Travesía de directorios en endpoints de descarga: cómo detectarla y solucionarla
La travesía de directorios en endpoints de descarga puede exponer archivos privados. Aprende a manejar nombres de archivo de forma segura con listas blancas, rutas canónicas y controles de acceso a nivel de almacenamiento.
Por qué los endpoints de descarga son fáciles de romper
Un endpoint de descarga debería hacer una cosa simple: cuando un usuario autenticado pulsa "Descargar", el servidor encuentra el archivo correcto y lo devuelve (con el nombre de archivo y el tipo de contenido adecuados).
En la práctica, el paso de "encontrar el archivo" es donde las cosas fallan. El error más común es tratar la entrada del usuario como si fuera un nombre de archivo seguro. Un desarrollador toma algo como ?file=invoice.pdf y lo concatena a una carpeta, asumiendo que el usuario solo pedirá sus propios archivos. Los atacantes no piensan en nombres de archivo; piensan en rutas.
Ese es el riesgo principal con la travesía de directorios en endpoints de descarga: un atacante intenta controlar desde dónde lee el servidor, no solo qué documento obtiene. Si tu código construye una ruta a partir de entrada no confiable, una petición puede salir de la carpeta prevista e ir a áreas sensibles.
Cuando eso ocurre, el impacto puede ser mucho mayor que "alguien descarga la factura equivocada". Un atacante puede leer archivos de configuración que revelen credenciales de base de datos o claves API, código fuente (útil para encontrar más fallos), subidas privadas de usuarios y exportaciones, u otros archivos del servidor que le ayuden a mapear tu entorno.
Los endpoints de descarga también son fáciles de romper porque parecen inofensivos. Suelen entregarse al final, reciben menos revisión y "funcionan bien" en pruebas básicas. El fallo solo aparece cuando alguien envía entradas extrañas, rutas codificadas o separadores inesperados.
Cómo aparece la travesía de rutas en peticiones reales
Un endpoint de descarga suele tomar algo de la petición y convertirlo en una ruta de archivo. El fallo aparece cuando el servidor confía en esa entrada. Si el código hace algo como baseDir + "/" + filename, un atacante puede cambiar lo que significa “filename”.
Desde fuera, una petición normal solicita report.pdf. Un atacante prueba cargas que suben directorios o saltan a otra unidad.
Formas comunes de payload incluyen:
../secrets.envo../../../../etc/passwd..\\..\\Windows\\System32\\drivers\\etc\\hosts/etc/passwd(ruta absoluta en Linux)C:\\Windows\\win.ini(ruta absoluta en Windows)- Separadores mixtos como
..\\../..\\config.yml
La codificación hace esto más difícil de detectar en los logs. Muchas apps decodifican parámetros URL antes de validarlos, lo que significa que una cadena bloqueada puede reaparecer tras la decodificación. Los atacantes prueban %2e%2e%2f (que se convierte en ../), o doble codificación como %252e%252e%252f (decodificada dos veces por algunas pilas). También mezclan mayúsculas y separadores, por ejemplo %2E%2E%5C para obtener ..\\.
Un escenario realista: tu endpoint es GET /download?file=invoice-123.pdf. Si el handler usa ese valor directamente, el atacante prueba file=..%2f..%2f.env o file=..\\..\\appsettings.json. Si el archivo existe y tu proceso puede leerlo, el servidor puede devolverlo como una "descarga" sin error obvio.
Las diferencias de plataforma importan lo suficiente como para ser peligrosas. Linux usa típicamente / y distingue mayúsculas. Windows acepta \\, suele tolerar /, soporta letras de unidad y tiene nombres de dispositivo como CON y NUL. Si tu validación solo piensa en un estilo de OS, puede pasar por alto el otro estilo cuando despliegues, o cuando un atacante pruebe bypasses.
Formas rápidas de detectar un manejo inseguro de nombres de archivo
La mayoría de las travesías de directorios en endpoints de descarga empiezan por un error: dejar que la petición decida la ruta que lees del disco. A menudo puedes detectarlo rápidamente trazando de dónde obtiene la ruta la ruta de descarga y dónde se usa esa entrada.
