo común en bases de código generadas por IA es atrapar errores, devolver “éxito” y dejar la base de datos partida entre dos realidades.
Reintentos e idempotencia: mantenerse seguro ante timeouts
Los timeouts crean una situación complicada: el cliente se rinde, pero el servidor puede completar el trabajo y hacer commit. Si el cliente reintenta, puedes crear el mismo pedido dos veces, conceder acceso dos veces o cobrar dos veces.
Las transacciones mantienen cada intento como todo-o-nada, pero no evitan que el mismo intento ocurra de nuevo. Ahí entra la idempotencia.
Idempotencia significa que la misma petición, repetida, produce el mismo resultado. Un patrón común es requerir una clave de idempotencia (un ID aleatorio del cliente) y guardarla con el resultado final. Al reintentar, buscas esa clave y devuelves el resultado original en lugar de ejecutar todo el flujo otra vez.
Formas prácticas de hacer reintentos seguros:
- Añadir constraints únicos que reflejen reglas de negocio reales (un perfil por usuario, una membresía por usuario por workspace).
- Guardar la clave de idempotencia con un índice único y almacenar el ID del registro creado junto a ella.
- Usar upsert cuando encaje con la regla de negocio (crear si falta, si no reutilizar la fila existente).
- Tratar la “violación de constraint único” como un resultado normal de reintento: obtener la fila existente y devolverla.
- Hacer idempotentes también los efectos externos (pagos, correos).
Ejemplo: una petición de checkout hace timeout justo después del commit en la base de datos, pero antes de que la respuesta llegue al navegador. Llega el reintento. Con un constraint único en (user_id, cart_id) y una clave de idempotencia guardada con el payment_intent_id, la segunda petición devuelve el mismo pedido y no crea un segundo cobro.
Consejos de diseño: mantener las transacciones pequeñas y separar efectos secundarios
Las transacciones funcionan mejor cuando cubren una acción de negocio clara. Coloca las reglas clave en el límite: valida lo que debe ser verdad, escribe las filas relacionadas y luego confirma.
Las transacciones largas perjudican porque mantienen locks abiertos. Otras solicitudes se acumulan detrás y los timeouts son más probables. Haz el trabajo mínimo necesario para dejar la base de datos consistente y sal.
Mantén la transacción enfocada
Un error común es tratar una transacción como un “try/catch” general para cualquier cosa que pueda fallar. Mantén trabajo no relacionado fuera.
Reglas prácticas:
- Mete dentro de la transacción solo lecturas y escrituras que deben triunfar juntas.
- Evita llamar a servicios externos mientras la transacción está abierta.
- Evita consultas lentas o actualizaciones en lote grandes en la misma transacción que escrituras que enfrentan usuarios.
- Mantén el flujo de código fácil de razonar (un punto de entrada, un commit).
Separa efectos secundarios de los cambios de datos
Efectos secundarios como enviar correos, cobrar tarjetas, crear archivos o subir imágenes no son trabajo de base de datos. Si los haces dentro de la transacción, arriesgas enviar una confirmación y luego deshacer los datos.
Un patrón más seguro es: escribe los datos, commitea y luego desencadena los efectos. Si necesitas fuertes garantías, escribe un registro “outbox” como parte de la misma transacción (por ejemplo, “enviar correo de bienvenida al usuario 123”). Tras el commit, un worker lee el outbox y realiza el efecto. Si falla, reintentas sin corromper tus registros principales.
Errores comunes que todavía causan datos a medio guardar
Muchas veces los bugs de datos a medio guardar no vienen por falta de transacciones. Ocurren cuando una transacción se usa de forma que rompe silenciosamente la garantía todo-o-nada.
Un error clásico es guardar el registro “principal”, commitear y solo después crear filas relacionadas requeridas (log de auditoría, fila de profile, entrada en tabla de unión). Si el segundo paso falla, te quedas con un registro que parece válido en una tabla pero le faltan sus acompañantes.
Otro problema común es un manejo de errores que omite la limpieza. La transacción puede abrirse correctamente, pero una rama devuelve temprano (o lanza dentro de un callback) sin rollback. Dependiendo del stack, eso puede dejar la conexión en mal estado o causar commits inesperados.
Patrones de fallo que aparecen con frecuencia en código generado por IA:
- Atrapar un error, registrarlo y aun así devolver una respuesta de “éxito”.
- Hacer una llamada a una API de terceros (email, pagos, subida de archivos) mientras la transacción está abierta, de modo que una red lenta mantiene locks.
- Mezclar clientes de base de datos, de modo que una escritura ocurre en otra conexión y no forma parte de la misma transacción.
- Reintentar la petición sin idempotencia, lo que crea duplicados tras un timeout.
Ejemplo: un flujo de signup inserta en users, luego en user_profiles y luego en org_members. Si la inserción del profile falla pero la de user ya se commiteó, el próximo intento de signup puede chocar con “email ya existe” y el usuario queda en limbo.
Dos reglas prácticas previenen mucho de esto: mantén la transacción limitada al trabajo de base de datos y haz explícitos todos los caminos de salida. Si necesitas una llamada externa, commitea primero, luego haz la llamada y, si falla, deja un estado separado “necesita reintento”.