Los signos de riesgo suelen parecerse a esto:
- Un parámetro de query como
file,path,nameodownloadse lee y se pasa aopen(),readFile(),sendFile()o a una función de join de rutas. - El servidor confía en una cabecera (como
X-File,Content-Dispositiono inclusoReferer) para escoger un archivo para servir. - La “sanitización” se hace con trucos de cadenas como
replace("../", "")o recortando puntos, en lugar de forzar una carpeta base segura. - El endpoint construye una ruta a partir de la entrada del usuario y una carpeta base, pero nunca comprueba dónde acaba después de la normalización.
- Las descargas salen directamente del filesystem del servidor aun cuando los archivos podrían almacenarse en otro lugar (object storage, blobs en BD o un servicio de subidas).
Puedes confirmar la sospecha con unas pocas pruebas seguras en un entorno de desarrollo. Si un endpoint acepta un nombre de archivo, prueba valores que nunca deberían funcionar: ../.env, ../../etc/passwd, ..\\..\\windows\\win.ini o variantes codificadas como %2e%2e%2f. Aunque la respuesta sea un error, vigila pistas en los logs (rutas resueltas completas, stack traces o mensajes de error que mencionen directorios reales).
Un patrón común que "parece seguro pero no lo es": el código comprueba que la entrada termina en .pdf y luego la abre. Los atacantes pueden usar trucos de codificación, extensiones dobles u otros casos límite para sortear comprobaciones ingenuas. Incluso si algunos ejemplos antiguos de byte-nulo ya no aplican a tu stack, la lección es la misma: las comprobaciones por sufijo no son una frontera sólida.
Patrón más seguro: usa IDs de archivo y búsqueda en el servidor
La forma más sencilla de evitar la travesía de directorios en endpoints de descarga es dejar de aceptar nombres de archivo en la URL. Los nombres de archivo son problemáticos. Pueden incluir barras, contrabarras, secuencias .. y codificaciones que cambian su significado cuando tu servidor concatena cadenas en una ruta.
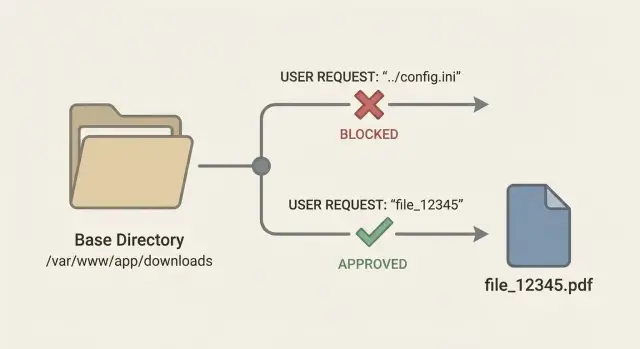
Un patrón más seguro es exponer un ID estable de archivo, por ejemplo GET /download/7f3a2c, y mantener la ubicación real en el servidor. El ID es solo un puntero. Tu app decide a qué archivo corresponde.
Cuando llega una petición, busca el archivo en una tabla de base de datos (o cualquier almacén de confianza) usando ese ID. Guarda metadatos que necesites para tomar una decisión segura: quién es el propietario, cuál es la key de almacenamiento, qué tipo de contenido debe devolver y si sigue siendo válido.
Un flujo simple:
- Aceptar solo un ID opaco (UUID, token aleatorio, ID de BD).
- Obtener metadatos del archivo por ID (propietario, org, storage key, content type).
- Comprobar que el usuario actual está autorizado para acceder a ese registro.
- Descargar por la key de almacenamiento confiable, no por la entrada del usuario.
- Establecer cabeceras de respuesta desde los metadatos almacenados, no desde la petición.
Ejemplo: un cliente pulsa "Descargar factura" y tu UI llama a /download/inv_12345. Tu servidor comprueba que inv_12345 pertenece a la cuenta de ese cliente, luego lee storage_key=accounts/889/invoices/2025-01.pdf. El usuario nunca puede enviar ../../etc/passwd porque no existe un parámetro de nombre de archivo que atacar.
Esto también facilita las auditorías. Puedes revisar una comprobación de autorización alrededor de la búsqueda en lugar de intentar demostrar que cada posible nombre de archivo es seguro.
Listas de permitidos que realmente ayudan (y qué evitar)
Una allowlist solo ayuda si limita descargas a cosas que ya sabes que son seguras. Para descargas, eso suele significar o bien (1) una lista de claves de archivo conocidas que generaste y almacenaste, o (2) una lista corta de tipos de archivo que realmente soportas.
La allowlist más segura es por key almacenada exacta, no por un nombre de archivo proporcionado por el usuario. El usuario envía un ID como fileId=8f3c..., tu servidor consulta el registro almacenado (propietario, ruta del bucket, key de objeto exacta) y sirve eso. El usuario nunca influye en la ruta.
Si debes aceptar nombres de archivo, trata las allowlists de extensiones como un respaldo, no como tu control principal. Valida un conjunto corto (por ejemplo: pdf, csv) y rechaza todo lo demás. No intentes “limpiar” las entradas para hacerlas aceptables. Rechazar es más seguro.
Antes de validar cualquier cosa, normalízala para que los atacantes no se cuelen por las comprobaciones. Manténlo aburrido y consistente: recorta espacios, normaliza mayúsculas si encaja con tu sistema y rechaza separadores de ruta (/ y \\) además de secuencias como ... También vigila nombres engañosos como invoice.pdf.exe o report.pdf .
Qué evitar: listas negras (se pierden variantes), comprobaciones endsWith sobre la entrada cruda y allowlists que aún permiten partes de directorio.
Rutas canónicas: reforzar el límite del directorio base
La regla más segura para descargas es simple: el usuario nunca debería poder elegir una ruta del sistema de archivos. Si debes aceptar algo como un nombre de archivo, conviértelo en una ruta canónica y luego demuestra que sigue dentro de una carpeta aprobada (por ejemplo, downloads_root). Esto cierra el truco clásico de ../.
Canonalizar significa resolver la ruta real que el SO usará. Debe colapsar . y .., normalizar separadores y (si tu plataforma lo soporta) resolver symlinks. Los symlinks importan porque una ruta que parece inocua dentro de tu carpeta de descargas puede apuntar hacia fuera.
Un patrón práctico se ve así:
base = realpath(downloads_root)
requested = realpath(join(downloads_root, user_input))
if requested is null -> error
if not requested starts_with base + separator -> error
serve requested
Antes de canonalizar, rechaza entradas obviamente peligrosas. Reduce casos límite y facilita el registro. Rechazos comunes incluyen rutas absolutas (/etc/passwd, C:\\Windows\\...) y entradas que contienen separadores cuando esperabas un nombre sencillo.
Reglas que aguantan bien:
- Acepta solo entradas relativas (sin
/inicial, sin letras de unidad). - Construye la ruta con funciones de unión seguras, nunca con concatenación de cadenas.
- Canonicaliza a una ruta real y luego verifica que se mantenga bajo
downloads_root. - Si la ruta canónica falla, trátala como bloqueada, no como "prueba otra".
Finalmente, devuelve el mismo error genérico para "no encontrado" y "bloqueado". Si devuelves mensajes distintos, los atacantes pueden sondear qué archivos existen en tu servidor, incluso si no pueden descargarlos.
Controles a nivel de almacenamiento que reducen la superficie de daño
Aunque tengas buenas comprobaciones de entrada, trata tu endpoint de descarga como de alto riesgo. Si la travesía se cuela, las decisiones de almacenamiento determinan si el atacante obtiene un archivo o todo tu servidor.
Evita servir archivos de usuarios desde el mismo disco que tu contenedor de la app. Cuando subidas y código de la app comparten un sistema de archivos, un solo error puede exponer archivos de configuración, claves y código fuente. Mantén los archivos fuera de la raíz web y desactiva el servicio estático directo para ese directorio, de modo que solo tu aplicación pueda leer y devolver archivos.