Comprobaciones rápidas antes de subir a producción
Antes de lanzar una funcionalidad que hace inserciones y actualizaciones en varios pasos, escribe la “unidad de trabajo” en una sola frase. Ejemplo: “Crear pedido, reservar inventario y registrar un intento de pago.” Si no puedes decirlo claramente, tus límites de transacción probablemente están difusos.
Una prueba de cordura rápida es seguir la conexión. Cada consulta que deba triunfar o fallar junto tiene que ejecutarse en la misma sesión/conexión de base de datos. Este es un modo frecuente de fallo en código generado por IA: un helper usa una conexión del pool mientras otro abre una nueva, así la transacción solo cubre parte del trabajo.
Un checklist corto antes de subir:
- Define la unidad de trabajo en una frase y envuélvela en una sola transacción.
- Verifica que cada escritura relacionada use el mismo objeto de conexión/sesión desde begin hasta commit.
- Haz los caminos de fallo aburridos: ante cualquier error, rollback una vez, devuelve un error claro y para.
- Añade constraints que hagan seguros los reintentos (claves únicas para “uno por usuario”, claves de idempotencia para peticiones).
- Mantén efectos secundarios fuera de la transacción: envía correos, webhooks y subidas solo después del commit (o encolándolos).
Luego haz una ejecución de “romperlo”: fuerza un error en el paso 2 de 3 (por ejemplo, viola un constraint en la tercera tabla). Tras la petición fallida, comprueba la base de datos. Deberías ver cero filas nuevas, no “algunas filas con piezas faltantes”.
Ejemplo: flujo de signup que escribe en 3 tablas
Imagina un signup que necesita escribir tres filas:
users(email, password_hash)profiles(user_id, display_name)subscriptions(user_id, plan)
Si ejecutas eso como tres escrituras separadas, puedes obtener datos a medio guardar. Por ejemplo, la fila users se crea, pero profiles falla porque display_name es demasiado largo o falta un campo requerido. Ahora tienes una cuenta real que no puede terminar onboarding y futuros reintentos pueden fallar porque el email ya está tomado.
Cómo se ve sin una transacción
Un patrón común generado por IA es: insertar user, luego insertar profile, luego insertar subscription, cada uno en su propia llamada. Cuando el paso 2 falla, el paso 1 ya se commiteó. Ahora necesitas código de limpieza (borrar el usuario) y decidir qué pasa si esa limpieza también falla.
El mismo flujo con transacción y rollback explícito
Con escrituras atómicas, tratas las tres escrituras como una unidad: o las tres existen, o ninguna.
BEGIN;
INSERT INTO users (email, password_hash)
VALUES (:email, :hash)
RETURNING id INTO :user_id;
INSERT INTO profiles (user_id, display_name)
VALUES (:user_id, :display_name);
INSERT INTO subscriptions (user_id, plan)
VALUES (:user_id, :plan);
COMMIT;
-- If any statement fails, ROLLBACK;
Dos reglas hacen esto fiable:
- Solo envía “éxito” al usuario después de que
COMMIThaya sido exitoso. - Si algo lanza, atrápalo,
ROLLBACK, y devuelve un mensaje de error claro.
Acciones posteriores al commit, como correos de bienvenida, deberían ocurrir después del commit (o encolarse), para no enviar un correo a alguien cuya cuenta nunca se guardó realmente.
Para probarlo, añade una falla intencional en el medio (por ejemplo, forzar un display_name inválido) y confirma que la base de datos no contiene filas para ese email después de que la petición falle.
Próximos pasos: arreglar bugs de transacciones en apps construidas por IA
Si heredaste una app generada por herramientas como Lovable, Bolt, v0, Cursor o Replit, los registros a medio guardar suelen señalar límites de transacción faltantes o incompletos. A menudo parece bien en pruebas del camino feliz, pero se rompe bajo tráfico real, timeouts o un valor nulo inesperado.
Signos comunes de que el código carece de una transacción apropiada (o solo la usa a medias):
- Una llamada API escribe en varias tablas, pero cada escritura ocurre en funciones separadas con sus propias llamadas a la base de datos.
- Los errores se atrapan y registran, pero el código sigue adelante y devuelve éxito.
- Jobs en background, correos o llamadas de pago ocurren en medio de escrituras a la DB.
- Un reintento crea filas duplicadas porque no hay idempotencia.
- Ves filas huérfanas (un profile sin user, o un pedido sin items).
Cuando pidas una auditoría de código, no preguntes solo “¿usamos transacciones?” Pregunta dónde empiezan y terminan, y qué pasa en caso de fallo. Una auditoría sólida debe señalar riesgos de integridad de datos (keys foráneas, constraints, escrituras parciales), además de problemas que suelen acompañar al código generado por IA, como flujos de autenticación rotos, secretos expuestos y riesgos de inyección SQL.
Si decides entre refactorizar o reconstruir: refactoriza cuando el modelo de datos esté sano y el flujo solo necesite una frontera de transacción clara y manejo de errores limpio. Reconstruye cuando el flujo esté enmarañado, las tablas no se ajusten al producto o cada arreglo genere un nuevo caso límite.
Si ves datos a medio guardar en una codebase generada por IA, FixMyMess (fixmymess.ai) se centra en diagnosticar el código, reparar la lógica, endurecer la seguridad, refactorizar áreas riesgosas y dejar la app lista para producción. Su auditoría de código gratuita es una forma práctica de localizar el endpoint exacto donde falla la atomicidad y cuál debería ser el comportamiento de rollback más seguro.