Para muchos equipos, el object storage es la manera más simple de reducir el riesgo. En lugar de leer rutas locales, guarda archivos como objetos y aplica acceso usando permisos por objeto o accesos firmados de corta duración. Tu app comprueba quién es el usuario, qué ID de archivo solicitó y si lo posee. Solo entonces genera un token de descarga con tiempo limitado o hace proxy del archivo.
Controles que dan resultado rápido:
- Mantén los buckets privados por defecto.
- Prefiere accesos firmados de corta duración sobre URLs públicas permanentes.
- Si debes usar disco local, guarda archivos fuera de la raíz web.
- Ejecuta la app con permisos mínimos en el sistema de archivos (solo lectura donde sea necesario).
- Separa entornos y buckets (dev vs prod).
El registro importa tanto como el bloqueo. Para cada petición de descarga, registra el ID de usuario, el ID de archivo y la decisión (permitido o bloqueado), más un código de razón como "no propietario" o "token expirado". Ese rastro de auditoría te ayuda a detectar sondeos y demuestra qué pasó.
Errores comunes y bypasses que usan los atacantes
La mayoría de las correcciones fallan porque el código asume que el atacante enviará un simple ../. Los ataques reales son por capas y están diseñados para eludir la comprobación que hayas añadido.
Un error clásico es confiar en reglas del lado cliente o campos ocultos en formularios. Si tu UI solo permite seleccionar de un dropdown, pero el servidor todavía acepta un parámetro path, un atacante puede cambiar ese valor en la petición. El servidor tiene que comportarse como si la UI no existiera.
Los trucos de codificación son otro bypass frecuente. Los equipos decodifican una vez, validan, y más tarde algún framework o proxy decodifica de nuevo. Eso puede convertir una cadena aparentemente segura en ../ después de la validación. La solución es consistencia: normaliza y valida en un único lugar, y asegúrate de que el valor que usas para abrir el archivo sea exactamente el valor que validaste.
Las comprobaciones por extensión son fáciles de engañar. Bloquear todo menos .pdf suena seguro, pero los atacantes aún pueden atravesar a carpetas sensibles y obtener archivos que casualmente terminen en .pdf, o abusar de segmentos extra si tu manejo de rutas es descuidado. Si la intención es servir solo facturas, la ruta no debería estar controlada por el usuario.
Bypasses que aparecen a menudo:
- Rutas ocultas o generadas por el cliente tratadas como entrada confiable
- Decodificación en capas diferentes (app, framework, proxy)
- Comprobaciones tipo "Permitir .pdf solo" que ignoran directorios y segmentos
- Symlinks dentro de una carpeta permitida que apuntan fuera de ella
- Zip Slip: extraer un archivo que contiene rutas
../y escribir fuera de la carpeta objetivo
Los symlinks merecen atención especial. Incluso si unes una carpeta base con un nombre de archivo, un symlink colocado dentro de esa carpeta puede saltar el límite. La solución fiable son comprobaciones de ruta canónica (tras resolver symlinks) más permisos estrictos en el sistema de archivos.
Lista de comprobación rápida antes de lanzar una función de descarga
Los endpoints de descarga parecen simples, pero son una vía común por la que la travesía llega a producción. Unas pocas decisiones pequeñas (como aceptar un nombre de archivo en la URL) pueden convertir una descarga normal en "leer cualquier archivo del servidor".
Enfoque por defecto más seguro
Empieza por decidir qué puede pedir el usuario. Los usuarios deberían solicitar un archivo por un ID que tú controles, no por una ruta que puedan formar.
- Entrada: acepta solo un ID de archivo (o número de factura), nunca una ruta o nombre de archivo crudo.
- Búsqueda: mapea ese ID a un registro almacenado que contenga la key de almacenamiento real o la ruta absoluta del servidor.
- Validación: si debes manejar nombres, usa una allowlist estricta (extensiones esperadas, caracteres permitidos), luego canonicaliza y confirma que el resultado se mantiene dentro de tu directorio base.
- Autorización: comprueba la propiedad y el rol antes de leer el archivo, no después.
- Respuesta: establece cabeceras seguras y evita reflejar la entrada del usuario en
Content-Dispositionsin limpiarla.
Reduce la superficie con almacenamiento y pruebas
Almacenamiento privado por defecto te salva cuando el código falla. Mantén los archivos descargables fuera de la raíz web y evita buckets públicos donde adivinar un nombre sea suficiente.
Una prueba práctica rápida: intenta pedir secuencias ../, variantes URL-codificadas y barras extra contra tu ruta de descarga. Los intentos bloqueados deberían registrarse con detalle suficiente para depurar (ID de usuario, ID solicitado, razón de bloqueo), pero sin secretos.
Ejemplo: descargas de facturas que exponen archivos del servidor
Un fundador lanza rápido una función de facturas: los clientes hacen click y la app llama a un endpoint como /download?filename=invoice-1042.pdf. El servidor toma filename, construye una ruta, lee el archivo y lo devuelve.
Funciona en pruebas porque todos piden archivos normales. El problema es que el servidor confía en la entrada del usuario para escoger un archivo. Un atacante puede cambiar el parámetro a ../../.env o ../../../etc/passwd. Si el código concatena cadenas (o decodifica valores URL y luego concatena), la app puede leer archivos fuera de la carpeta de facturas.
Un plan de arreglo que mantiene la función pero elimina el riesgo:
- Cambiar de nombres de archivo a IDs de archivo (ejemplo:
/download?id=inv_1042) y buscar la ruta real en el servidor. - Aplicar comprobaciones de autenticación y propiedad para que solo el cliente correcto pueda descargar su factura.
- Almacenar facturas en almacenamiento privado (no en una carpeta pública) y servirlas mediante descargas controladas.
- Añadir allowlists simples: permitir solo formatos de factura conocidos (como PDF) y rechazar todo lo demás.
- Registrar peticiones denegadas para detectar intentos de sondeo temprano.
Para confirmar que está solucionado, no te fíes de "parece bien". Compruébalo:
- Intenta payloads
../y verifica que siempre devuelves un error genérico. - Revisa logs para confirmar que los patrones de travesía fueron bloqueados y registrados.
- Añade un test automatizado que intente
../../.envy espere una denegación.
Próximos pasos: audita tus endpoints y arregla rápido
Asume que tienes más de una ruta de "descarga". En muchas apps, los archivos se sirven desde varios sitios: una ruta de facturas, una ruta de exportación, una vista previa de adjuntos y, a veces, un helper de depuración que accidentalmente se despliega.
Una auditoría práctica:
- Lista cada endpoint que devuelve un archivo (download, export, report, image, attachment, backup).
- Traza de dónde obtiene cada uno su nombre o ruta (query, parámetro de ruta, cuerpo JSON, cabeceras, base de datos).
- Anota cada ubicación de almacenamiento en uso (directorios en disco local, carpetas temporales, mounts de red, buckets de object storage).
- Busca construcciones de rutas y lecturas de archivos (
join,resolve,open,readFile,sendFile, creación de zip). - Comprueba las comprobaciones de acceso: quién puede pedir qué archivo y cómo se hace cumplir ese mapeo.
Una vez conozcas la superficie, haz un pase de remediación focalizado. Prefiere IDs de archivo con una búsqueda server-side (ID -> ruta almacenada) en lugar de dejar que la entrada del usuario influya en una ruta del filesystem. Añade validación de ruta canónica para imponer un único límite de directorio para cualquier acceso a disco restante, y usa una allowlist estricta de nombres solo para archivos verdaderamente estáticos.
Termina con pruebas que demuestren que la corrección se mantiene:
- Peticiones con
../y variantes URL-codificadas son rechazadas. - Rutas absolutas (Unix y Windows) son rechazadas.
- Casos límite con symlinks no pueden escapar del directorio base.
- Solo se pueden descargar archivos que pertenezcan al usuario u organización actual.
Si heredaste una base de código generada por IA, merece la pena una segunda revisión en las rutas que sirven archivos. FixMyMess (fixmymess.ai) se centra en diagnosticar y reparar apps generadas por IA, y una auditoría rápida puede sacar a la luz problemas como manejadores de descarga inseguros, comprobaciones de auth rotas, exposición de secretos y patrones de almacenamiento arriesgados antes de que lleguen a producción.
Preguntas Frecuentes
What is path traversal in a download endpoint?
Un endpoint de descarga se vuelve riesgoso cuando convierte datos controlados por el usuario en una ruta de archivo en disco. Si tu código hace algo como “carpeta base + entrada del usuario”, un atacante puede probar ../ o variantes codificadas para escapar del directorio previsto y leer otros archivos accesibles por el proceso.
What can attackers actually get if path traversal works?
Si un atacante puede leer archivos fuera de la carpeta de descargas, puede obtener archivos de configuración que contienen secretos, el código fuente de la aplicación, subidas privadas, exportaciones u otros archivos del servidor. El daño real suele ser el acceso posterior, por ejemplo usar credenciales filtradas para acceder a la base de datos o servicios externos.
How do I quickly spot unsafe filename handling in my code?
Busca cualquier ruta que lea file, path, name o similares desde una query, parámetro de ruta, cuerpo JSON o cabecera y luego lo pase a APIs de archivos como open, readFile o sendFile. Trata como señal de alarma las “sanitizaciones” basadas en cadenas como replace("../", ""), porque normalmente no manejan codificaciones ni casos límite.
Why doesn’t blocking "../" in a string check fix it?
Porque los atacantes raramente envían ../ en claro. Usan codificación URL, doble codificación, separadores mezclados y rutas específicas de la plataforma, de modo que la cadena peligrosa puede aparecer solo después de la decodificación o normalización dentro de tu pila.
What’s the safest design for a download endpoint?
Por defecto, usa un ID opaco en la URL y haz una búsqueda en el servidor del key de almacenamiento o la ruta real. El usuario debería pedir “archivo 123” y la aplicación decidir dónde vive ese archivo y si el usuario actual puede acceder a él.
Are extension allowlists like “only .pdf” enough?
No de forma fiable. Una comprobación como “debe terminar en .pdf” no evita la travesía de directorios y no impide que alguien descargue un PDF sensible que exista en otra parte del servidor. Usa comprobaciones de extensión solo como una guardia adicional después de remover el control del usuario sobre las rutas.
What does “canonical path” checking mean in practice?
Resuelve la ruta solicitada a una ruta canónica (real) y luego verifica que todavía esté dentro de un único directorio base aprobado. Si la ruta canónicaizada escapa ese límite, bloquéala y devuelve un error genérico para que los atacantes no puedan sondear qué archivos existen.
Why do Windows vs Linux differences matter for validation?
Son formatos de ruta diferentes que pueden evitar validaciones diseñadas para otro estilo. Windows acepta backslashes, tolera forward slashes, tiene letras de unidad y nombres de dispositivo especiales; Linux usa / y suele ser case-sensitive. Si validas solo para un entorno, puedes perderte bypasses reales.
How can storage choices reduce the damage if a bug slips through?
No almacenes archivos descargables por usuarios en la misma área del sistema de archivos que el código y los secretos si puedes evitarlo. Prefiere almacenamiento de objetos privado con tokens de acceso de corta duración o proxyado desde el servidor, y ejecuta la app con permisos de lectura mínimos para que un fallo no exponga toda la máquina.
What should I log and monitor for download endpoints?
Registra la identidad del usuario, el ID de archivo (o el valor solicitado) y si fue permitido o bloqueado con un código de motivo sencillo, pero no registres rutas resueltas completas ni contenidos con secretos. Si heredaste código generado por IA y sospechas rutas de servicio de archivos riesgosas, FixMyMess puede hacer una auditoría rápida y arreglar manejadores de descarga inseguros, comprobaciones de autenticación y problemas de exposición de secretos.